02 | 系统可用性:没有故障,系统就一定是稳定的吗?





讲述:赵成
时长11:43大小10.73M
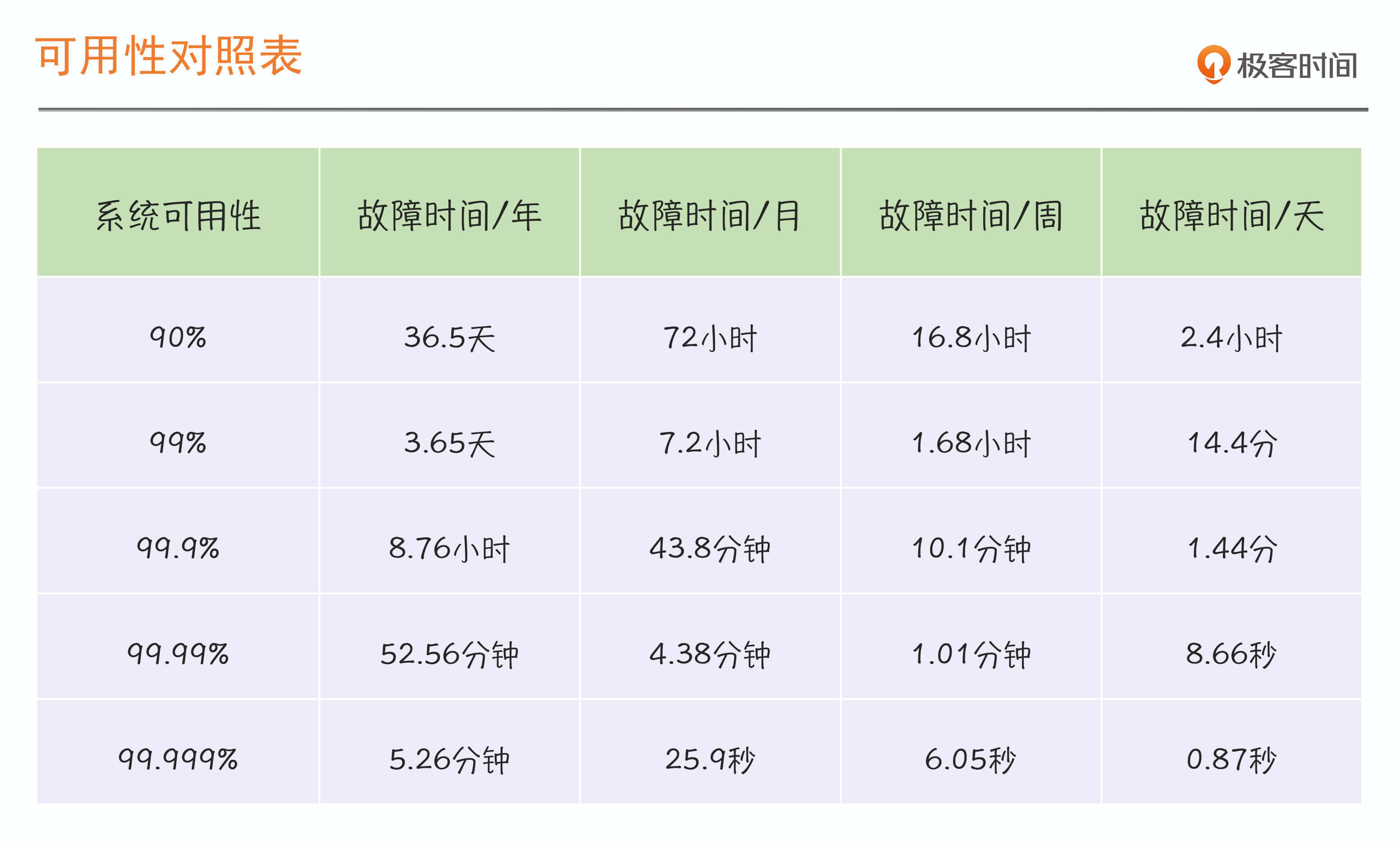
衡量系统可用性的 2 种方式
设定系统稳定性目标要考虑的 3 个因素
总结
思考题

精选留言(13)
- 2020-03-19从业务部门的视角来看,状态码是多少他们是不关心的,他们关心的是业务是否真正的可用。比如,极端一点,状态码正常,但返回的内容不是预期的。
另外,如果业务不是需要7*24的,可用性指标应该是仅限定在业务开展期间。
有点扯远了……展开作者回复: 很好的问题。从两个方面来看:
1、返回的业务内容不是预期的,这一点应该更多的是要QA来解决,这个本质是是功能问题,其实SRE是不需要关注这样的异常的。
2、如果可以做到内容不同,返回码不同,也可以做到稳定性的监控。比如对于一个用户登录应用,如果登录成功是200ok,验证码错误是1001,密码错误是1002,如果总是提示验证码错误,这种也是可以纳入到稳定性的监控指标中的。
关于第二个问题,7*24小时值守,这个看业务特点,比如对于证券类的应用,每天就是几个固定时段,所以没必要7*24小时。 5  2020-03-18就像老师课程中所提及的三要素”成本因素、业务容忍度、系统当前的稳定性状况“。这三点无一不需要综合考虑,甚至有时都得考虑三者之间的比例。
2020-03-18就像老师课程中所提及的三要素”成本因素、业务容忍度、系统当前的稳定性状况“。这三点无一不需要综合考虑,甚至有时都得考虑三者之间的比例。
个人在此之外会考虑”离散度“:确实有时觉得好像还稳定,可是离散度是否正常。记得老师的推荐的书籍中就提及过,"系统正常是系统异常的特殊情况";有故障才是是常态。没有故障且稳定说明大家都在做机械化重复操作,如何从故障和不稳定中找出问题才是根源。
