03 | 哈希检索:如何根据用户ID快速查询用户信息?





讲述:陈东
时长18:56大小17.35M
使用 Hash 函数将 Key 转换为数组下标

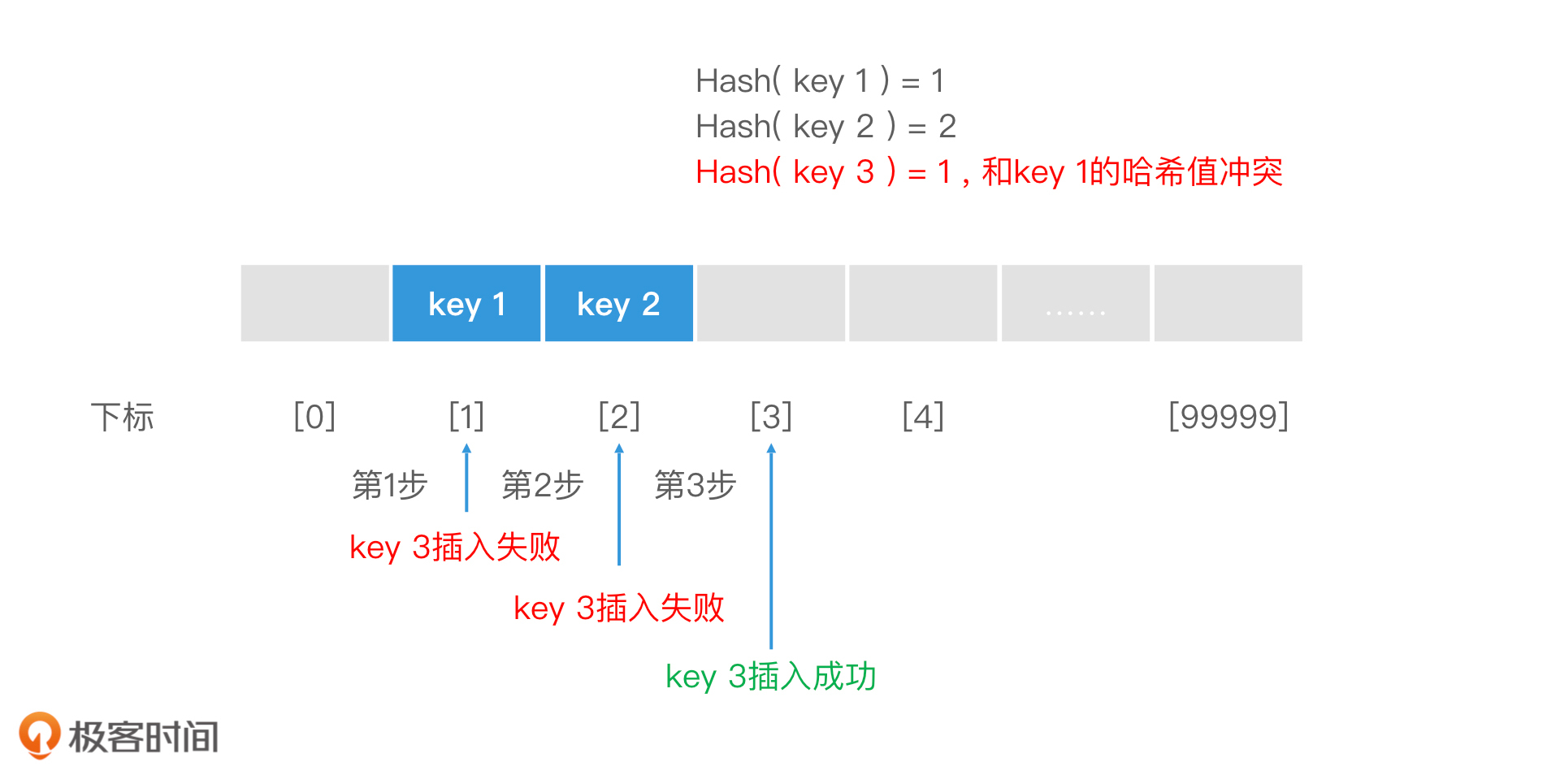
如何利用开放寻址法解决 Hash 冲突?
