07 | NoSQL检索:为什么日志系统主要用LSM树而非B+树?





讲述:陈东
时长15:13大小13.94M
如何利用批量写入代替多次随机写入?
如何保证批量写之前系统崩溃可以恢复?
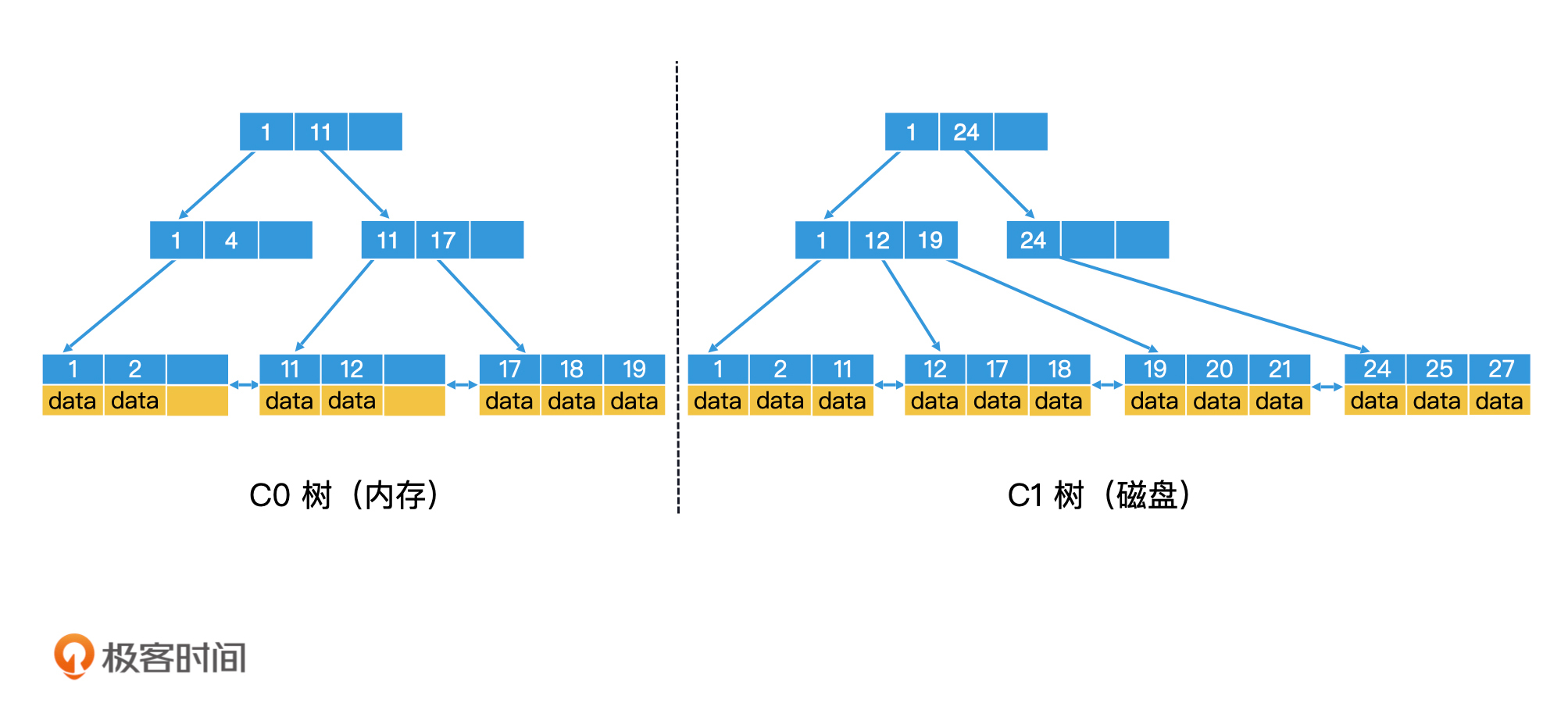
如何将内存数据与磁盘数据合并?
