01|SRE迷思:无所不能的角色?还是运维的升级?





讲述:赵成
时长11:00大小10.09M
SRE,我们应该怎么来理解它?
做好 SRE 的根本目的是什么?

总结
思考题

1716143 665 拼课微信(22)
 2020-03-18说下我的感受。
2020-03-18说下我的感受。
DevOps主要是以驱动价值交付为主,搭建企业内部的功效平台。
SRE主要需要协调多团队合作来提高稳定性。
例如:
- 与开发和业务团队落实降级
- 在开发和测试团队内推动混沌工程落地
- 与开发团队定制可用性衡量标准
- 与开发,测试,devops,产品团队,共同解决代码质量和需求之间的平衡问题。展开作者回复: 分析地恰到好处,你找到了看待这个问题的正确角度。
12 2020-03-20赵老师,好。SRE是否从项目开始就需要参与系统架构设计?如果只是在项目上线运行后才接触,遇到架构不合理的地方如何处理?展开
2020-03-20赵老师,好。SRE是否从项目开始就需要参与系统架构设计?如果只是在项目上线运行后才接触,遇到架构不合理的地方如何处理?展开作者回复: 肯定是越早参与越好,并不一定参与设计本身,但是要知道再哪里提出稳定性要求。比如一个促销场景,要知道可能流量是怎么样的,限流措施要设定在哪些接口上,限流量多大,通过什么方式验证等等,通过这种提要求的方式,倒逼业务开发和架构师思考设计和编码。
