特别加餐 | 倒排检索加速(一):工业界如何利用跳表、哈希表、位图进行加速?





讲述:陈东
时长19:57大小18.28M
跳表法加速倒排索引
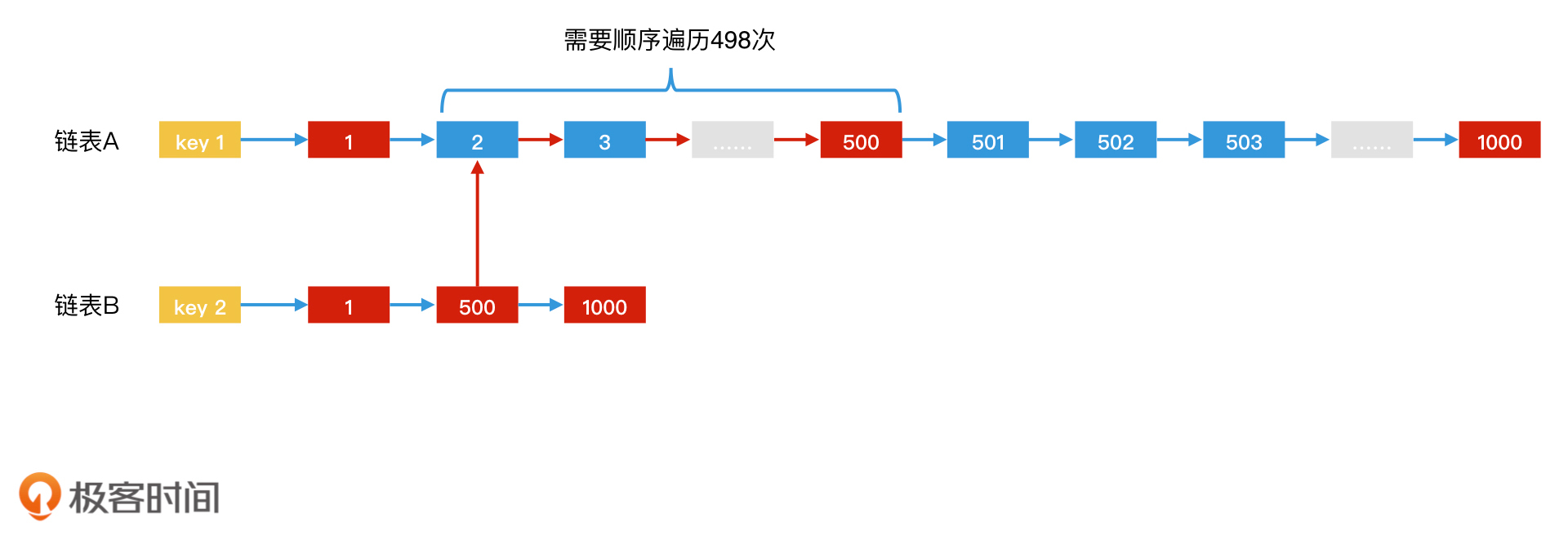
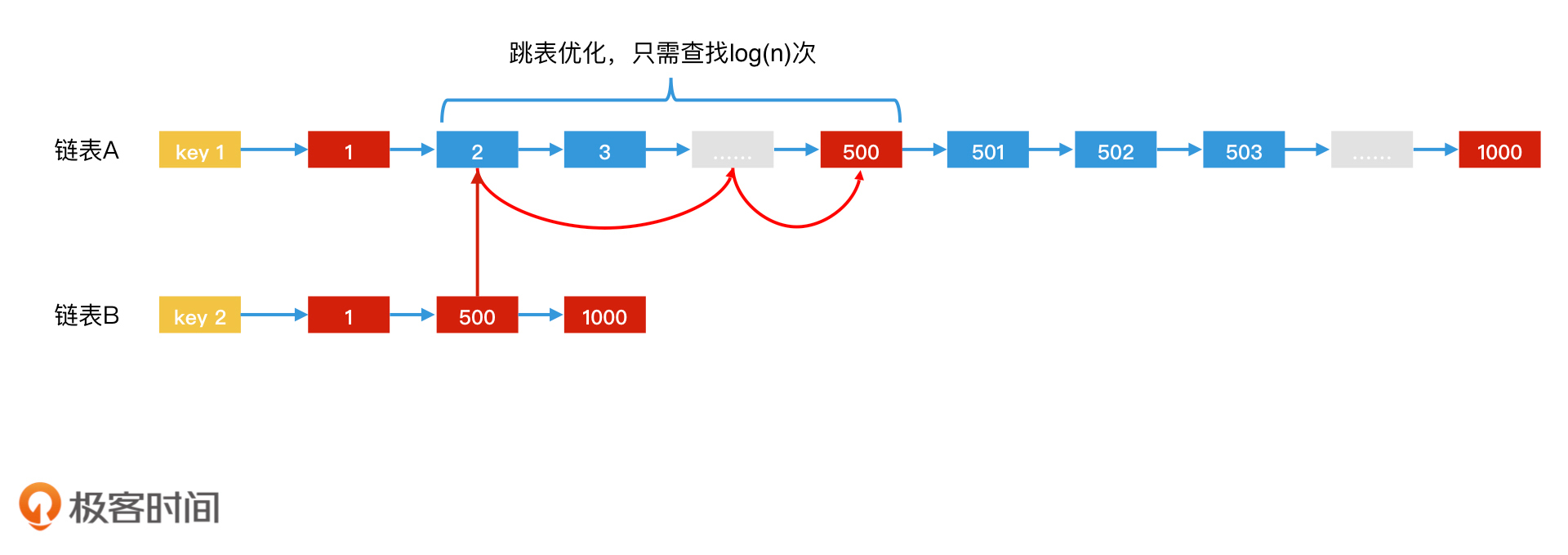
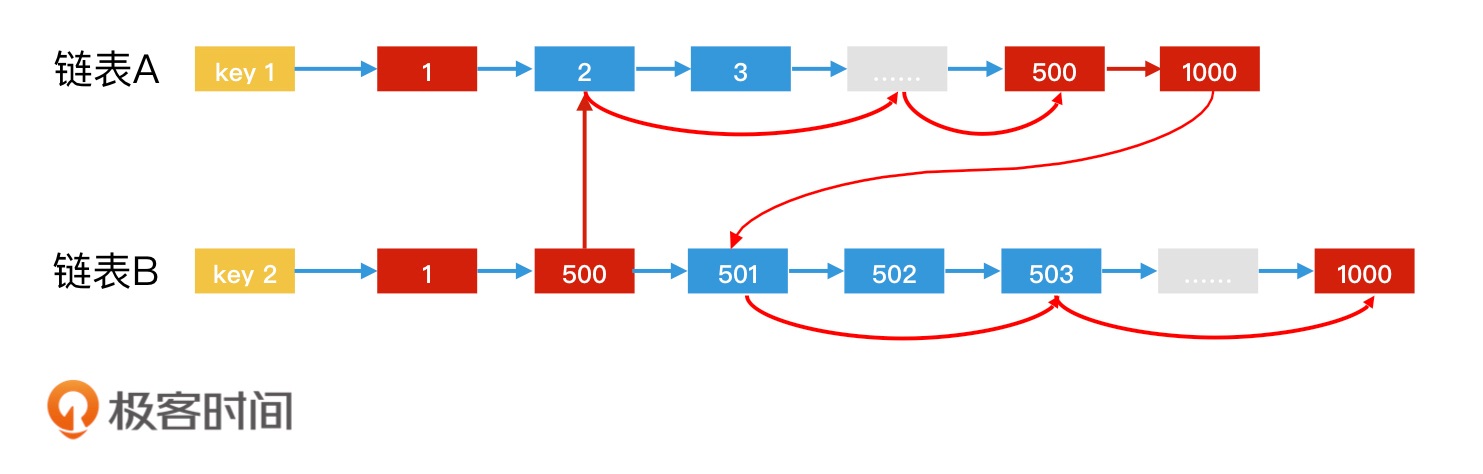
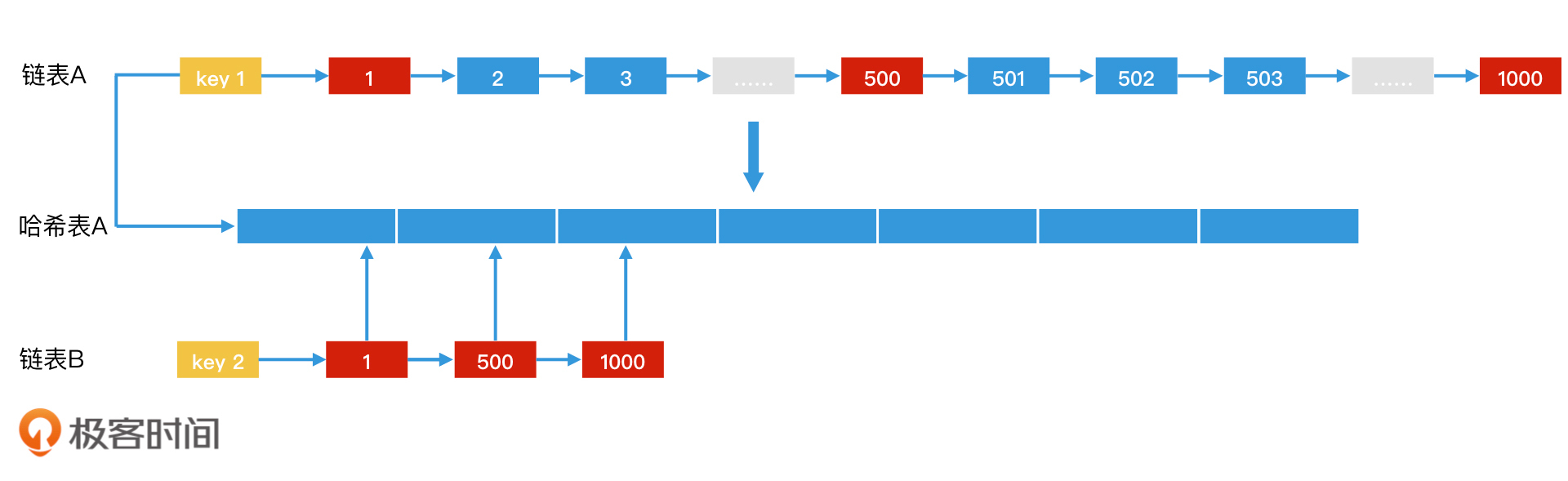
哈希表法加速倒排索引
位图法加速倒排索引
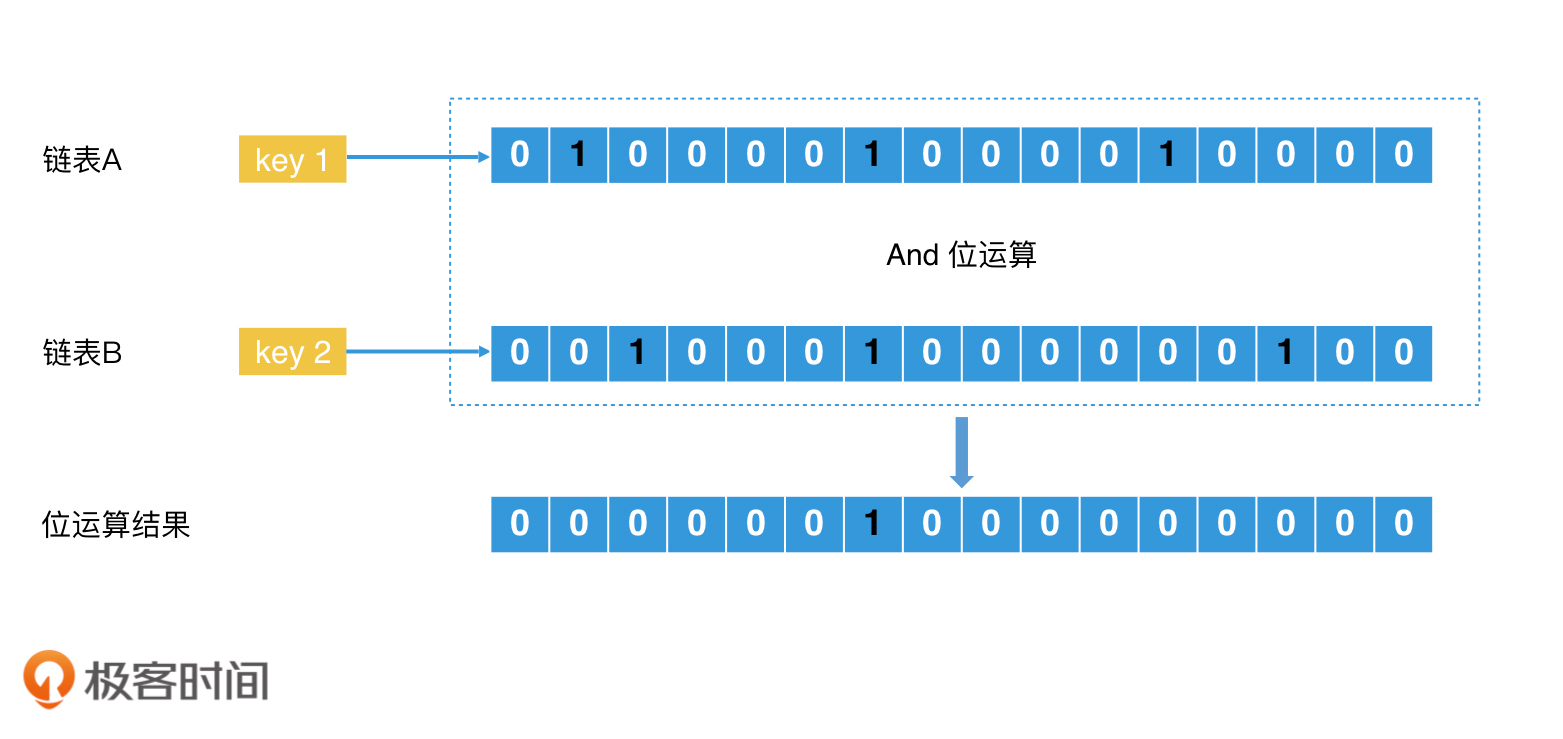
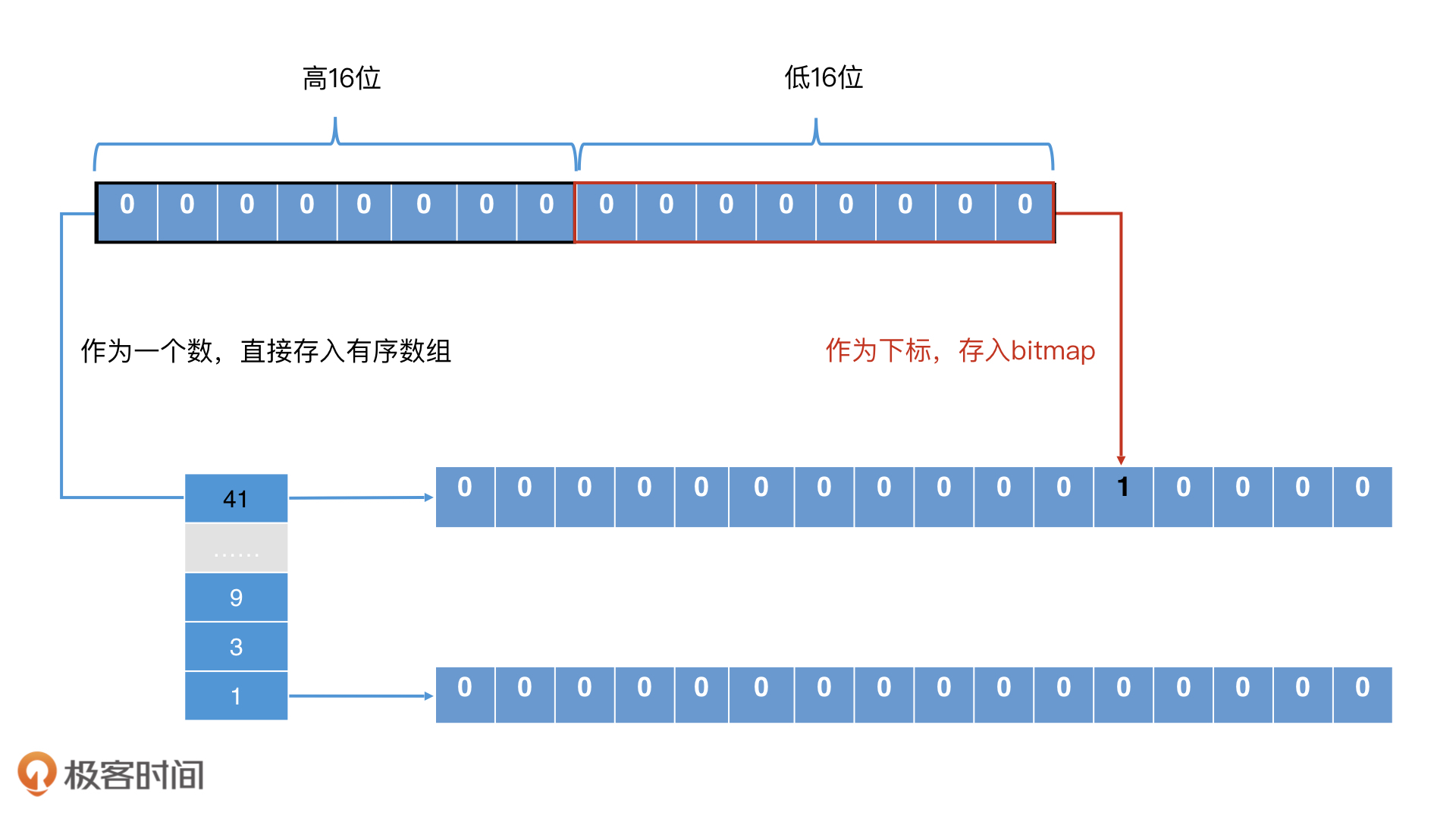
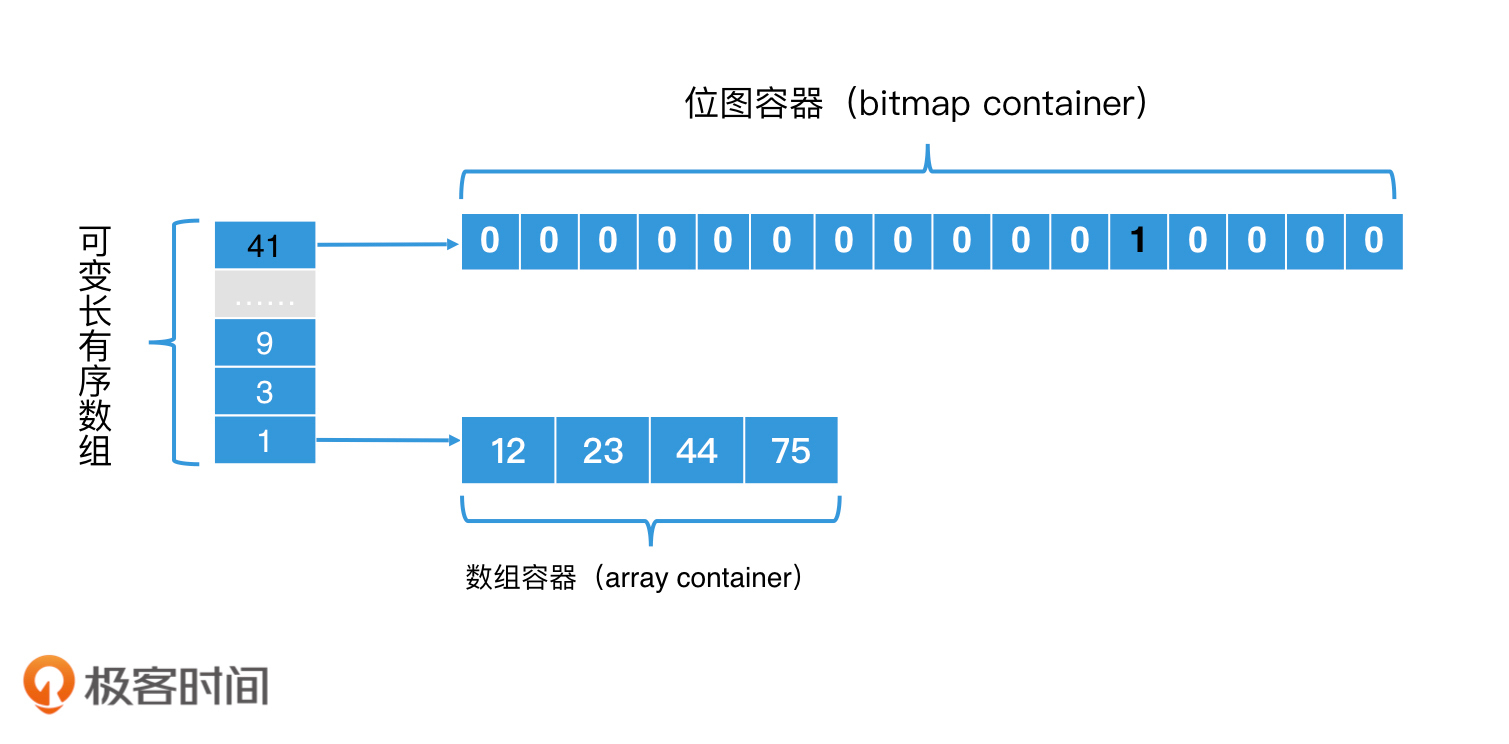
升级版位图:Roaring Bitmap
重点回顾
