06 | Paxos算法(二):Multi-Paxos不是一个算法,而是统称





讲述:于航
时长10:08大小8.13M
兰伯特关于 Multi-Paxos 的思考
领导者(Leader)
优化 Basic Paxos 执行
Chubby 的 Multi-Paxos 实现
内容小结
课堂思考

精选留言(15)
 HuaMax 置顶2020-02-24“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段”这个优化机制。
HuaMax 置顶2020-02-24“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段”这个优化机制。
请问,什么样是稳定状态?为什么稳定状态可以省掉准备阶段?作者回复: 如何理解领导者处于稳定状态?
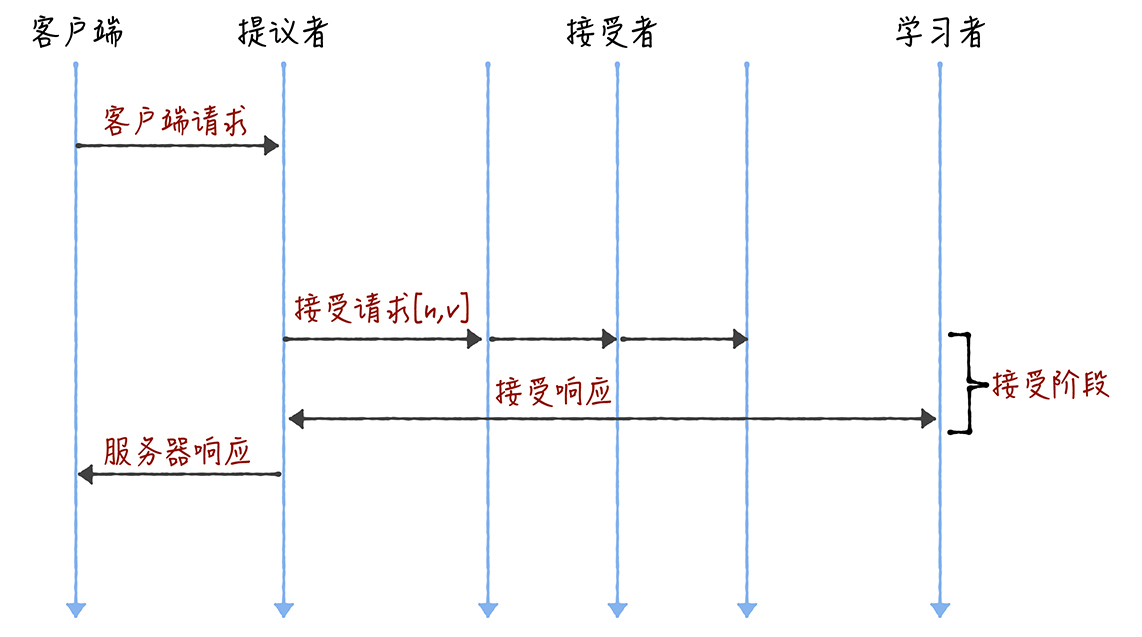
领导者节点上,序列中的命令是最新的,不再需要通过准备请求来发现之前被大多数节点通过的提案,领导者可以独立指定提案中的值。
我来具体说说,准备阶段的意义,是发现接受者节点上,已经通过的提案的值。如果在所有接受者节点上,都没有已经通过的提案了,这时,领导者就可以自己指定提案的值了,那么,准备阶段就没有意义了,也就是可以省掉了。 1 每天晒白牙 置顶2020-02-24只能在主节点进行读操作,效果相当于单机,对吞吐量和性能有所影响
每天晒白牙 置顶2020-02-24只能在主节点进行读操作,效果相当于单机,对吞吐量和性能有所影响
写也是在主节点进行,性能也有问题展开作者回复: 加一颗星:)
 2020-02-24本来想问个问题,看到思考题提到了。
2020-02-24本来想问个问题,看到思考题提到了。
从raft和zab的实现来看,一致性读操作的处理和写操作是类似的,不从本地读,而是也要发请求到所有节点,得到大多数节点的响应才行。我了解到的有的实现是领导者发送一个空操作给所有节点。
这样做的原因不光是考虑吞吐量的问题,而是读本地是满足不了强一致性的,因为自以为的leader未必是真的leader,此时可能另外的节点已经自己组成一个小团队,选出一个新leader,这个变量也可能都更新好几次了。只有和大多数节点交互一次才能知道自己当前还是不是leader。
