05 | 倒排索引:如何从海量数据中查询同时带有“极”和“客”的唐诗?





讲述:陈东
时长14:12大小13.01M
什么是倒排索引?

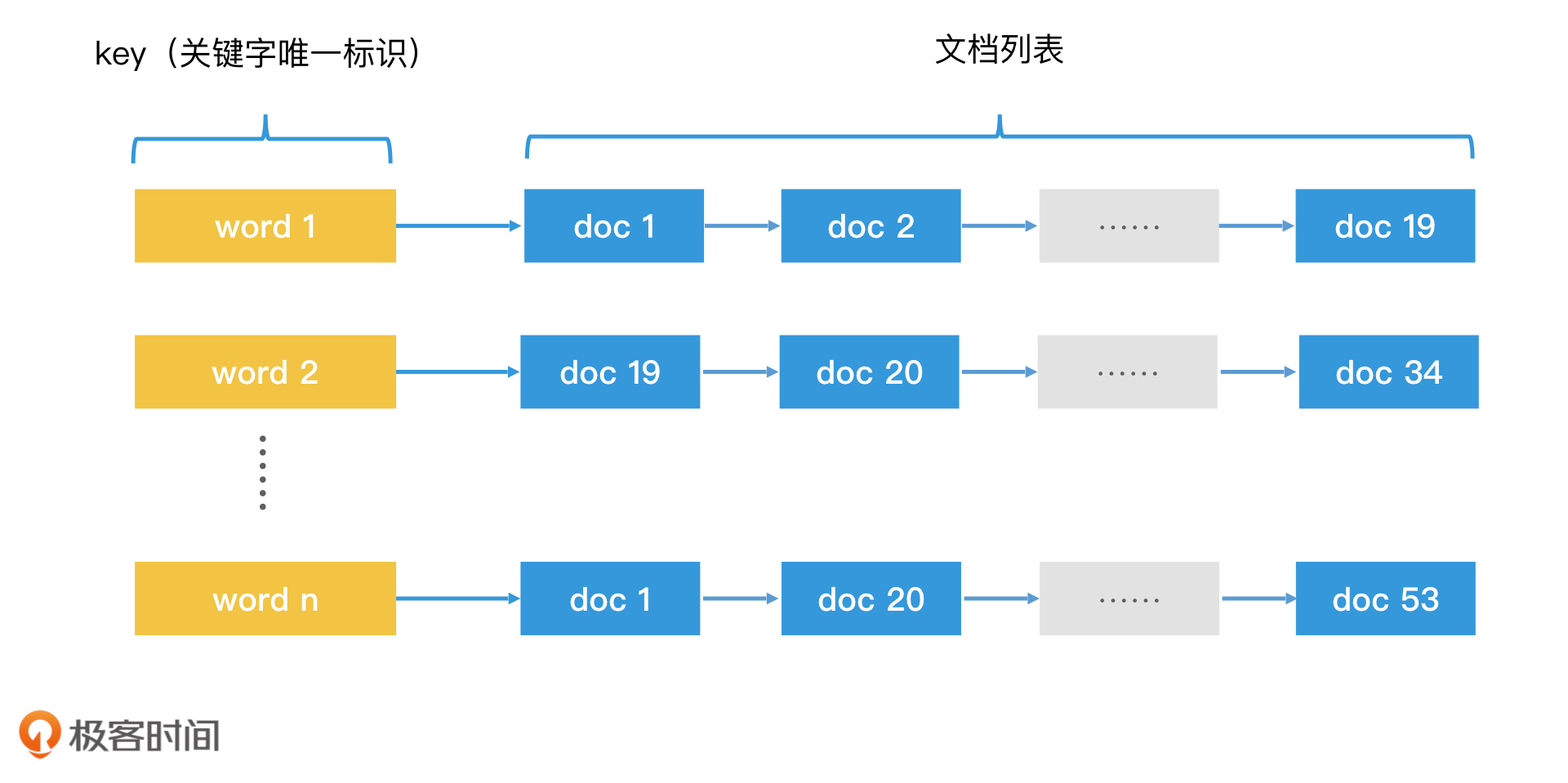
如何创建倒排索索引?