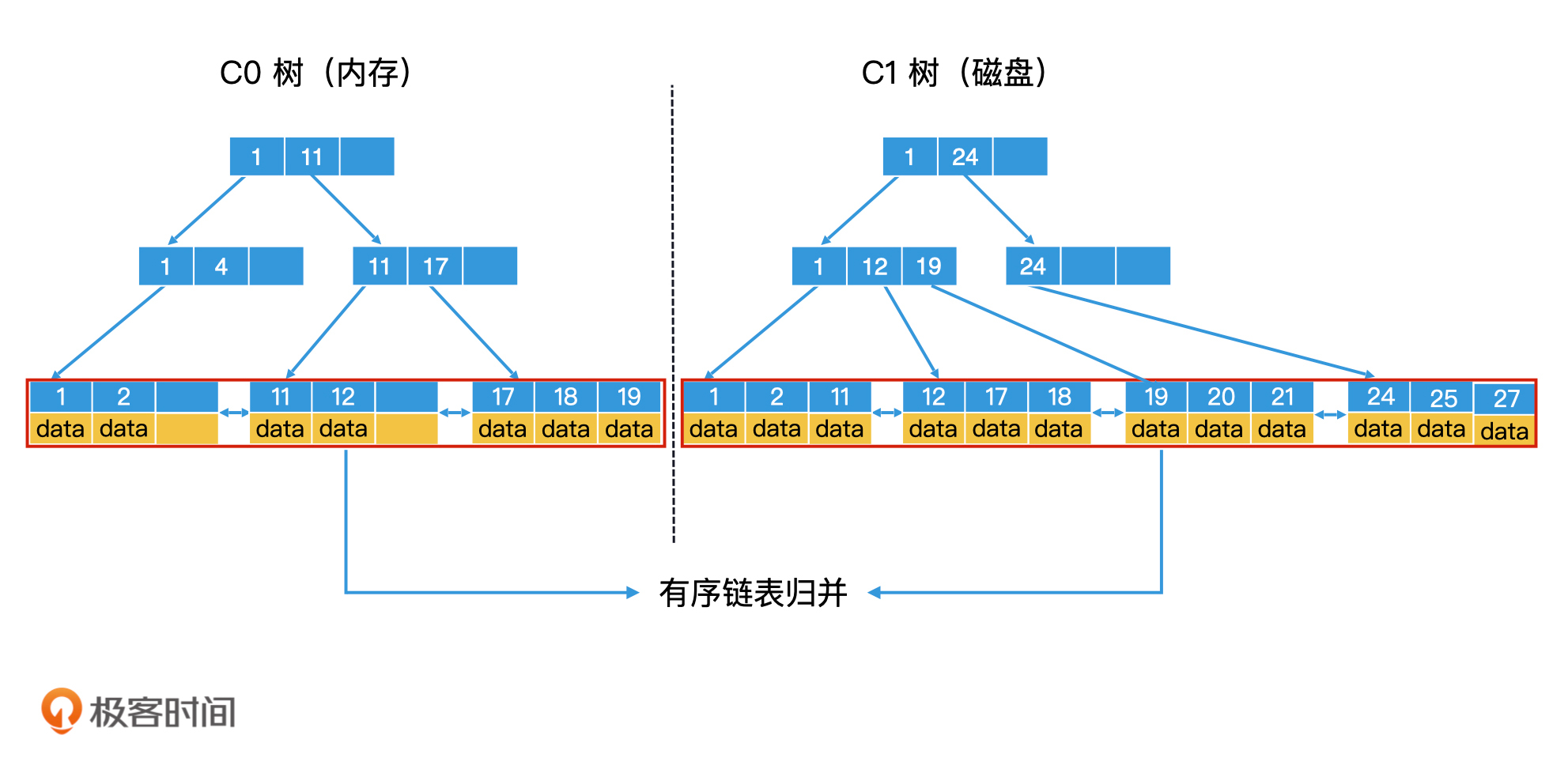
LSM 树是如何检索的?