有个问题,兰伯特提到的 “当领导者处于稳定状态时...”这个稳定状态是什么意思呢?在领导者是谁这个问题上,达成大多数节点的一致?展开作者回复: 领导者节点上,序列中的命令是最新的,不再需要通过准备请求来发现之前被大多数节点通过的提案,领导者可以独立指定提案中的值。
我来具体说说,准备阶段的意义,是发现接受者节点上,已经通过的提案的值。如果在所有接受者节点上,都没有已经通过的提案了,这时,领导者就可以自己指定提案的值了,那么,准备阶段就没有意义了,也就是可以省掉了。 1 2020-02-24老师好,想问下,如果只有领导者可以发起提案,那么这是不是就退化为串行操作了,这样的话性能怎么保证呢,实际应用中是怎么解决的?我觉得最后问题, Chubby只能在主节点上执行读操作,在读请求量非常大的情况下,也是会遇到瓶颈的,还有就是单点问题,主节点挂了,在选出主节点之前就不能提供服务了对吧,该如果解决这类问题呢?展开 2 1
2020-02-24老师好,想问下,如果只有领导者可以发起提案,那么这是不是就退化为串行操作了,这样的话性能怎么保证呢,实际应用中是怎么解决的?我觉得最后问题, Chubby只能在主节点上执行读操作,在读请求量非常大的情况下,也是会遇到瓶颈的,还有就是单点问题,主节点挂了,在选出主节点之前就不能提供服务了对吧,该如果解决这类问题呢?展开 2 1- 2020-02-24Chubby的局限可能在于高读的系统中,如果读请求过大,会导致系统的不可用。另外在系统中如何能够将主节点更替的信息向用户传播也是需要考虑的问题。
还有有一种情况我没有想清楚,请各位指点:
一个分布式系统中有5个节点,3个在一个机房A(机器编号A1,A2,A3),2个在另一个机房B(机器编号B1,B2)。 1)如果节点A1的机架网络发生故障,导致A1与其他节点通信受阻,那么A1节点将会执行什么操作呢?通讯恢复以后A1节点如何进行数据同步呢?同样在A1无法通讯后出现集群有偶数节点,选举时会出现怎样的情况? 2)如果主节点为B1,A机房与B机房间通讯产生故障,A机房和B机房的节点将分别执行怎样的操作呢?展开 1 1  2020-02-25leader怎么确定acceptor的总数呢?集群是允许扩容的吗