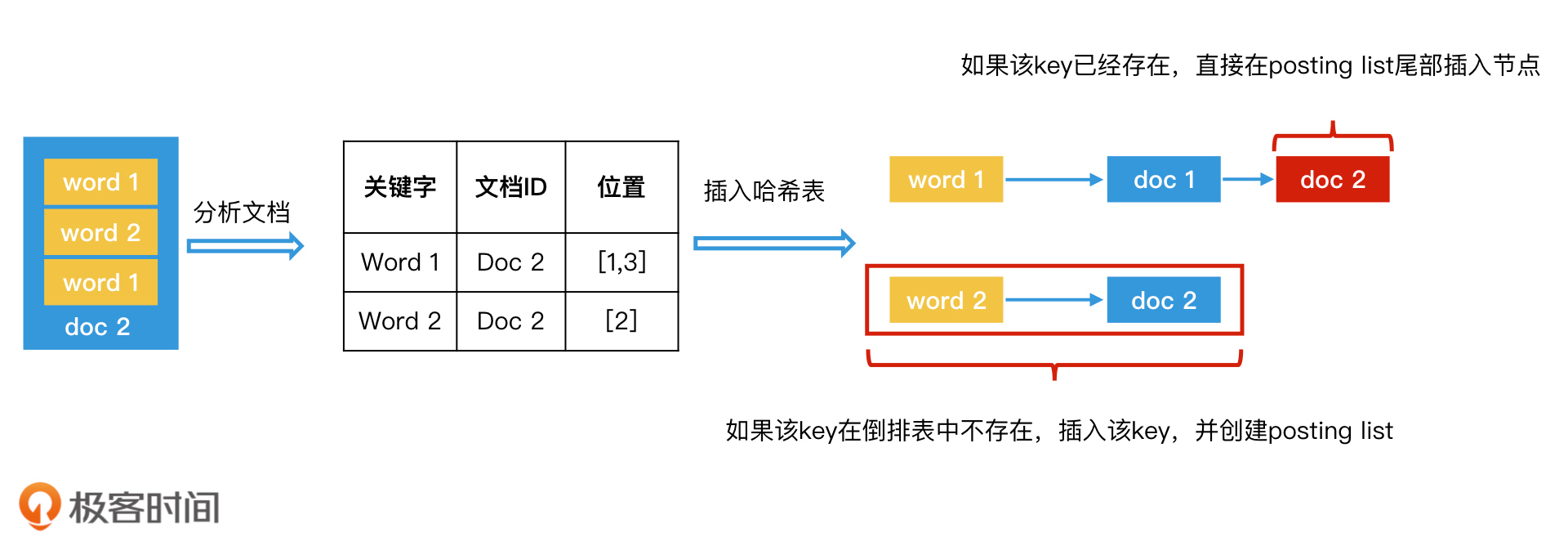
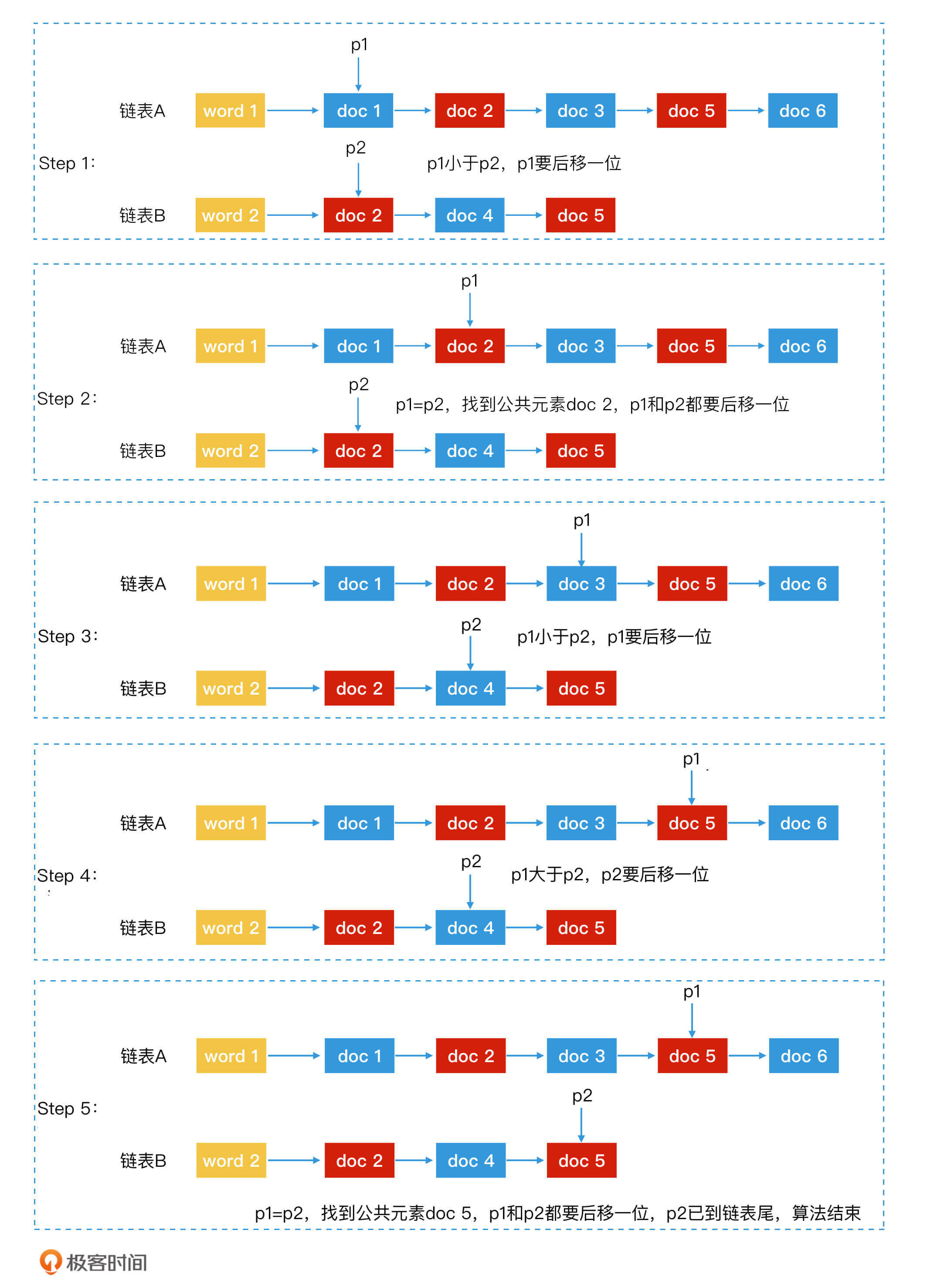
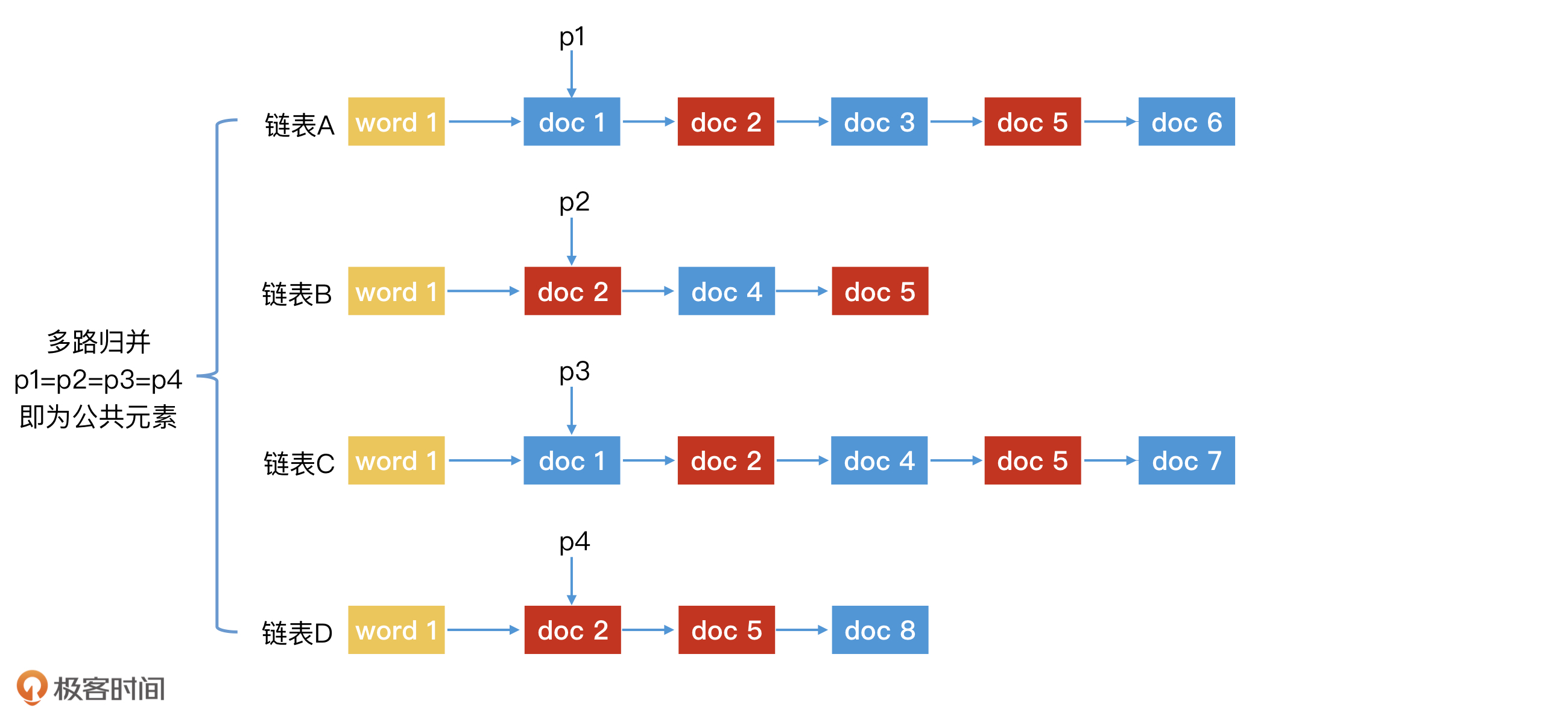
如何查询同时含有“极”字和“客”字两个 key 的文档?
重点回顾
课堂讨论

171614 3665 拼课微信(12)
 2020-04-01拉链的是倒排索引在数据量不大的情况下应该很好?如果数量上去了,要改成跳表了吧?如果跳表也支撑不下去了呢?展开