重点回顾
课堂讨论

精选留言(12)
 2020-04-11为了性能内存中的树至少有两棵吧展开
2020-04-11为了性能内存中的树至少有两棵吧展开作者回复: 你提到了性能问题,的确是这样的。在高性能的lsm树实现中,不仅仅是内存中要有两棵,磁盘上还要有多棵。
具体工业界是怎么真正实现一个高性能的lsm树,后面我会再具体介绍。 1 1 2020-04-10感觉取决于系统需要提供什么样的功能,如果系统需要提供高效的查询不需要范围scan那么C0用hashmap都可以,如果需要scan那么平衡树或者skiplist比较合适。leveldb是使用skiplist来实现的,这里的checkpoint主要目的是定期将数据落盘后用来对log文件进行清理的,使得系统重启时不需要重放过多的log影响性能展开
2020-04-10感觉取决于系统需要提供什么样的功能,如果系统需要提供高效的查询不需要范围scan那么C0用hashmap都可以,如果需要scan那么平衡树或者skiplist比较合适。leveldb是使用skiplist来实现的,这里的checkpoint主要目的是定期将数据落盘后用来对log文件进行清理的,使得系统重启时不需要重放过多的log影响性能展开作者回复: 你说的很对,取决于使用场景。有的系统的确是使用哈希表的。还有使用红黑树和跳表的都有。
1 2020-04-10请问,如果wal所在的盘和数据在同一个盘,那怎么保证wal落盘是顺序写呢,我理解也得寻道寻址
2020-04-10请问,如果wal所在的盘和数据在同一个盘,那怎么保证wal落盘是顺序写呢,我理解也得寻道寻址作者回复: 你这个问题很好!我提炼出来有三个点:
1.wal的日志文件能否保证在物理空间上是顺序的?
这个是可以做到的。日志文件都是追加写模式,包括可以提前分配好连续的磁盘空间,不受其他文件干扰。因此是可以保证空间的连续性。
2.wal的日志文件和其他数据文件在一个磁盘,那么是否依然会面临磁头来回移动寻道寻址的问题?
这个问题的确存在,如果日志文件和数据文件在同一个盘上,的确可能面临一个磁头来回移动的情况。因此,尽量不要在一个磁盘上同时开太多进程太多文件进行随机写。包括你看lsm的写磁盘,也是采用了顺序写。
3.如果第二个问题存在,那么wal依然高效么?
wal依然是高效的。一方面,如果是wal连续写(没有其他进程和文件竞争磁头),那么效率自然提升;另一方面,往磁盘的日志文件中简单地追加写,总比处理好数据,组织好b+树的索引结构再写磁盘快很多。 1 1 2020-04-10考虑的点
2020-04-10考虑的点
1 随机和顺序存取差距不大
2 什么样的有序结构适合高并发的写入
对于2,必须插入的时候只影响局部,这样上锁这样开销就只在局部细粒度上,如果是树可能存在需要调整树高的各种旋转或者分裂合并操作。对于1,在说不用像b树那样降低树高,底层数据节点搞比较大的块,可以充分利用指针这种随机读取的力量,当然块太小有内存碎片之类的问题,以及jvm老年代跨代引用新生代之类问题,所以hbase中跳表的实现是基于chunk的。
感觉自己好像逻辑不是很通,自己还想的不够透彻,其实也在思考全内存的数据库和基于b树这样的数据库在它的缓存可以容纳全部块,不用换入换出,这两种情况下全内存数据库的优势在哪里。展开作者回复: 全内存数据库的确是一个研究热点。Redis的广泛流行也是这个潮流的一个例子。
b+树即使能全部缓存到内存中,但你思考一下它插入删除的效率(分裂合并节点),它不会比红黑树这些结构效率高。因此,纯内存的环境下,红黑树和跳表这类结构更受欢迎。 1- 2020-04-11不知道为什么我昨天发布成功的评论没有被通过,可能 bug了,那我重说一次😭。
问题,前面的文章提到 B 树是为了解决磁盘 io 的问题而引入的,所以 B 树自然不适合做内存索引,适合的是红黑球和跳表。
当然也有例外,如小而美的 Bitcask 就选择了哈希表作为内存索引,是学习 Log-structure 的最佳入门数据库。展开作者回复: 很好!你提到了bitcask,它是用哈希表作为内存索引的。其他的一些nosql实现,还有选择红黑树和跳表的。因此你会发现,对于内存中高效检索的技术选型,不同应用会根据自己的需求,选择我们在基础篇介绍过的适用技术。
 2020-04-11请问两个关于检查点check point的问题。
2020-04-11请问两个关于检查点check point的问题。
1.检查点也是要落盘,和WAL一样的位置么?