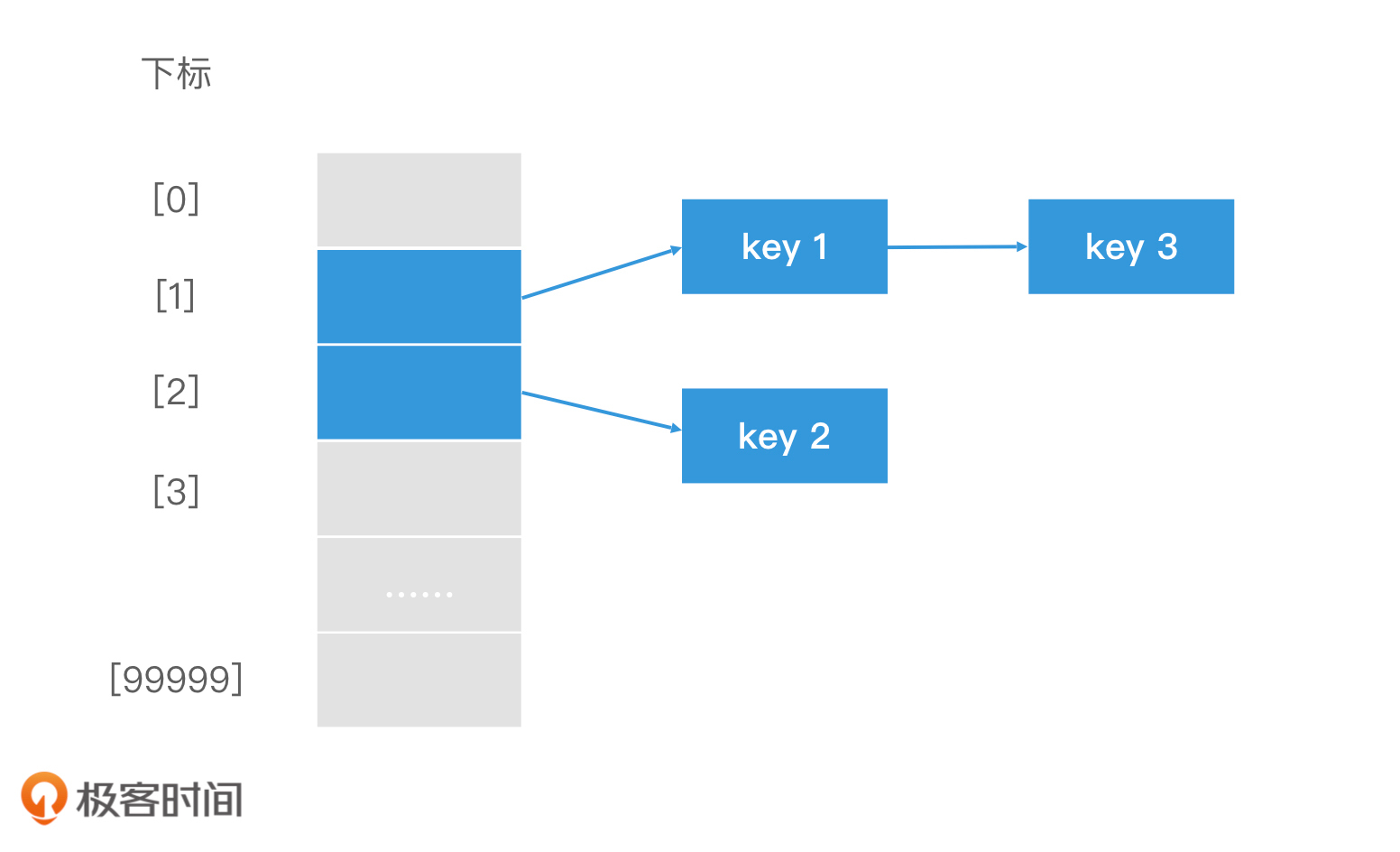
如何利用链表法解决 Hash 冲突?