2020-04-01拉链的是倒排索引在数据量不大的情况下应该很好?如果数量上去了,要改成跳表了吧?如果跳表也支撑不下去了呢?展开作者回复: 你的问题我理解有两点:
1.检索效率问题。
2.存储空间问题。
关于检索效率问题,马上会出来两篇热腾腾的加餐,和你聊聊怎么进行倒排索引的检索加速。
关于存储空间问题,我接下来在进阶篇会开始介绍解决方案。 1 1 2020-04-01我能想到的方案是在数据库中建两张表,一张保存唯一索引的分词表,一张保存对应分词的文章id,这样是不是弱爆了。这样变成关系型数据库的查找了,而且外键表行数会暴增。脱离了老师说的hash. 老师你说的hash加链表我也看懂了,但持久话如何实现呢展开
2020-04-01我能想到的方案是在数据库中建两张表,一张保存唯一索引的分词表,一张保存对应分词的文章id,这样是不是弱爆了。这样变成关系型数据库的查找了,而且外键表行数会暴增。脱离了老师说的hash. 老师你说的hash加链表我也看懂了,但持久话如何实现呢展开作者回复: 其实你已经渐渐掌握了核心原理了!如果你能用数据库那就简单了,因为数据库中的全文索引功能,就是倒排索引的具体实现!
