20 | 内存模型和atomic:理解并发的复杂性




讲述:吴咏炜
时长18:12大小16.67M
C++98 的执行顺序问题
双重检查锁定
volatile
C++11 的内存模型
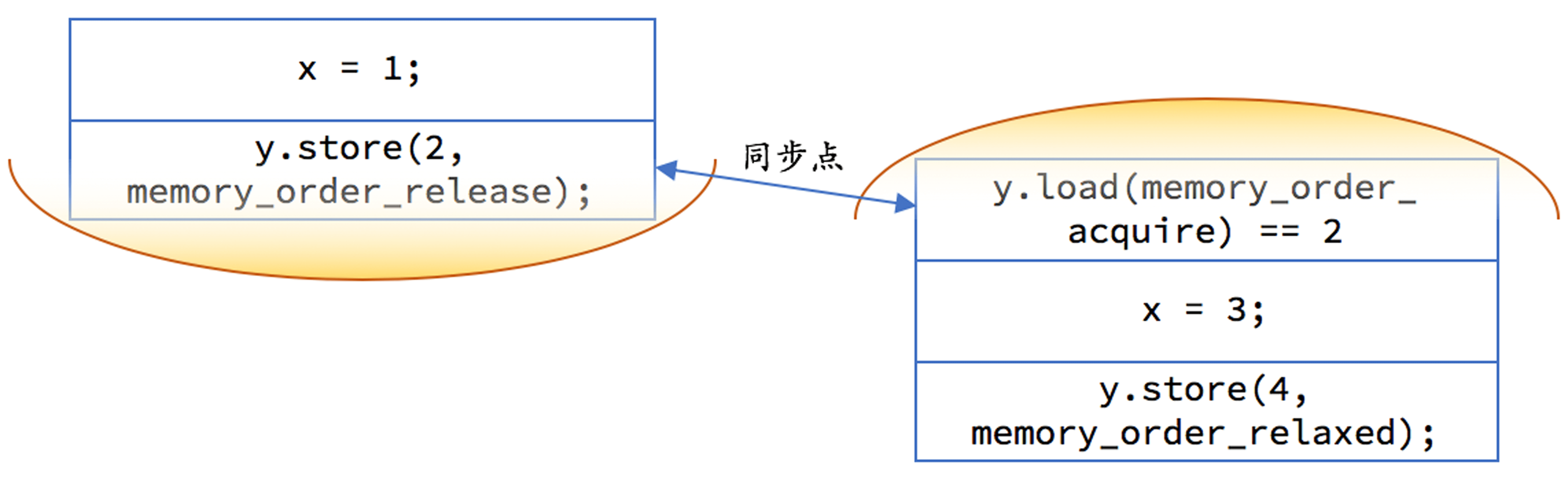
内存屏障和获得、释放语义
atomic
is_lock_free 的可能问题
mutex
并发队列的接口
内容小结
课后思考
参考资料

精选留言(10)
- 2020-01-12您好,看了这篇后,对互斥量和原子量的使用 有些不明白,什么时候应该用互斥量,什么时候用原子量,什么时候一起使用?展开
作者回复: 用原子量的地方,粗想一下,你用锁都可以。但如果锁导致阻塞的话,性能比起原子量那是会有好几个数量级的差异了。锁即使不导致阻塞,性能也会比原子量低——锁本身的实现就会用到原子量,是个复杂的复合操作。
反过来不成立,用互斥量的地方不能都改用原子量。原子量本身没有阻塞机制,没有保护代码段的功能。 1  2020-01-13https://en.cppreference.com/w/cpp/atomic/memory_order最后一段讲解
2020-01-13https://en.cppreference.com/w/cpp/atomic/memory_order最后一段讲解
memory_order_seq_cst提到,如果要保证最后的断言"assert(z.load() != 0);"不会发生,必须使用
memory_order_seq_cst,这里很不理解。
下面是代码
#include <thread>
#include <atomic>
#include <cassert>
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
void write_x()
{
x.store(true, std::memory_order_seq_cst);
}
void write_y()
{
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y()
{
while (!x.load(std::memory_order_seq_cst))//@1
;
if (y.load(std::memory_order_seq_cst)) {//@2
++z;
}
}
void read_y_then_x()
{
while (!y.load(std::memory_order_seq_cst))
;//@3
if (x.load(std::memory_order_seq_cst)) {//@4
++z;
}
}
int main()
{
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
assert(z.load() != 0); // will never happen
}
把代码全部改成memory_order_acq_rel操作为什么不可以?