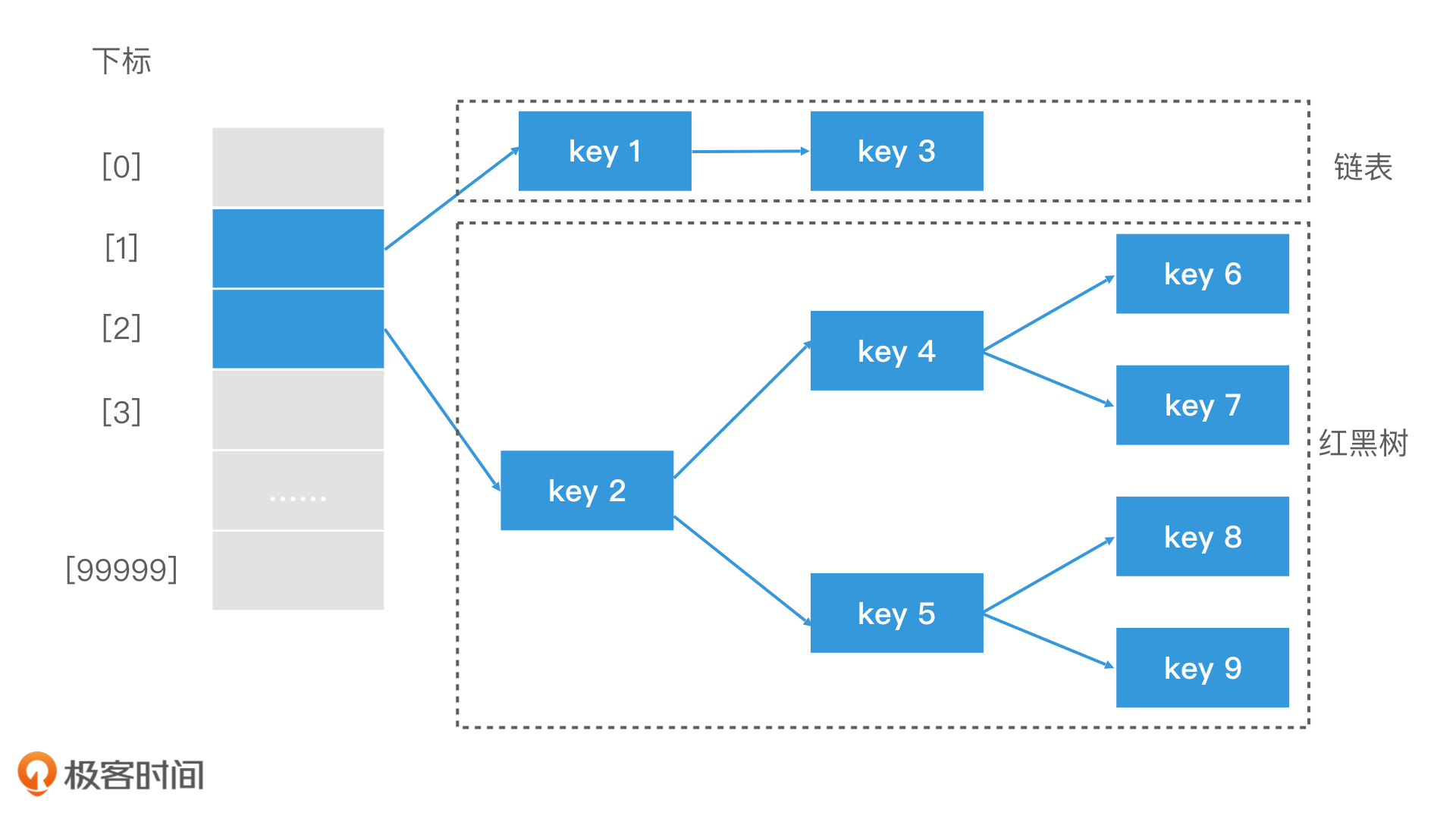
哈希表有什么缺点?