你只需要建立一张表,一列是文章id,一列是文章内容,然后指定对文章内容这一列建立全文索引,那接下来就可以用sql语句直接检索了。 2020-04-01老师对于邮件中敏感词检测适不适合用倒排索引那,用的话可能每个邮件都只要检测一次,不用直接搜索可能又找不到近义词展开
2020-04-01老师对于邮件中敏感词检测适不适合用倒排索引那,用的话可能每个邮件都只要检测一次,不用直接搜索可能又找不到近义词展开作者回复: 就像你说的,邮件只需要检测一次,因此对邮件做倒排索引并不适用。而且倒排索引也解决不了近义词问题。
邮件敏感词检测一般是这样的思路:
1.准备一个敏感词字典。
2.遍历邮件,提取关键词,去敏感词字典中查找,找到了就说明邮件有敏感词。
这里的核心问题是如何提取关键词和如何在敏感词字典中查询。
一种方式是用哈希表存敏感词字典,然后用分词工具从邮件中提取关键字,然后去字典中查。
另一种方式是trie树来实现敏感词字典,然后逐字扫描邮件,用当前字符在trie树中查找。
不过,这两种方式都无法解决近义词,或者各种刻意替换字符的场景。要想解决这种问题,要么提供近义词字典,要么得使用大量数据进行训练和学习,用机器学习进行打分,将可疑的高分词找出来。
其实这种近义词处理方案,和搜索引擎解决近义词和查询纠错的过程很像。我在搜索引擎那篇里面会介绍。 2020-04-01倒排索引的核心就是关键词的提取,也就是如何合理的对内容进行分词
2020-04-01倒排索引的核心就是关键词的提取,也就是如何合理的对内容进行分词作者回复: 分词是第一步,这样就有了倒排索引的key。至于有了倒排索引以后,如何提高检索效率,马上会有加餐为你揭晓
 2020-04-01老师,我有个疑问,为了实现根据关键词获取数据的功能,是不是需要在正常的表存储的基础上,再额外维护这样一个倒排索引?那这种在关键词不明确的情况下是不是就不会有这个东西了?
2020-04-01老师,我有个疑问,为了实现根据关键词获取数据的功能,是不是需要在正常的表存储的基础上,再额外维护这样一个倒排索引?那这种在关键词不明确的情况下是不是就不会有这个东西了?作者回复: 你的思考很好!的确是这样的。你可以回到开头背唐诗的场景。如果只要求给题目背内容,那么是只需要正排索引就好。不需要倒排索引。
倒排索引是用在需要根据部分信息或者属性去反查出数据主体的场景中。搜索引擎就是典型的应用场景,因为我们只知道我们想找什么关键字,而不知道哪些网页有这些关键字,因此需要倒排索引。数据库也一样,很多时候,我们去数据库中查找,也不是直接找id,而是用where去限定一些属性和字段。因此,你会发现,根据我们关心的属性去寻找主体,这种需求其实很常见,这些场景就可以用倒排索引了。- 2020-04-01老师,这样的倒排索引能介绍一些语言的工具名称吗?我见过的有. net中使用的盘古分词,其他语言有没有
作者回复: “倒排索引”本身不是一个工具,它更多是一种检索思想和技术。因此许多编程语言中没有现成的“倒排索引”,不过我们可以自己实现它:用一个哈希表进行key的查找,然后哈希表中的value存一个数组或链表作为posting list,这样你就可以用任何语言实现倒排索引了。
然后,你提到的“盘古分词”,那个是分词工具,类似的分词工具还有许多,比如说jieba,pkuseg,thulac等。
你完全可以找一个分词器,然后利用我文章中介绍的构建倒排索引的思路,自己做出来一个倒排索引。  2020-04-01老师在文章中提到了在构建倒排索引过程中要记录位置信息,我想可不可以同时检索 李 字和 白 字,然后判断二者的位置是否相邻?希望老师解答。展开
2020-04-01老师在文章中提到了在构建倒排索引过程中要记录位置信息,我想可不可以同时检索 李 字和 白 字,然后判断二者的位置是否相邻?希望老师解答。展开作者回复: 很好,你关注到了“李白”的分词问题了!