2.在数据删除和同步到硬盘之后会生成检查点,还有其它情况会生成检查点么?作者回复: 1.check point的信息是独立存在的,和wal的日志文件是不同文件。
2.check point的触发条件可以有多个,比如说间隔时长达到了预定时间,比如说wal文件增长到一定程度,甚至还可以主动调用check point相关命令强制执行。- 2020-04-10你好,这里还有个问题:如果是ssd,顺序写和随机写的差异不大,那么是否还有必要写wal, 毕竟写wal相当于double写了数据,那直接就写数据是否性能还会更好呢
作者回复: 这是一个好问题!对于SSD,这些理论和方法是否依然有效?答案是yes。
考虑这么两点:
1.SSD是以page作为读写单位,以block作为垃圾回收单位,因此,批量顺序写性能依然大幅高于随机写!
2.SSD的性能和内存相比依然有差距,因此,先在内存处理好,再批量写入SSD依然是高效的。  2020-04-10当内存的C0 树满时, 都要 把磁盘的 C1 树的全部数据 加载到内存中合并生成新树吗? 我感觉这样性能不高啊。
2020-04-10当内存的C0 树满时, 都要 把磁盘的 C1 树的全部数据 加载到内存中合并生成新树吗? 我感觉这样性能不高啊。
还有就是 类型日志系统,都是天然按照时间排序;这样的话 ,就可以直接把 C0 树的叶子节点直接放到 C1 树的叶子节点后面啊,没有必要在进行合并生成新树了展开作者回复: 你提了一个非常好的问题!把c1树的全部叶子节点处理一次的确效率不高,因此实际上会有多棵不同大小的磁盘上的树。包括工业界还有其他的优化思路。后面会介绍。
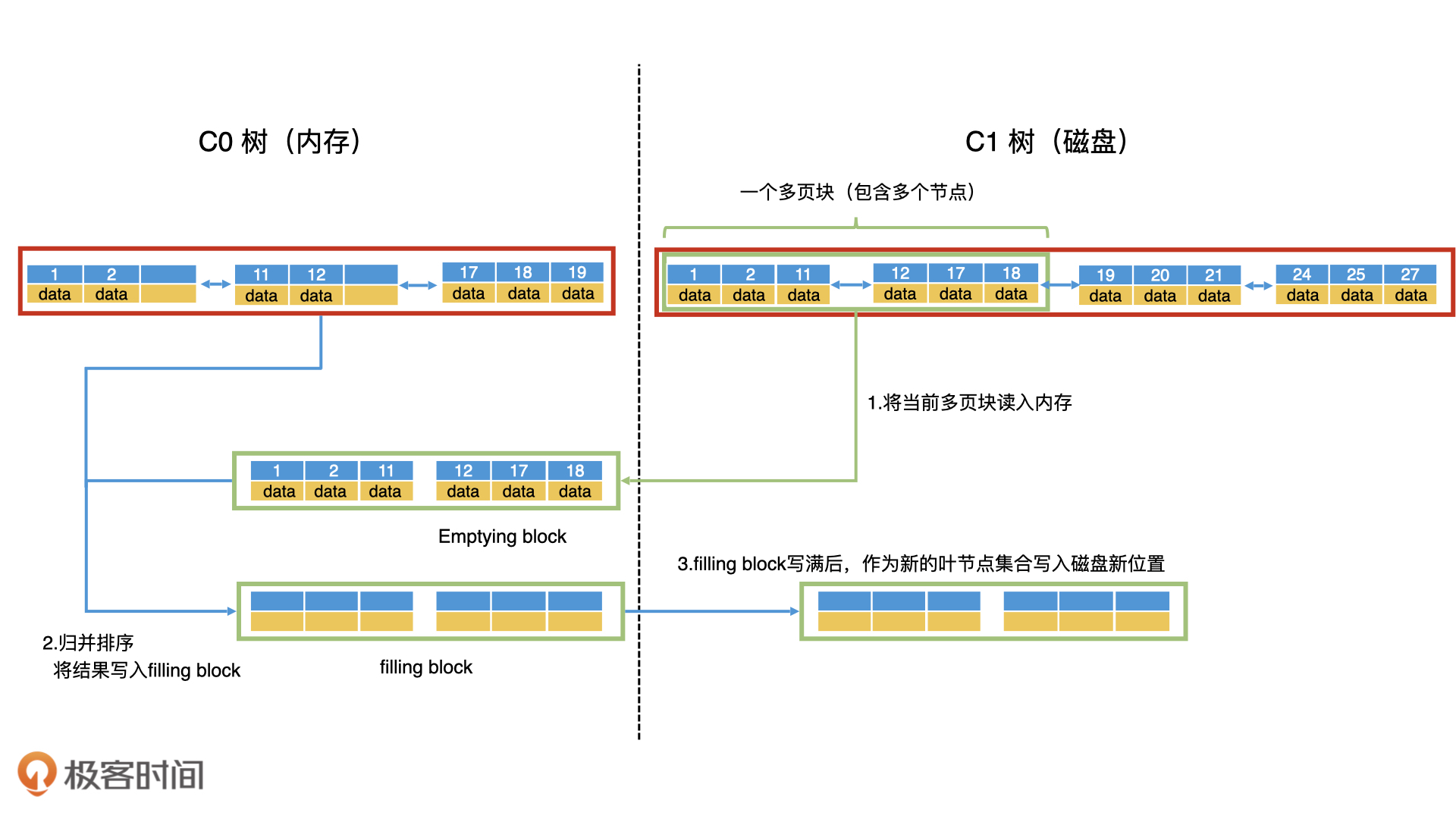
此外,直接把c0树的叶子节点放在c1树后面,这样的话叶子节点就不是有序的了,就无法高效检索了。- 2020-04-10填充块写满了,我们就要将填充块作为新的叶节点集合顺序写入磁盘,