课堂讨论

精选留言(7)
 2020-04-06思考题:
2020-04-06思考题:
数组和数组求交集、位图和数组求交集 这两种情况可以很容易的想到是使用数组
这里解释一下 位图与位图交集的预判的情况,一般是怎么进行预判的:
假设位图1有 n1 个值, 位图1 有 n2 个值,位图的空间位 2 ** 16 = 65536
这里进行预判的时候可以认为是均匀分布的:
那么对于位图1 可以认为间隔 65536 / n1 个位有个值,位图2 可以认为间隔 65536 / n2个位有个值,
那么同时存在 n1和n2 的间隔为 t = ( 65536 / n1 ) * (65536 / n2),那么交集出来的个数为
m = 65536 / t = n1 * n2 / 65536 , 载拿 m 和 4096 进行比较 预判即可展开作者回复: 分析得很清晰!在系统面临多种后续情况时,一种常见的处理方式就是预判一种概率最大的情况,先按这种情况处理。这样系统的整体统计性能会最好。
1 1- 2020-04-06仔细算了 一下 Roaring bitmap 压缩后使用的空间,发现压缩率非常大
在一个正常的 32位的 bitmap 占的空间位 2 ** 32 bit ---> 2 ** 29 byte ---> 2 ** 19k---> 2 ** 9 M 也就是512 M
在使用Roaring bitmap 后一个键位图占的空间位(不考虑高16位的数组空间动态申请,和底16位使用数组存储): 提前申请好高16位的空间为 2 ** 16 * 2 byte = 2 ** 17 byte --> 2 ** 7 k, 一个位图的空间为 2 ** 16 bit --> 2 ** 13 byte --> 2 ** 3 k, 所以需要的总空间位 2 ** 7 k * 2 ** 3 k = 1 M