1 2020-03-20个人觉得DEVOPS目的是更快的创新和更好的客户体验。SER的目的是最快的速度恢复故障!不管是AWS的DEVOPS还是GG的SRE,适合的才是最好的!都是在慢慢通往这个道路上。最后隐隐约约:SRE和DevOps它有,它无:它无,它有!不知道用语言怎么表达展开
2020-03-20个人觉得DEVOPS目的是更快的创新和更好的客户体验。SER的目的是最快的速度恢复故障!不管是AWS的DEVOPS还是GG的SRE,适合的才是最好的!都是在慢慢通往这个道路上。最后隐隐约约:SRE和DevOps它有,它无:它无,它有!不知道用语言怎么表达展开作者回复: 感觉很准奥,可以看看其他评论内容,这个问题基本就有答案了。
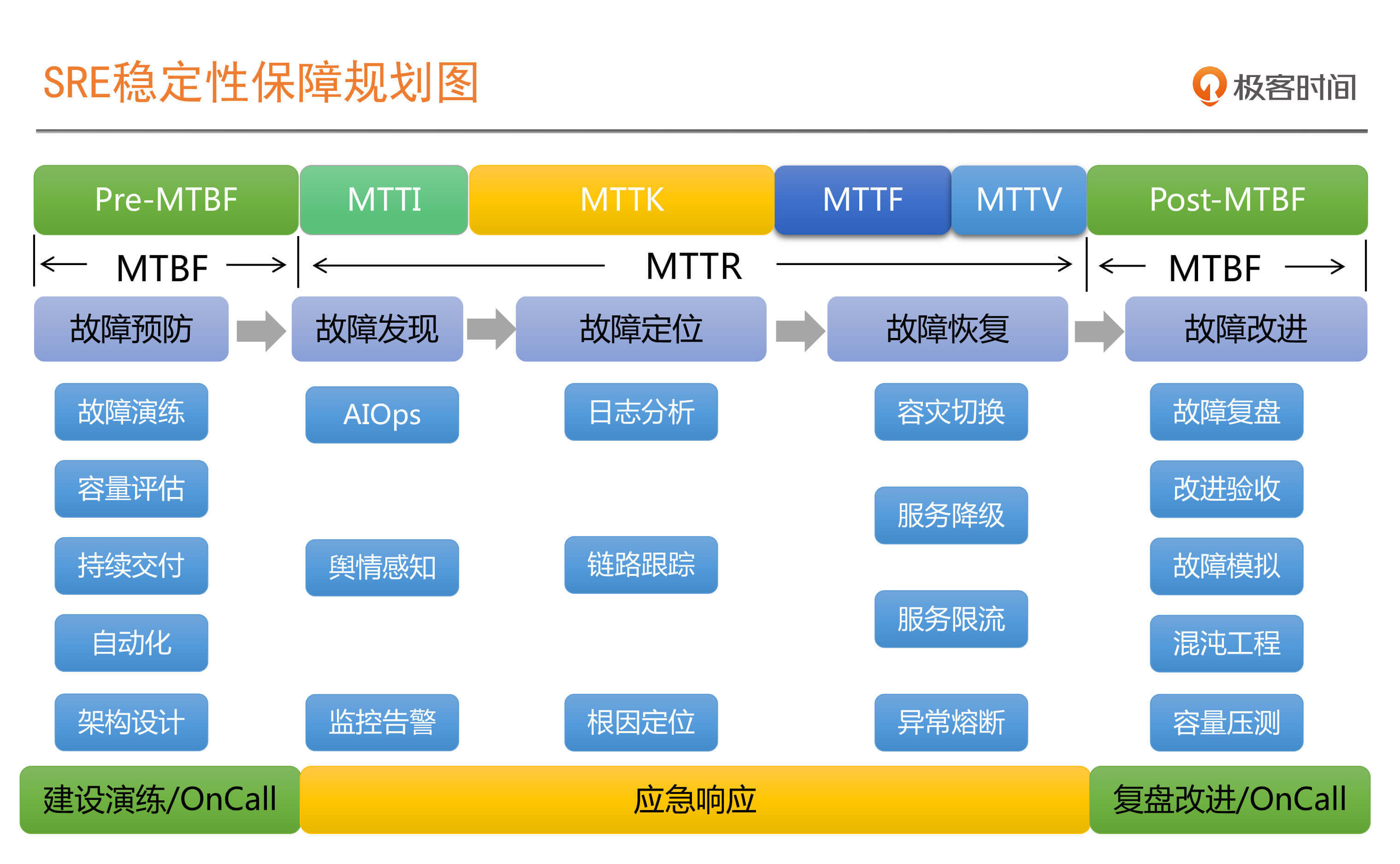
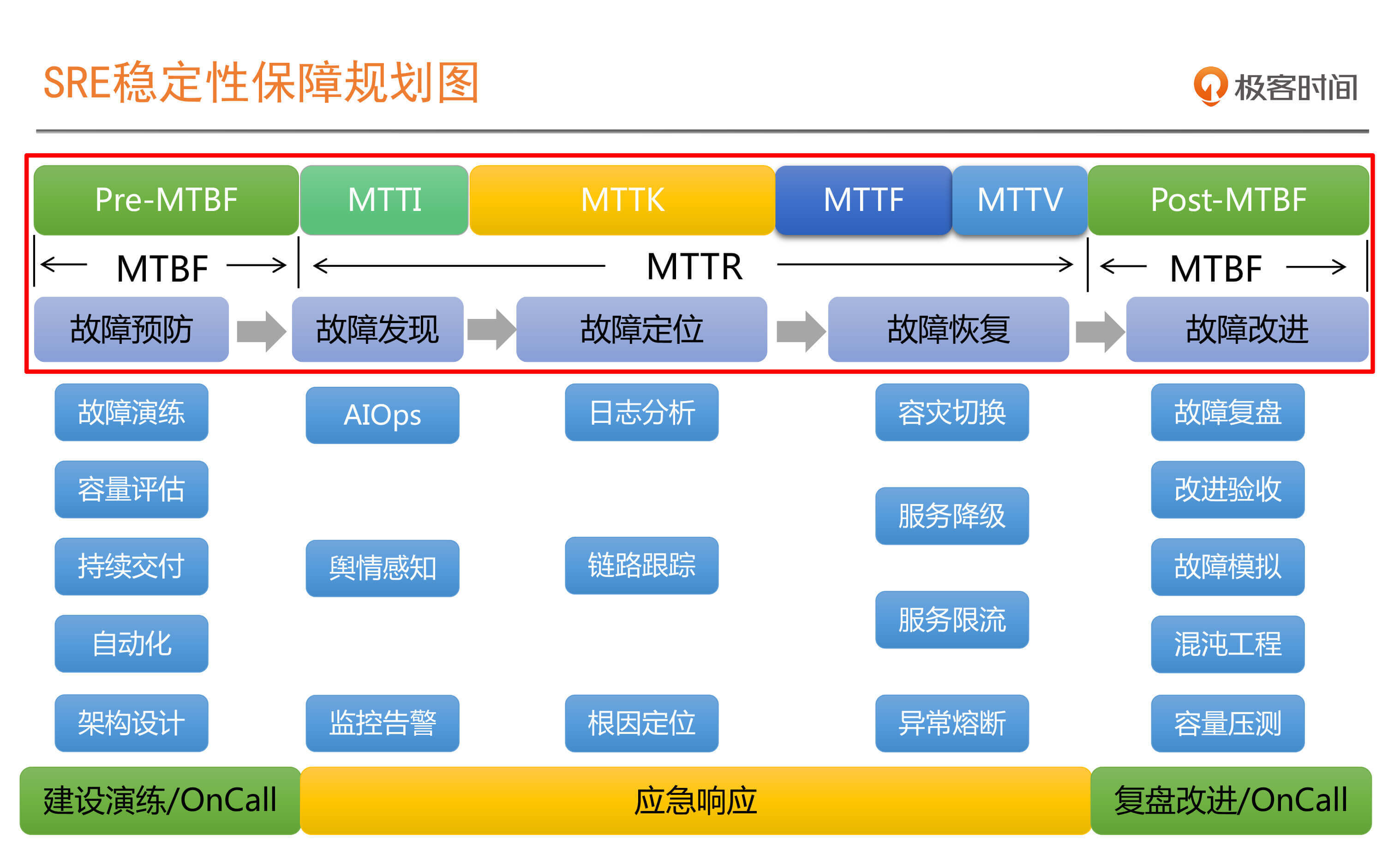
1 2020-03-19听成哥这么一说,顿时有种豁然开朗的感觉。降低 MTTR,提升 MTBF。而 MTTR 里面,MTTI 一定要快。不过这里有一点不太理解,平常都是要以业务恢复为第一优先级的,这时候可能回滚变更操作就非常重要了,然后再去定位根因,先定位根因再去恢复业务,这个是有适用场景的吧。展开