重点回顾
课堂讨论

精选留言(14)
 2020-03-28我这几天刚好看过一个C语言的哈希表实现源代码khash.h,它用的就是open addressing方法。 在删除元素的时候 不会真正的删除,会有一个flag记录状态。后续插入新的元素还能用。否则就会导致每次就要重新申请内存,rehash,计算量太大。链表法的话,删除的是对应的node ,时间复杂度是O(1) 所以删除很快展开
2020-03-28我这几天刚好看过一个C语言的哈希表实现源代码khash.h,它用的就是open addressing方法。 在删除元素的时候 不会真正的删除,会有一个flag记录状态。后续插入新的元素还能用。否则就会导致每次就要重新申请内存,rehash,计算量太大。链表法的话,删除的是对应的node ,时间复杂度是O(1) 所以删除很快展开作者回复: 是的。这种加一个flag记录状态的设计,其实在许多算法和系统中都有出现。是我们可以学习和掌握的一种方法。
1 2- 2020-03-27今天的内容权当回顾吧,期待后续的干货。展开
作者回复: 对于有基础和经验的工程师,可以当做回顾。同时也思考一下工业界的实际实现方案。
在后面,我准备写几篇加餐,补充更多的实践工程内容。让有经验的工程师更有收获。 1 2  2020-03-27不能,这样不能和数据不存在的情况区分,链表法就可以了,核心考量是冲突元素是否是聚集的。
2020-03-27不能,这样不能和数据不存在的情况区分,链表法就可以了,核心考量是冲突元素是否是聚集的。
hash 表中的hash 是一个将key 转化成数组下标的映射关系,我们这里只讲到这个转化尽可能的均匀的散列,但如果加上尽可能保留原始key 空间的距离大小信息(以前我学降维得出的结论是数据降维要做的事情是把你想从高维空间保留的信息尽可能在数据的低维表示上同样成立),是否就可以在一定程度上解决hash 完全没法做范围查询的缺陷,好早之前看过点局部敏感hash 的一些东东,想来应该可以结合。展开作者回复: 是的。直接删除会有问题。探查链条会被终止。
局部敏感哈希能在距离信息进行一定的保留,因此在近似检索中是一个方案。在进阶篇我会介绍。 2 2020-03-28链表法可以直接删除,开放寻址法不行。
2020-03-28链表法可以直接删除,开放寻址法不行。
开放寻址法在 hash 冲突后会继续往后面看,如果为空,就放到后面,这样会存在连续的几个值的 hash 值都相同的情况,但如果想删除的数据在中间的话,就会影响对后面数据的查询了
可以增加一个删除标识,这种添加删除标识的在数据库中也常用展开作者回复: 没错!这种增加一个删除标识的做法,其实在许多算法和系统的设计中都有出现。也是一种常见的设计思路。
1 2020-03-27通过开放寻址法是不可以简单的删除元素的,如果要删除的元素是通过寻址法找的存储下标,那么该元素所在的下标不是本身 hash 后的位置
2020-03-27通过开放寻址法是不可以简单的删除元素的,如果要删除的元素是通过寻址法找的存储下标,那么该元素所在的下标不是本身 hash 后的位置
链表法是可以的:因为元素本身的 hash 值和存储位置的下标 值是一致的展开作者回复: 哈希表在查找元素的时候,不是只看下标的,还要对比下标位置的元素值,相同才算找到。这也是为什么会有线性探查等方法。
不能直接删除的问题在于,直接删除会把探查序列中断。举个例子:有三个元素a,b,c的hash值是冲突的,那么探查序列会把他们放在三个位置上,比如1,2,3(探查序列是123),如果我们把b删了,那么2这个位置就空了。这时候,要查询c,探查序列就会在2的位置中断,查不到c。 1 2020-03-27开放寻址法从理论上讲应该也是可以删除的,不过稍微麻烦些,需要保证同一hash值删除的key前后元素串联性,以保证此hash值在删除当前key之后的元素能被寻址到,可以用特殊值代替,但是在检索时可能会遍历这些特殊值 效率上更低;而链表法则可以很好的支持删除展开
2020-03-27开放寻址法从理论上讲应该也是可以删除的,不过稍微麻烦些,需要保证同一hash值删除的key前后元素串联性,以保证此hash值在删除当前key之后的元素能被寻址到,可以用特殊值代替,但是在检索时可能会遍历这些特殊值 效率上更低;而链表法则可以很好的支持删除展开作者回复: 很正确。直接删除会打断探查序列。因此,需要加入特殊标志,表示这是被删除的。