按照memory_order_acq_rel的描述,在其他线程中,@2的所有操作应该都不会被重排到@1之前,
@4的操作也不会被重排到@3之前,
那如果是这样的话,也能确保断言永远不会发生。展开作者回复: memory_order_seq_cst 不是拿来和 memory_order_acq_rel 对比的,而是和 memory_order_relaxed 对比的。正如我在另外一个回答里说的,这里使用 memory_order_acq_rel 可能是非法的。比如 load,只能使用 relaxed、acquire 和 seq_cst,并且后两者是等价的。
1 2020-01-12is_lock_free,判断对原子对象的操作是否无锁(是否可以用处理器的指令直接完成原子操作)
2020-01-12is_lock_free,判断对原子对象的操作是否无锁(是否可以用处理器的指令直接完成原子操作)
#1
这里的处理器的指令指的是,
“lock cmpxchg”?
#2
“是否可以用处理器的指令直接完成原子操作”, 这里的直接指的是仅使用“处理器的指令吗?
#3
能麻烦给个is_not_lock_free的对原子对象的操作的大概什么样子吗?
谢谢!展开作者回复: #1
不一定。比如,对于 store,生成可能就只是 mov 指令加个 mfence。
#2
是。
#3
你可以对比一下编译器生成的汇编代码:
https://godbolt.org/z/UHsDRj 2- 2020-01-12
void add_count() noexcept
{
count_.fetch_add(
1, std::memory_order_relaxed);
}
void add_count() noexcept
{
count_.fetch_add(
1, std::memory_order_seq_cst);
}
std::memory_order_seq_cst 比std::memory_order_relaxed,
性能方面的浪费,具体指的是什么?
谢谢!展开作者回复: 好问题。这个问题我之前没细究,但现在仔细一看,常见架构上内存序参数对 fetch_add 是没影响的……似乎读-修改-写操作里,一般都是实现成顺序一致的。
也有例外,如 Power、Raspbian Buster、RISC-V:
https://godbolt.org/z/Du85RX 1 - 2020-01-12这一节讲的实在是太好了,我对前几节的编译器模版相关的不是很感冒,要是能把这期更深入的细节探讨一下,多做几节,就更好了。
singleton* singleton::instance()
{
@a
if (inst_ptr_ == nullptr) {//@1
@b
lock_guard lock; // 加锁
if (inst_ptr_ == nullptr) {
@c
inst_ptr_ = new singleton();//@2
@d
}
}
return inst_ptr_;
}
有个问题,就是对double check那个例子的疑惑,会出现什么问题?
inst_ptr_应该就两种状态,null和非null。
如果线程1在@b处,等待锁,这个时候线程2不管在@c或者@d处,线程a获得锁的时候,都不会进入@c,因为inst_ptr已经非空。
如果线程1在@a处,线程2在@2处,执行new操作,难道@2这个语句有什么问题吗,难道@2不是一个原子操作,会导致线程1已经得到线程2分配的对象地址,而内存还没有准备好吗?如果是这种情况的话,
那么下面加入了原子操作后,也没有解决new问题啊,
singleton* singleton::instance()
{
singleton* ptr = inst_ptr_.load(
memory_order_acquire);
if (ptr == nullptr) {
lock_guard<mutex> guard{lock_};
ptr = inst_ptr_.load(
memory_order_relaxed);
if (ptr == nullptr) {
ptr = new singleton();
inst_ptr_.store(
ptr, memory_order_release);
}
}
return inst_ptr_;
}展开作者回复: 看参考资料4吧。如果嫌太长,就只看代码,编译器和处理器眼里允许重排成的样子。
简单说,就是赋值顺序的问题。至少在某些处理器上,其他线程可能先看到 inst_ptr_ 被修改,再看到单件的构造完成。 1 - 2020-01-12介绍memory_order_seq_cst时,说这是所有原子操作的默认内存序,但是在文章前面又说
y = 2 相当于 y.store(2, memory_order_release)
y == 2 相当于 y.load(memory_order_acquire) == 2
?