2020-03-19听成哥这么一说,顿时有种豁然开朗的感觉。降低 MTTR,提升 MTBF。而 MTTR 里面,MTTI 一定要快。不过这里有一点不太理解,平常都是要以业务恢复为第一优先级的,这时候可能回滚变更操作就非常重要了,然后再去定位根因,先定位根因再去恢复业务,这个是有适用场景的吧。展开作者回复: 非常棒的问题,而且“业务恢复”永远都是第一优先级,你的理解非常正确。
这里提到是正常流程,但是实践中我们一定会根据实际情况来活学活用,所以,是不是要定位出根因,还是定位出根因范围就要看取舍了,有时我们大致定位出根因范围,然后就要开始执行响应的恢复和隔离措施了。
有点类似当前我们正在经历的疫情,虽然我们知道是新型病毒,但是根源来自哪里并不清楚,而且也没有预防和有效的治愈良药,这时最有效的办法就是提前发现,然后隔离,这种就不可能等着根因定位清楚,再采取措施。 1- 2020-03-19SRE解决运维领域的故障目标,DevOps更偏向于为价值导向的效率目标,但是这个又是你中有我,我中有你,互相成就的一个过程,在实践SRE体系过程中,不可避免的要使用到一些DevOps中的一些技术,方法论,组织文化等,通过这些,达成一致目标。~~~展开
作者回复: 理解地非常正确!