2020-02-25leader怎么确定acceptor的总数呢?集群是允许扩容的吗作者回复: 怎么确定acceptor总数,涉及代码实现和成员变更;扩容涉及到成员变更。
首先,使用什么数据结构来保存acceptor总数,这属于编程实现,不属于算法了,绝大多数算法都不会约定的这么细的。
其次,Multi-Paxos,只是一种思想,缺少算法细节和编程所必须的细节,比如,成员变更,在Multi-Paxos中,提了下,可以把服务器配置作为指令,通过状态机提交,等等。但是,如果学习了09讲后,你就会发现,真正实现起来,比这个要复杂很多,比如Raft设计了2种成员变更方法,一种难以实现,一种容易实现,但在16年时,爆出了一个算法bug,虽然很快就修复了,但也反映了成员变更比较复杂,不是三言两语能讲清楚的。
另外,其实,学习Multi-Paxos的最好的方式,是先理解Raft,再回过头来,学习Multi-Paxos。如果在学习Multi-Paxos中遇到不理解的,可以在学习完Raft后,再回头来研究学习。- 2020-02-25看了下微信的PhxPaxos实现文章,确定多个值是通过多组paxos实例完成的,这篇文章好像没提高,到底是多组实例还是一组实例呢?展开
作者回复: 多个值,更确切的说,是一系列值,是需要多次执行Basic Paxos实例的,文中也反复提到了哈。
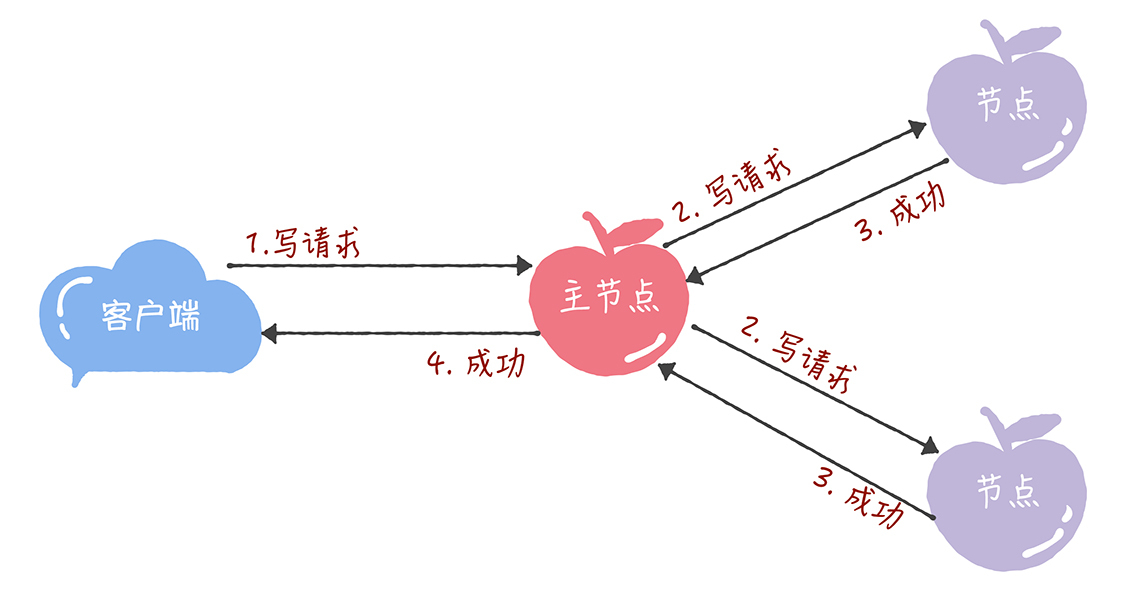
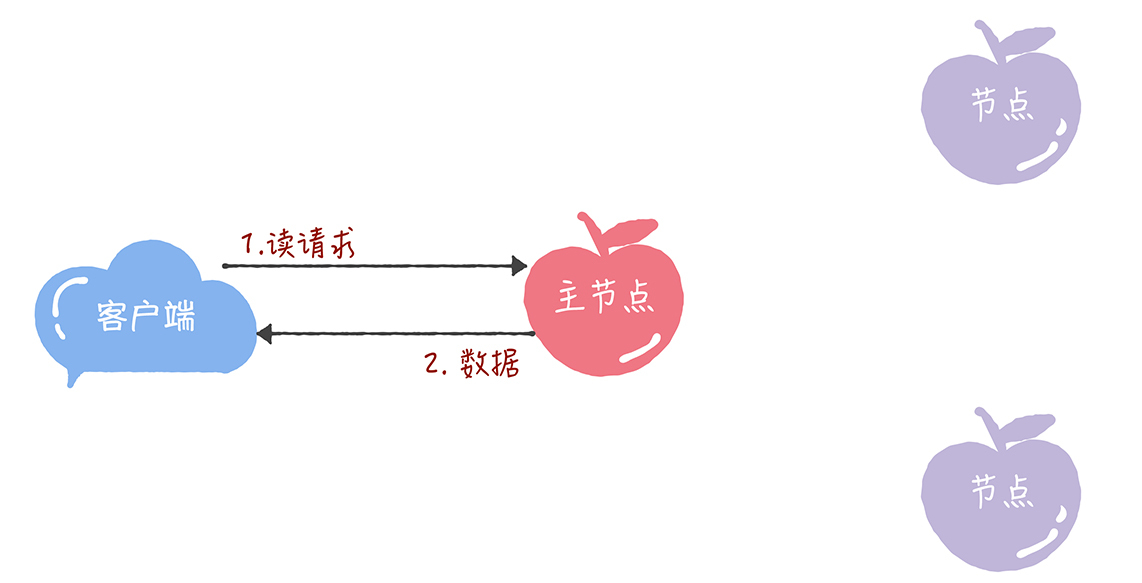
 2020-02-24Chubby 只能在主节点上执行读写操作, 那么这个主节点就是热点,所有的请求都要经过它,显而易见它就是系统的瓶颈,影响系统的并发度,而且在并发时,写请求会block读请求,影响整个系统的QPS。
2020-02-24Chubby 只能在主节点上执行读写操作, 那么这个主节点就是热点,所有的请求都要经过它,显而易见它就是系统的瓶颈,影响系统的并发度,而且在并发时,写请求会block读请求,影响整个系统的QPS。作者回复: 加一颗星:)
 2020-02-24老师你好!