老师在上一堂课中给出"建设演练/oncall->应急响应->复盘改进/oncall”我觉得就非常好的体现了SRE的理念。谢谢老师今天的分享,让我又享受在学习的过程之中。展开作者回复: 你的分享也非常用心,总能抓住很多关键点,很赞!
3 2020-03-19系统可用性从用户角度来评价最直接,至少包括
2020-03-19系统可用性从用户角度来评价最直接,至少包括
1:能否访问到。这应该包括从用户操作到收到响应整个端到端的是否可用,对于用户最后一公里的不可控段也需要能感知和预警。
2:访问是否顺畅。响应时间是否异常展开作者回复: 从用户角度来评价,这个点把握的非常准确。
1 2020-03-19简洁,清晰展开
2020-03-19简洁,清晰展开作者回复: 谢谢!看看能不能用简介清晰的几句话表达出来呢^_^
1 2020-03-22可用性指标,我觉得还需要区分下
2020-03-22可用性指标,我觉得还需要区分下
1. 业务可用性,可以称之为“源站””,这里的统计指标最好给业务提供最大的灵活性,授权rd自身配置uei,请求方法,以及正常状态码。这里需要注意一个问题,有时候301/302/499也是错误码(比如为了友好提示5xx内部跳转,触发请求限流503),所以最好将body自定义内容作为判断指标。
2. 网络(用户)可用性。源站可用,不意味着用户也可用。可以通过监控班类的APM统计可用行指标和响应延迟(比如大于5s以上且5个节点,某某运营商线路丢包或者抖动等等)展开作者回复: 感谢你提供了用户可用性这个维度,从SRE角度,离用户越近的指标,越有价值。
 2020-03-21RED、USE、four golden signals展开
2020-03-21RED、USE、four golden signals展开作者回复: 很有意思的回答,我再提一个问题,就是four golden signals适合做衡量稳定性的指标吗?
- 2020-03-21请教一下,老师怎么看AIOPS,AIOPS对线上的业务来说,真的有(真实的)价值吗?