1  2020-03-18class SRE implements DevOps
2020-03-18class SRE implements DevOps
可以简单理解为DevOps 是一种接口,但是没说怎么实现,SRE 提供了一种视角,这么做在Google 成功过,可以结合自己企业的特点去实现DevOps 这个接口,做有自己特色的‘SRE’ 即可。展开作者回复: SRE是DevOps的一项最佳实践。
1 1 2020-03-18看赵老师之前的书讲:SRE是 用软件工程的方法重新设计和定义运维。
2020-03-18看赵老师之前的书讲:SRE是 用软件工程的方法重新设计和定义运维。作者回复: SRE的一个理念,非常关键,一定要通过技术手段解决运维问题,而不是人肉投入。
1 2020-03-18SRE 要求对公司业务架构要有一个宏观的了解展开
2020-03-18SRE 要求对公司业务架构要有一个宏观的了解展开作者回复: 你讲到一个非常重要的点,SRE要想做好,必须要对公司业务有全局的了解,甚至是非常深入的了解
2 1- 2020-03-22说的很清楚,SRE就是一个体系化工程展开
作者回复: 谢谢,多交流^_^
 2020-03-21赵老师,其实从实际问题处理的情况看,根因分析放在故障定位是不太合适的,这样会耽误故障恢复的,重点应该放在如何恢复。比如很多时候我们找到异常组件进行隔离就可以了,然后在事后分析那个组件的异常原因。展开
2020-03-21赵老师,其实从实际问题处理的情况看,根因分析放在故障定位是不太合适的,这样会耽误故障恢复的,重点应该放在如何恢复。比如很多时候我们找到异常组件进行隔离就可以了,然后在事后分析那个组件的异常原因。展开作者回复: 非常好的问题啊,而且你的分析是正确的。
关于这个问题,我在另外一位同学的留言中答复了,你可以先看一下,在06篇中,我也会讲到这个问题,到时可以看一下。 1 2020-03-21我想问个问题,怎么算一个故障?客户投诉或者自己发现?或者有些问题可能是故障有些可能不是故障,粒度怎么界定展开
2020-03-21我想问个问题,怎么算一个故障?客户投诉或者自己发现?或者有些问题可能是故障有些可能不是故障,粒度怎么界定展开作者回复: 这是个很好的问题,说明已经思考的很深入了。
关于这部分内容,提前预告下,在SRE中我们会用Error Budget来细化度量,我们将在接下来的04篇文章中会介绍。 2020-03-21赵老师你好,听完本篇我又重新听了开篇。您接下来所讲的内容,应该都是基于团队已经在SRE实践的道路上。1.那么我们该如何判断某条业务线是否值的推行SRE体系呢?(业务的背景大致可以理解为:既追求稳定性,又不过分追求,且DevOps成熟度基本满足业务需求)
2020-03-21赵老师你好,听完本篇我又重新听了开篇。您接下来所讲的内容,应该都是基于团队已经在SRE实践的道路上。1.那么我们该如何判断某条业务线是否值的推行SRE体系呢?(业务的背景大致可以理解为:既追求稳定性,又不过分追求,且DevOps成熟度基本满足业务需求)
下面是自己对DevOps,SRE概念理解的方式,欢迎指正:
a. 人们对SRE理解存在偏差,是因为局限个人经验与当下所处维度(IT环境)造成的;通常当我们对一个概念理解存在模糊状态时,通过追溯到它的历史起源,对于理解它会更加深刻,也更加能够看清它真正的意图。
b. 一个职位的兴起,绝不是凭空在当前维度出现的,兴许是上游出现了某种压力/变化,于是下游便出现某个职位来应对这种压力/变化。
文章结尾补充一个问题:DevOps与SRE矛盾点:
c. devops解决全栈交付,全栈交付是非稳定性因素之一,而SRE关注稳定性展开作者回复: 某条业务线是否推行SRE,有个判断依据就是,是不是需要运维或SRE这样的团队介入,如果需要运维或SRE保障,那就要推行后面我们要讲的SRE体系,如果是开发自己维护,没有另外的团队参与,那就自行判断。
关于你的理解,我觉得很棒,特别是B,任何一个岗位或方法的出现,都是因为有问题解决不了被倒逼出来的,从我的角度,DevOps是如此,SRE也是如此。 2020-03-21我们是只有三个人的运维小团队,而且职能也没有分的那么清楚细,基本上是每个人所有的事情都做,而SRE又涉及到这么多方面。请问老师,对于我们这种小团队,要实践SRE应该先从哪方面入手?