从 512 M 降到 1M 这个效率,所以设计好的数据存储结构是写好程序的第一步展开作者回复: 你很好地理解了roaring bitmap的思路。不过空间不会无缘无故变出来的,在极端情况下(高16位都有,低16位都是位图),那么roaring bitmap不会比原始位图小。你可以仔细算一下,每个位图是8k,如果高16位每个数都存在,那么就有2^16个位图,2^16*8k = 2^9 M = 512M
1  2020-04-07看到了同学们的评论,感觉大家思考的还是很全面啊。
2020-04-07看到了同学们的评论,感觉大家思考的还是很全面啊。
看到了很多同学提到的预判的m值。这里的m值是1假设均匀分布下求出来的,也就是说是65536**2/(n1*n2)但是还看到是n1*n2/65536这两种不等价啊。作者回复: 65536^2/(n1*n2)= t,表示的含义是每隔t个0会有一个1。因此一个长度为65536的位图中,1的个数就是65536/t = (n1*n2)/65536。
我也可以换另一个方式推导,你可以看看:
对于位图a,第一个位置是1的概率是n1/65536(推导过程:如果只有一个1,落在第一位的概率是1/65536;如果有n1个1,那么第一位为1的概率就是n1/65536)。
对于位图b,第一个位置为1的概率是n2/65536。
因此,位图a和位图b第一个位置同时为1的概率就是(n1*n2)/65536^2。
同理,第二个位置同时为1的概率也是(n1*n2)/65536^2。以此类推,一共有65536个位置,因此1的个数就是65536 * (n1*n2)/65536^2,结果就是(n1*n2)/65536。
不过话说回来,具体怎么求概率不是我出这道题的期望,只要大家能理解“程序在面临分支选择时,会快速通过计算进行预判”这个设计思想就好了。 1 2020-04-06不同数据规模,使用不同算法。熟悉业务场景和数据规模,是根本。
2020-04-06不同数据规模,使用不同算法。熟悉业务场景和数据规模,是根本。作者回复: 是的。所以我这一篇把几种方法放在一起,方便对比。此外,在roaring bitmap中,数组容器和位图容器会自动相互转换,这就是一个很好的例子,包括在hashmap中也是,它会在链表和红黑树之间进行转换。因此,我们能学到的一个高性能系统的设计思路,就是自动根据数据规模转换最合适的数据结构和算法。
 2020-04-06思考题
2020-04-06思考题
1.位图和位图求交集
要对两个位图的交集做预判,如果预判数据大于 4096 就用位图,如果小于 4096 就用数组,当然预判肯定会有误判率,不过没关系,即使误判错多做一次转换就行了
2.数组和数组求交集
数据和数据求交集结果肯定还是用数组存
3.位图和数组求交集
位图和数组求交集也是用数组
问题请教:
对 Roaring Bitmap 这儿看的不是很明白,也不知道自己哪里不明白,可能就是不明白吧,请问老师这块有啥好的学习方法吗?