有点凌乱,这里。展开作者回复: 别漏了前面那几句:
「`memory_order_seq_cst`:顺序一致性语义,对于读操作相当于获取,对于写操作相当于释放」 3 - 2020-01-12memory_order_acq_rel只能作用到读取-修改-写操作吗,貌似单纯的读或者写操作也可以用这个order.
那这个order和seq_cst貌似并没有很大的区别,
不明白这两个order的不止区别是什作者回复: 按标准的规定,store 只能用 relaxed、release 或 seq_cst,load 只能用 relaxed、acquire 或 seq_cst,等等。其他组合在标准中明确说是未定义行为,就算能过也有点凑巧,不保证换个编译器或甚至换个版本还能继续工作。
不要这么做。  2020-01-11C++真是博大精深展开
2020-01-11C++真是博大精深展开作者回复: 计算的世界真是复杂。C++是为了性能,让你能够看到这些复杂性而已。对性能没那么关注的,可以把这些复杂性隐藏掉。
 2020-01-10感觉这里的无锁操作就像分布式系统里面谈到的乐观锁,普通的互斥量就像悲观锁。只是CPU级的乐观锁由CPU提供指令集级别的支持。
2020-01-10感觉这里的无锁操作就像分布式系统里面谈到的乐观锁,普通的互斥量就像悲观锁。只是CPU级的乐观锁由CPU提供指令集级别的支持。
内存重排会引起内存数据的不一致性,尤其是在多CPU的系统里。这又让我想起分布式系统里讲的CAP理论。
多线程就像分布式系统里的多个节点,每个CPU对自己缓存的写操作在CPU同步之前就造成了主内存中数据的值在每个CPU缓存中的不一致,相当于分布式系统中的分区。
我大概看了参考文献一眼,因为一级缓存相对主内存速度有数量级上的优势,所以各个缓存选择的策略相当于分布式系统中的可用性,即保留了AP(分区容错性与可用性,放弃数据的一致性),然后在涉及到缓存数据一致性问题上,相当于采取了最终一致性。
其实我觉得不论是什么系统,时间颗足够小的话,都会存在数据的不一致,只是CPU的速度太快了,所以看起来都是最终一致性。在保证可用性的时候,整个程序的某个变量或内存中的值看起来就是进行了重排。
分布式系统中将多个节点解耦的方式是用异步、用对列。生产者把变化事件写到对列里就返回,然后由消费者取出来异步的实施这些操作,达到数据的最终一致性。
看资料里,多CPU同步时,也有在CPU之间引入对列。当需要“释放前对内存的修改都在另一个线程的获取操作后可见”时,我的理解就是用了所谓的“内存屏障”强制让消费者消费完对列里的"CPU级的事物"。所以才会在达到严格内存序的过程中降低了程序的性能。
也许,这个和操作系统在调度线程时,过多的上下文切换会导致系统性能降低有关系。展开作者回复: 思考得挺深入,很好。👍
操作系统的上下文切换和内存序的关系我略有不同意见。内存屏障的开销我查下来大概是 100、200 个时钟周期,也就是约 50 纳秒左右吧。而 Linux 的上下文切换开销约在 1 微秒多,也就是两者之前的性能差异超过 20 倍。因此,内存屏障不太可能是上下文切换性能开销的主因。
上下文切换实际需要做的事情非常多,那应该才是主要原因。- 2020-01-10Preshing
“In particular, each processor is allowed to delay the effect of a store past any load from a different location. “
这里的”delay”指的是1已经被写到X_cpu_cache, 但是还没有没到推送到X_memeory?
#1
X = 1;
asm volatile("" ::: "memory"); // Prevent memory reordering
r1 = Y;
上面的代码,能确保cpu会先执行store,(至少先写到X_cpu_cache,无法保证1被推送到X_memory),然后再read?
#2
X = 1;
asm volatile("mfence" ::: "memory");
r1 = Y;
上面的代码,能确保cpu会先执行store(包括把1写到X_cpu_cache,再推送至X_memoery), 然后再read?
上面的代码,cpu 执行到mfence时,会确保1从X_cpu_cache推送到X_memory, 然后再去读Y?
谢谢!展开作者回复: delay部分和第二个问题的回答是“是”。
第一个问题你这么说似乎也对,但这个asm语句的主要目的是防止编译器做出任何重排,而没有对处理器提出要求。结果是会跟你说的一样。