2020-02-24老师你好!
1. 领导者处于稳定状态是指当前只有一个领导者吗?
2. BasicPaxos只能就一个值达成一致 那么能详细讲讲MultiPaxos是怎么让一系列值打成一致的吗? 2020-02-24您好,假设有3台节点 A, B, C. leader 最开始是A, 依次执行写入操作[set x=1, set y=2, set z=3], 假设B和C都有可能超时,根据paxos只需要大多数写入成功就算执行成功的原则,当前状态可能为A:[x:1, y:2, z:3], B:[x:1, z:3], C: [y2, z3]。如果这个时候主节点A宕机,如何重新选择主节点并恢复数据呢?展开
2020-02-24您好,假设有3台节点 A, B, C. leader 最开始是A, 依次执行写入操作[set x=1, set y=2, set z=3], 假设B和C都有可能超时,根据paxos只需要大多数写入成功就算执行成功的原则,当前状态可能为A:[x:1, y:2, z:3], B:[x:1, z:3], C: [y2, z3]。如果这个时候主节点A宕机,如何重新选择主节点并恢复数据呢?展开 2020-02-24“如果多个提议者同时提交提案,可能出现因为提案冲突,在准备阶段没有提议者接收到大多数准备响应,协商失败,需要重新协商。”
2020-02-24“如果多个提议者同时提交提案,可能出现因为提案冲突,在准备阶段没有提议者接收到大多数准备响应,协商失败,需要重新协商。”
根据上文的介绍,接受者会接受提案编号最大的提案吧?展开 1 2020-02-24局限在于读写都是在主节点进行,性能相当于单机。假设主节点down机,需要重新选取主节点,此时如果发生大量读写请求,性能问题突显,可能会导致系统不可用,写请求可能丢失。