还有就是对于 Lucene 采用 RoaringDocIdSet 实现的 Roaring Bitmap,要想学好这里,是不是还要学些相关的源码呢?如果要学 ES 和 Lucene 的源码,老师有啥好的建议吗?展开作者回复: 讨论题思考得很清楚!
关于roaring bitmap(简写RBM),你其实可以把它看做是一个倒排索引。对于一个32位的数,RBM将这个数的高16位当做key,然后将这个数存入对应的posting list中。posting list用位图表示(长度为2^16)。这样思考,会不会更好理解一些?
这也是我说的学习知识点要多对比,多拆解。
至于如何学好es和lucene的源码,一般来说有两种学习方式:一种是你先学好一个高效检索引擎的各种核心技术,然后这时候你去看es和Lucene的代码,你就会发现,其实这些代码就是为了实现这些设计而写的;另一种方式呢,就是从代码出发,遇到不明白的地方再去查资料,去弄明白为什么要这么实现。
这两种方式,我个人比较倾向先了解了大致原理,再去看代码。这样往往效率会更高。其实就像你自己写代码,先设计好以后再实现会更高效一样。- 2020-04-06讨论题:
对于三种求交集的结果个人认为用数组存储比较好。
原因:
最终的交集集合相对来说比较短,这个时候直接用数组比较好,可以直接通过遍历数组拿到返回结果。如果存储的是位图还需要这做转化,得不偿失。展开作者回复: 你的方法在大部分情况下是可行的。在你的方法中,隐含了一个假设:最终的交集集合比较短。如果假设成立,那么自然是使用数组最合适。
那么,你也可以想想,有没有可能最终的交集会比较长?如果我们一开始就发现结果会很长(可以评估概率),是不是一开始直接准备一个位图就好了?(举个例子,一个位图是满的,另一个位图半满,那么它们的交集个数是不是肯定超过4096了?)  2020-04-06今天竟然是两篇加餐,表示老师很努力,很nice!
2020-04-06今天竟然是两篇加餐,表示老师很努力,很nice!
讨论题: 主要考虑的点就是1. 怎么计算交之后该桶的元素个数 2. 新建continer,还是说原地计算。(先只考虑新建吧)
位图和位图 可能最后的结果是数组也可以是位图,可以根据两个位图本身的数量(n1 n2),并假设其均匀分布,n1 * n2/65536 大于等于 4096 则用位图,否则用数组,得到结果发现不是对应的continer,就要转换了。
数组和位图 ,数组和数组 这两个就相对简单了, 结果必然是数组。
问题: hash 表不能遍历这个问题,和链表结合不就可以了吗?为什么还要存一份原始的posting list。展开作者回复: 讨论题:分析得很好!先做预判再操作,如果预判错误了,那么就需要多做一次转换。先做预判是计算机系统中经常会涉及的一种设计和实现思想。在第二篇加餐中,是否要做集合分配律拆分也是基于预判的。包括数据库查询时,对SQL语句的优化也是会基于预判。
问题:哈希表+链表的结构的确可以(类似LinkedHashMap这样的结构)。不过链表的遍历效率不高,在链表较长的情况下,链表和哈希表求交不如用跳表法。因此,保留原始posting list最大的好处,是原始posting list可以是用跳表实现,也可以是用链表实现。有更多的适用性。(当然,如果原posting list是链表实现,其实就是你说的哈希表+链表了)