作者回复: 要清楚,AIOps对业务本身是没有价值的,它是为运维服务的,所以它的价值更多的体现在运维层面。
体现在运维层面的哪里呢?就是问题发生前的预判、以及根因分析这些,因为在大规模分布式系统下,没有这个手段就没法处理问题。
但是AI要有两个要素,一个是算法,一个是数据,算法是靠数据训练的,这里算法不是问题,但是数据量是不是足够大就是问题,所以一定要业务体量足够大,资源规模足够大,产生的日志信息足够丰富,这时AIOps才有意义,如果只有几十几百台服务器的规模,业务体量也没有那么大的情况下,AIOps的作用是不大的。  2020-03-21系统的稳定性的衡量指标最关键要与业务结合一起。
2020-03-21系统的稳定性的衡量指标最关键要与业务结合一起。
我认为最重要的是要引入服务的健康检查机制,具体说明:
如A服务依赖诸多中间件例如数据库、消息队列等,也依赖其他B、C等服务。A服务对检查的服务所依赖的不同的中间件或服务定义为HealthCheck的最终结果为true或false,任何一个HealthCheck的healthy结果为false,那么最终状态就会是false。{
"healthcheck":[
{ "status": "true|false"
}
]
"rds":[
{
"name":"实例1 " ,
"status": "http_code_status",
},
{
"name":"实例2" ,
"status": "http_code_status"
},
]
"redis":[
{
"name":"实例1 " ,
"status": "http_code_status"
},
{
"name":"实例2" ,
"status": "http_code_status"
}
]
"mongodb":[
{
"name":"实例1 " ,
"status": "http_code_status"
},
{
"name":"实例2" ,
"status": "http_code_status"
}
]
"app":[
{
"name":"domainB" ,
"status": "http_code_status"
},
{
"name":"donmainC" ,
"status": "http_code_status"
}
]
}
上面是个比较简单的服务健康检查,可以应用到部署检查和服务可用性探测。
这里,也可以再完善,可以对调用的服务或组件进行优先级划分,比如调用数据库1是核心库(高优先级服务),那么服务A调用数据库1返回状态为非200(自行根据业务场景设置请求次数),那么服务A就不可用(可以标记为“紧急“),调用其他数据库2或服务B为非核心库或非核心服务(低优先级服务),这里服务并不影响核心功能,可以认为此服务可用,那么这里调用返回结果可标记为“警告”。展开作者回复: 你提供了一个很好的案例。你提到的是针对单次请求的成功与否,但是如果要判断服务是不是正常,单次判断是不是够?如果不够,那应该采取什么样的判断方式呢?
可以尝试思考下这两个问题。 1- 2020-03-21这一节感觉类似于监控~
可收集的指标有
机器性能,比如说磁盘io,cpu占用率,内存使用率,这些在空闲的时候和忙碌的时候对请求的影响肯定不一样,如果是对读写有要求的应用,磁盘读写会影响很大。
网络带宽,带宽占用率大的时候也会对请求有影响。
还有就是应用本身的请求返回时间,也是重要滴。
请教老师个问题,如果收集指标过多的话,会不会加权打分来判断异常程度呢展开作者回复: 这个问题你可以先思考下,因为接下来的一讲,我们就会详细讲解这部分内容。
 2020-03-20可用性和新功能是矛盾,考虑到这个矛盾关系,可用性目标还跟新功能的需求有关系吧,例如公司/产品快速增长阶段甚至能适当容忍可用性故障展开
2020-03-20可用性和新功能是矛盾,考虑到这个矛盾关系,可用性目标还跟新功能的需求有关系吧,例如公司/产品快速增长阶段甚至能适当容忍可用性故障展开作者回复: 是的,就是业务容忍度。
不过你提到的在快速增长阶段要特殊考虑,确实也是一个需要考虑的维度和因素。 2020-03-20请求成功率的判定需要一定分类和标准。请求可以分类,静态请求,动态请求。动态请求还可以按业务模块进行细分,这样故障时初步就可以定位故障位置,影响范围。静态请求比较好判定,排除网络问题,基本可以访问到就可以。动态请求,这个得具体分析,有的请求比较复杂,正常就慢,这块判断就得靠人员经验和历史数据了。展开
2020-03-20请求成功率的判定需要一定分类和标准。请求可以分类,静态请求,动态请求。动态请求还可以按业务模块进行细分,这样故障时初步就可以定位故障位置,影响范围。静态请求比较好判定,排除网络问题,基本可以访问到就可以。动态请求,这个得具体分析,有的请求比较复杂,正常就慢,这块判断就得靠人员经验和历史数据了。展开作者回复: 最后一句,动态请求要靠经验和历史数据,其实也可以形成一种度量标准,接下来的第03部分,就会介绍到。
 2020-03-20机器性能指标
2020-03-20机器性能指标
应用层级指标
服务质量指标展开作者回复: 赞!
 2020-03-20响应时间,吞吐量,系统资源占用展开
2020-03-20响应时间,吞吐量,系统资源占用展开作者回复: 非常好,如果能尝试再分个类就更棒了。再就是,要看下,响应时间、吞吐量、资源占用,他们的主体是谁?