2020-02-24局限在于读写都是在主节点进行,性能相当于单机。假设主节点down机,需要重新选取主节点,此时如果发生大量读写请求,性能问题突显,可能会导致系统不可用,写请求可能丢失。 2020-02-24Chubby 只能在主节点上执行读操作,这个设计导致高并发情况下读操作的吞吐量受到限制,影响系统的可用性,但是保证了读数据一致性问题。展开
2020-02-24Chubby 只能在主节点上执行读操作,这个设计导致高并发情况下读操作的吞吐量受到限制,影响系统的可用性,但是保证了读数据一致性问题。展开 2020-02-24只能在主节点上执行读操作,有什么缺陷呢?
2020-02-24只能在主节点上执行读操作,有什么缺陷呢?
这样就相当于单机CA了,在大量读取操作时候,可能会使leader挂掉,导致服务不可用。
要解决这个问题,就得写的时候由leader进行提交。读的时候由所有节点都可以响应。展开- 2020-02-24如果直接通过多次执行 Basic Paxos 实例来达到共识有两个问题
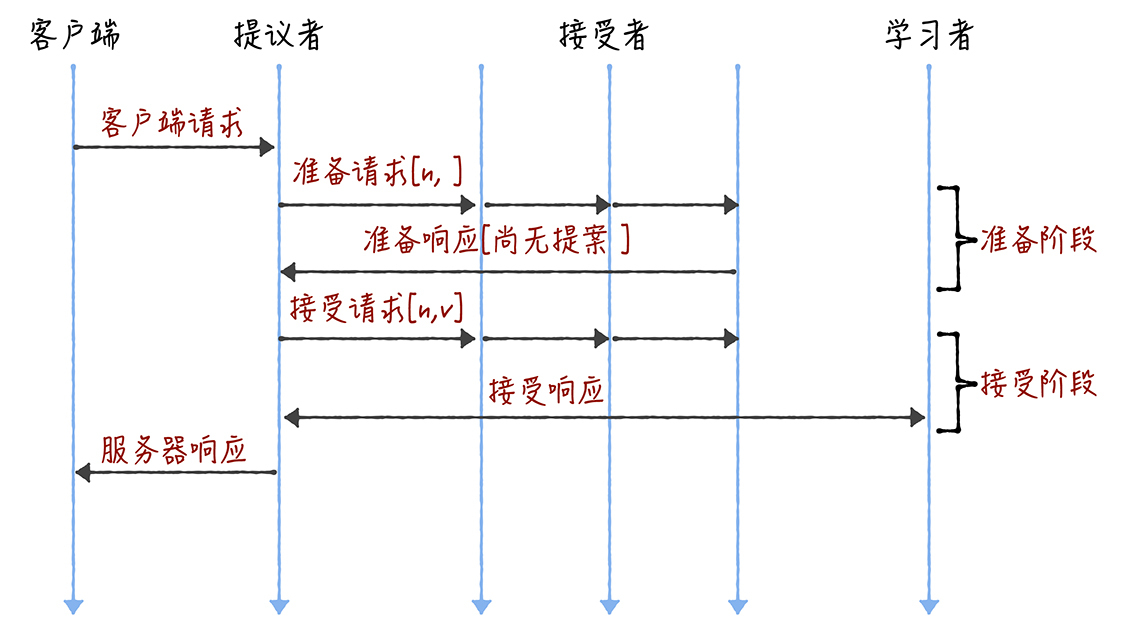
1.如果多个提议者同时提交提案,可能出现因为提案冲突,在准备阶段没有提议者收到大多数准备响应,协商失败,这样就需要重新协商
2.因为准备阶段和接受阶段会进行两轮RPC通讯,往返消息多,耗性能,延迟大,这是需要优化的
那如何解决这两个问题呢?
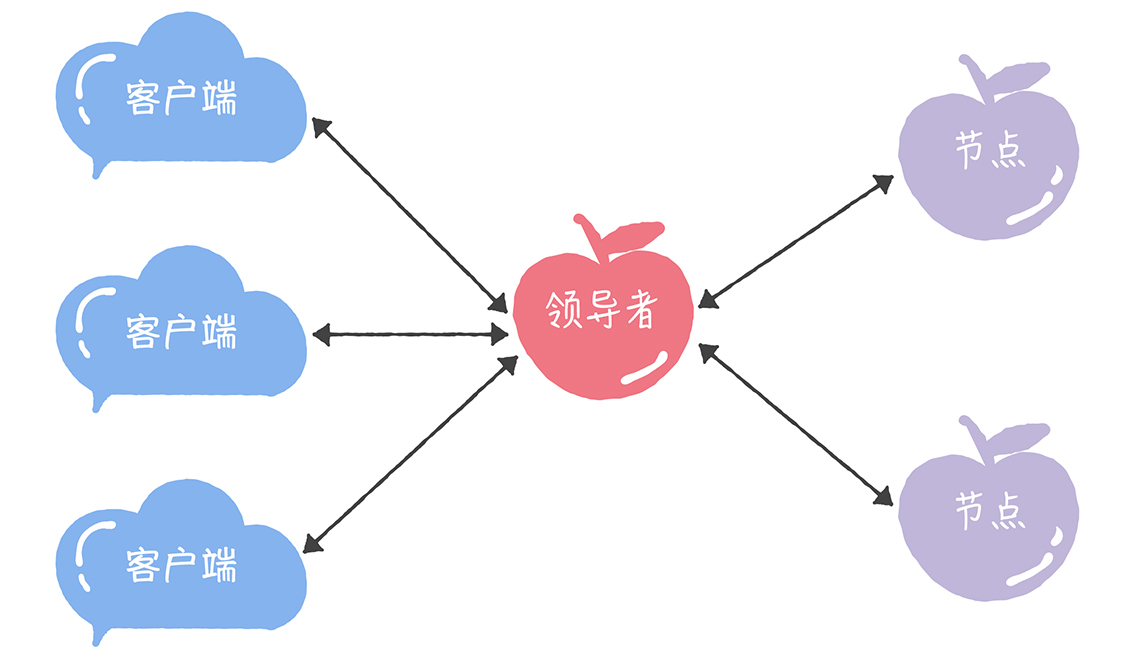
1.引入领导者
让领导者作为唯一提议者
这里涉及到如何选举领导者,不同的算法可以有不同的实现方法
Chubby 是通过执行 Basic Paxos算法投票选举
Raft通过一个随机倒计时功能,最快得到大多数投票的为领导者
2.优化 Basic Paxos执行
采用当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段展开