2020-03-21我们是只有三个人的运维小团队,而且职能也没有分的那么清楚细,基本上是每个人所有的事情都做,而SRE又涉及到这么多方面。请问老师,对于我们这种小团队,要实践SRE应该先从哪方面入手?作者回复: 团队规模不大,我不建议一开始就去推行SRE。按照经验,这个阶段很有可能你的运维标准,自动化这些工作还没有完全做到位,如果要入手,建议从这里开始,再往后就是做软件的发布,再接下来可以考虑按照我们后面要讲的SLO的内容,去做稳定性的运营。
- 2020-03-20虽然现在是在做devops,我们公司没有sre的岗位,听完这节课之后还是对这两个岗位有了一定的认识。
devops目标是提升开发效率和提升交付效率。
sre是保证服务稳定。
devops针对的是交付产品和开发者,sre针对的是服务。
一个追求交付在产品的质量上的快,一个是追求产品部署之后部署的稳。
在请教老师个问题,是不是sre岗位在to c的公司居多呢,国内sre现状是咋样的呢。展开作者回复: 不仅toC需要,toB也需要,很多的云计算公司,都有专门的SRE部门和岗位。
再就是也不一定非要有SRE的岗位,就像我在本篇中讲到的,很多的SRE工作我们都在做,只不过是分散在了不同的部门和岗位上。 1  2020-03-20传统的运维很容易变成开发的工具人。sre 通过自动化系统、制定规范流程等工资将自己脱离工具人角色,再运用运维体系丰富的知识结合当前线上的实际情况,尽可能提升线上稳定性
2020-03-20传统的运维很容易变成开发的工具人。sre 通过自动化系统、制定规范流程等工资将自己脱离工具人角色,再运用运维体系丰富的知识结合当前线上的实际情况,尽可能提升线上稳定性作者回复: 除了开发工具,还可以通过线上系统运行的数据来运营,比如整体比定性指标、资源利用率、成本分布等等。
 2020-03-20MTTF,还有种缩写是Mean Time To Failure ,平均故障前的时间,和文章里的MTBF一个意思。可用性的计算公式MTTF/MTTR+MTTF 是稳定性领域的第一性原理,,这个在左耳听风的专栏弹力设计里也有讲到。。。缩写方式太多😂展开
2020-03-20MTTF,还有种缩写是Mean Time To Failure ,平均故障前的时间,和文章里的MTBF一个意思。可用性的计算公式MTTF/MTTR+MTTF 是稳定性领域的第一性原理,,这个在左耳听风的专栏弹力设计里也有讲到。。。缩写方式太多😂展开作者回复: 掌握住一种就可以,后面我会详细讲应该如何计算,环境继续学习。
 2020-03-19devops只是sre中的一环,提供高效的交付,测试,发布。
2020-03-19devops只是sre中的一环,提供高效的交付,测试,发布。作者回复: DevOps是从用户价值交付视角出发,SRE是从稳定性视角出发。
1- 2020-03-19无论sre还是devops,从实用的角度看,哪个能够更简单高效低成本地解决眼下的痛点,并为以后的技术演进保留足够的想象空间,就选哪个。行业不缺牛人,也不缺顶尖技术,但每家公司的条件和能负担的成本是不一样的,设合自己的才是最好的展开
作者回复: 非常正确,适合自己的才是最好的,一定要关注自己的问题,而不是仅仅关注各种Buzz Word。
 2020-03-18更看好SRE展开 3
2020-03-18更看好SRE展开 3 2020-03-18DevOps的课程其实自己学习的蛮深包括相关书籍可以说不少都看了一遍,相关工具如果要花费大量时间可能对我而言确实有点难,尤其运维【注:我所值的运维不仅仅是指系统,包括数据库、操作系统、机房。。。这个整体】
2020-03-18DevOps的课程其实自己学习的蛮深包括相关书籍可以说不少都看了一遍,相关工具如果要花费大量时间可能对我而言确实有点难,尤其运维【注:我所值的运维不仅仅是指系统,包括数据库、操作系统、机房。。。这个整体】
不过开发能力的短板对我而言确实短时间难以提升太多:效率和平台体系的合理结合,如何二者互补我觉得才是更加去追求的。
我们常说万能的运维:其实运维大多数在coding能力方面还是无法和开发比,不过在效率与性能排查方面又是开发无法做到的。故而我记得老师课程中推荐《SRE Google运维解密》书中强调的内容就如老师今天流程图中的oncall,其实DevOps同样看如何去解释和理解;就像DevOps经常和敏捷混淆一样。
平台体系的思路去做好就好:过分去追求SRE或者DevOps,可能我们反而会迷失其本意。
谢谢老师的分享:我觉得听课的过程又可以再把老师的书和课程在看一遍了;说不定课程结束自己的版本就出来了。展开作者回复: “过分去追求SRE或者DevOps,可能我们反而会迷失其本意。”,这句你抓住重点了,最重要的是看问题是什么,而不是纠结SRE或DevOps是什么,而是看他们能怎么帮助我们解决问题。
还有最后,非常期待和希望,你能在课程结束时,分享出你自己的感受和内容