这个时候 填充快写的磁盘位置会是之前C1 叶子节点 清空块的位置吗? 还是另外开辟有个新的空间,当新的树生成后,在把旧的C1树 磁盘数据空间在标记为删除?展开作者回复: 是新的磁盘空间。因为c1树要保证在磁盘上的连续性,如果是利用原c1树的旧空间的话,可能会放不下(因为合并了c0树的数据)。
- 2020-04-10对于 对数据敏感的数据库,基本上都会采用 WAL 技术,来防止数据在内存中丢失, 比如 MySQL 的 redo log展开
 2020-04-10B+树数据存储是以块为单位的,读到内存也是以块为单位,一个块里面如果数据多了顺序查找也不是太快。
2020-04-10B+树数据存储是以块为单位的,读到内存也是以块为单位,一个块里面如果数据多了顺序查找也不是太快。
内存存储我觉得应该选择跳表,他的查找、插入、删除都跟树一样,只是空间上会多一些消耗,他对范围查找的支持是其他内存数据结构一大优势。
另外,我感觉文章中有把c0写成c1的地方,不知道我理解对不‘和普通的 B+ 树相比,C1 树有一个特点’展开作者回复: 在内存数据库里面,Redis是一个典型的代表,它的确就是使用跳表的。
另外两点:
1.b+树块内的查找,可以使用二分查找,而不是顺序查找,这样能加快检索效率。
2.你说的是否“c0和c1树写错”的地方,这个的确没有写错哦,你可以仔细想一想,为什么c1树有这个特点“叶子节点是全满的”。 1 2020-04-10思考题
2020-04-10思考题
对于c0树因为是存放在内存中的,可以用平衡二叉树或跳表来代替 B+ 树展开作者回复: 是的。如果你有关注一些内存数据库,你会发现,有好些是使用跳表和红黑树来实现的。比如Redis。
可见,b+树不是万能的。我们理解了存储介质的特性以后,能帮助我们在合适的场景做出正确的技术选型。