1 2020-03-29开放寻址法的话应该是不可以的,因为一旦删除的话就会改变哈希表的长度,那样的话所有的元素的位置都会发生改变,不过删除的时候可以把这个位置赋予某个特定的值,用以表示此位置为空。
2020-03-29开放寻址法的话应该是不可以的,因为一旦删除的话就会改变哈希表的长度,那样的话所有的元素的位置都会发生改变,不过删除的时候可以把这个位置赋予某个特定的值,用以表示此位置为空。
对于链表法的话就不存在上述问题了,就和链表中删除某一个元素一样了。展开作者回复: 结论是正确的。不过删除元素并不会改变哈希表的长度。哈希表的长度是固定的。
不能直接删除的问题在于,直接删除会把探查序列中断。举个例子:有三个元素a,b,c的hash值是冲突的,那么探查序列会把他们放在三个位置上,比如1,2,3(探查序列是123),如果我们把b删了,那么2这个位置就空了。这时候,要查询c,探查序列就会在2的位置中断,查不到c。 2020-03-29期待后续的干货展开
2020-03-29期待后续的干货展开作者回复: 对于有经验的工程师而言,基础篇可以当做是梳理自己的知识点,并做总结和深入思考。比如说,哈希表结合遍历需求,是一个怎么样的数据结构?在实际场景中能怎么使用?(比如缓存)
此外,我会提供基础篇的加餐,你会发现,原来工业界的许多高效实现,都是基于基础篇中的知识完成的。- 2020-03-27哈希表的本质是一个数组,它通过 Hash 函数将查询的 Key 转为数组下标
----------------------------
这里有个以为 通过Hash 函数计算的结果一定是一个正整数吗? 还是说可以通过不同的进制,当做正整数展开作者回复: 本质是要把key作为数组下标。而数组下标是正整数。
只要能满足这个目的就好。  2020-03-27老师,如果开放寻址法是采用的二次探查或者双重散列解决冲突,可以直接删除嘛?
2020-03-27老师,如果开放寻址法是采用的二次探查或者双重散列解决冲突,可以直接删除嘛?作者回复: 即使是这样,也是会出问题的。直接删除会把探查序列中断。
举个例子:有三个元素a,b,c的hash值是冲突的,那么探查序列会把他们放在三个位置上,比如1,2,3(探查序列是123),如果我们把b删了,那么2这个位置就空了。这时候,要查询c,探查序列就会在2的位置中断,查不到c。
因此,真有删除需求的话,我们会通过将删除的元素做一个标志区别,而不是真正删除,这样就能保留探查序列了。 1 2020-03-27链表法可以删除,因为key对应的hash都映射到一个节点,所有的值都存在链表上。
2020-03-27链表法可以删除,因为key对应的hash都映射到一个节点,所有的值都存在链表上。
开放寻址不可以,无法判断key的hash被映射到哪里。展开作者回复: 结论是正确的。不过理由还不够充分。开放寻址是可以通过线性探查等方式确认映射位置的。问题在于,直接删除会把探查序列中断。举个例子:有三个元素a,b,c的hash值是冲突的,那么探查序列会把他们放在三个位置上,比如1,2,3(探查序列是123),如果我们把b删了,那么2这个位置就空了。这时候,要查询c,探查序列就会在2的位置中断,查不到c。
- 2020-03-27Hash表使用开放寻址法的时候,不能直接删除数据。直接删除的话可能形成查询无结果的假象,出现漏查的情况,链表法就不存在这个问题,但应该注意容错,可能会造成空值报错
作者回复: 是的。很细心。直接删除会造成探查链条被中断,导致本来后面可以查到的,但由于被中断返回了无结果。一般来说,会加一个状态位区分,而不是真正删除。
 2020-03-27老师,后边的课程全是理论吗,有没有讲讲实现某种查询的方案加工具啊,必竞学课的不完全是研究算法的。肯定也有像我这样用于应用的,展开
2020-03-27老师,后边的课程全是理论吗,有没有讲讲实现某种查询的方案加工具啊,必竞学课的不完全是研究算法的。肯定也有像我这样用于应用的,展开作者回复: 基础篇主要是介绍一些检索相关的重要数据结构和算法。不过这部分内容和课本上相比,会融入更多工业界的例子。
而在后面进阶篇的课程,重点会介绍各种业务中的查询解决方案了。- 2020-03-27不太理解算法,但感觉在有序的问题上,插入不是其优点,那么感觉删除也不是优点。链表在插上就改变个指针,那么删除肯定也没任何问题。展开
作者回复: 你的直觉很好。结论是正确的。不过理由不够充分哦。你可以再想想,包括好好看看前面两课。
其实对于工程师而言,基础还是很重要的。否则,如果使用ES或Lucene,但是不清楚支持它的技术,那么想优化可能都无从下手。