对于如何确定一个词,常见的做法是使用分词技术,将“李白”作为一个整体处理。这样检索性能也最好。
而你提的这个方案,是在分词技术无效的情况下,搜索引擎会采用的方案,它会根据位置信息进行短语查询,查出来的“李”和“白”是有序相邻的,优先级最高,位置越远的,优先级越低。通过描述,你也能体会到这样的效率的确没有直接处理一个整体高。因此,分词也是很重要的技术。- 2020-04-01posting list里面可以增加一个author的信息,word,author,pos,id。这样查完以后只需要做个集合检查即可。
作者回复: 很正确!posting list是可以根据需要放更多复杂的信息的,从而帮助我们解决更多复杂的需求。
不过也要注意一个度,如果把所有信息都放posting list中,依赖于集合检查,那就变成了遍历查找的效率了。因此,在合适的场景下,有时候也可以为author独立建一个新索引。 - 2020-04-01回答一下问题,支持作者查询其实就和查询内容一样,但是觉得新建哈希表比较合适,这样内容和作者查询在不同的posting list中,分别进行归并,查询完毕后,再根据作者和内容的权重进行打分,将分数最高放在结果首位。
我自己也有个问题,如果倒排索引非常大,内存不可能全部载入所有索引,那么如何边取部分索引再归并了?😏展开作者回复: 1.新建一个倒排索引是不错的方案。除了新建索引,还可以在posting list的记录中加域区分。比如用两个比特位,第一个表示是否是作者,第二个表示是否是内容。你所提到的按作者和内容权重进行打分的方案,用这个方法更容易实现。
2.内存放不下,有三个思路:1.通过压缩,全塞进内存;2.放磁盘上,用b+树或分层跳表处理;3.分布式,分片后全放内存。进阶篇中我会介绍这些方案。  2020-04-01感觉老师这个问题有点水到渠成的感觉,既然讲了倒排,一个很明显的答案就是把作者也当检索内容一样处理构建索引,对这种类似kv m 查的问题,这应该是最优的一个手段,具体的方案应该考虑如何压缩表示的问题,不明显的答案想不到哈哈哈。
2020-04-01感觉老师这个问题有点水到渠成的感觉,既然讲了倒排,一个很明显的答案就是把作者也当检索内容一样处理构建索引,对这种类似kv m 查的问题,这应该是最优的一个手段,具体的方案应该考虑如何压缩表示的问题,不明显的答案想不到哈哈哈。
既然提到索引给大家分享一个观点,索引是什么,从机器学习的角度上看,它其实是检索信息(比如这边的关键字,作者等等)到数据本身位置信息的一个映射关系,pos =f(x)。这就转变成一个机器学习怎么输入x 预测pos 的问题了!(观点来自jeaf dean组的一篇论文)
最后老师的口音真牛逼!!!哈哈哈😂展开作者回复: 哈哈,用“口音牛逼”作为我的属性,就可以通过这个标签将我检索出来了。😁
明显的答案水到渠成,那我们来加入一点细节吧。许多诗的内容里都有李白的名字,比如杜甫就写了许多思念李白的诗。那我们用作者“李白”构建倒排索引,和用内容中的“李白”做倒排索引,会不会有冲突?会不会直接把杜甫的诗给召回了?
ps:机器学习构建索引就是我们现在在做的事情 1 2020-04-01在关键字为key所在文档为posting list的基础上,再加以作者名为key,posting list为作者诗集的索引
2020-04-01在关键字为key所在文档为posting list的基础上,再加以作者名为key,posting list为作者诗集的索引作者回复: 很好,你提到了“以关键字为key”和“以作者名为key”,我们是可以用两个不同的key来区分作者“李白”和内容中的“李白”。
这样就能解决“明明想搜的是李白写的诗,结果出来了杜甫写李白的诗”这样的问题 2020-04-01作者看做是文档的一个属性,建立属性倒排索引展开
2020-04-01作者看做是文档的一个属性,建立属性倒排索引展开作者回复: 很好。对于属性建立倒排索引是正确的。
你可以再思考一些细节:如果有一些诗的内容里也有“李白”这个关键词,比如杜甫的诗。
那么作者“李白”对应的posting list,和内容中的“李白”对应的posting list是否会冲突?可以怎么处理?








