09 | 索引更新:刚发布的文章就能被搜到,这是怎么做到的?





讲述:陈东
时长16:48大小15.39M
工业界如何更新内存中的索引?
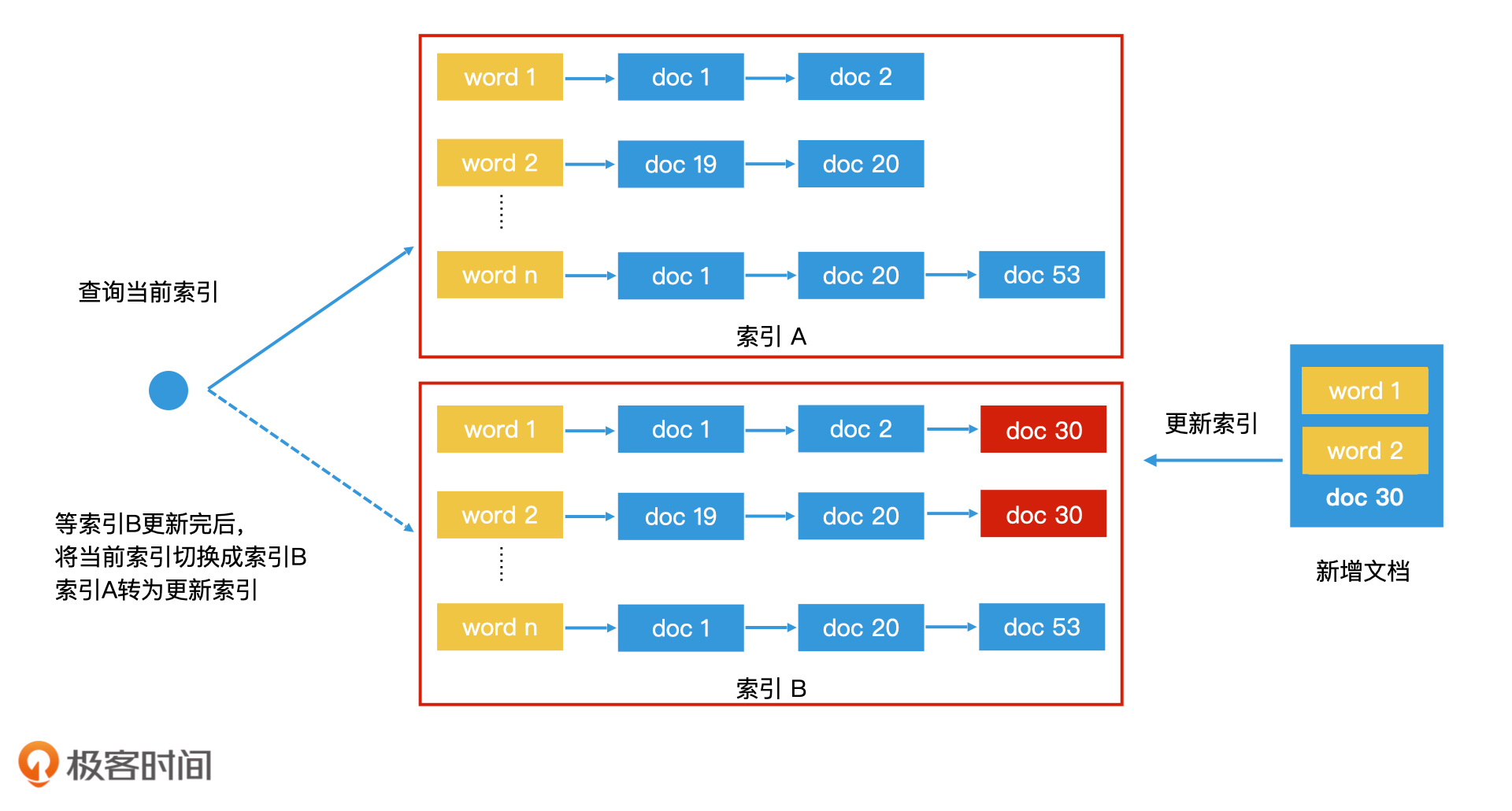
如何使用“全量索引结合增量索引”方案?
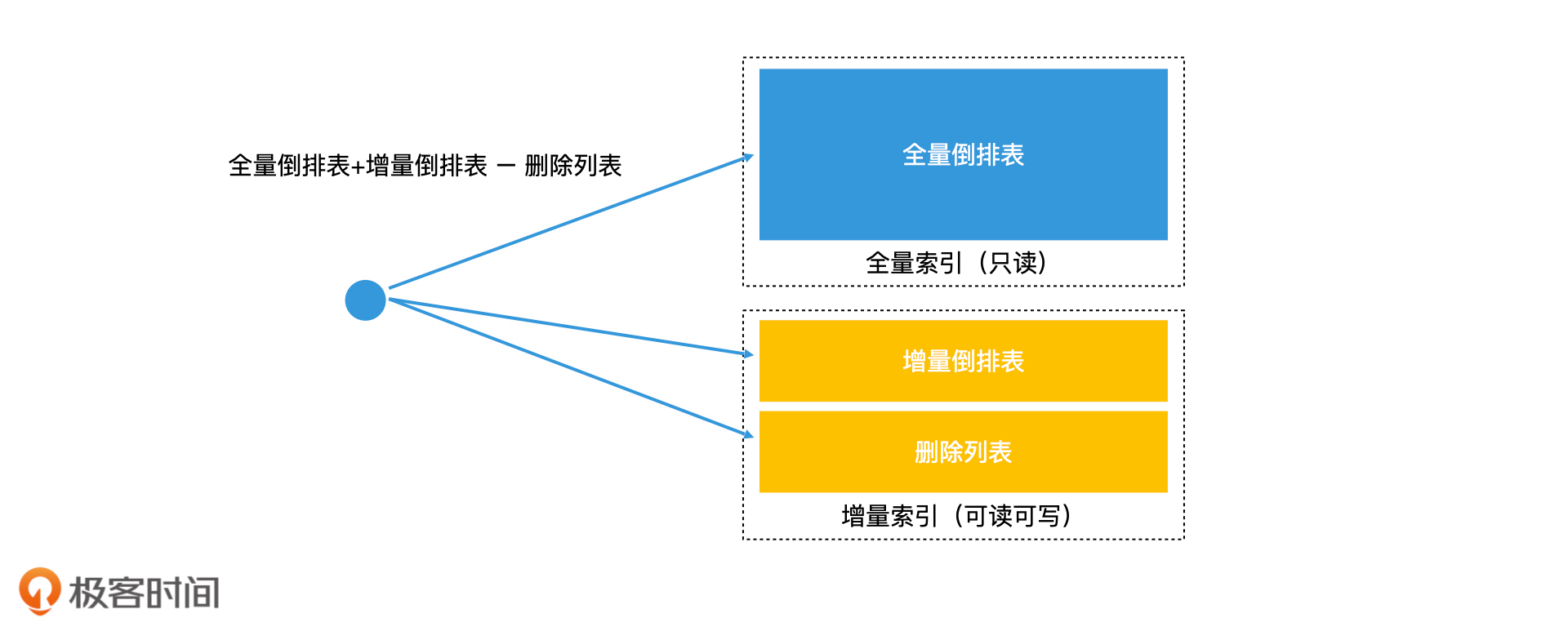
增量索引空间的持续增长如何处理?
1. 完全重建法
2. 再合并法
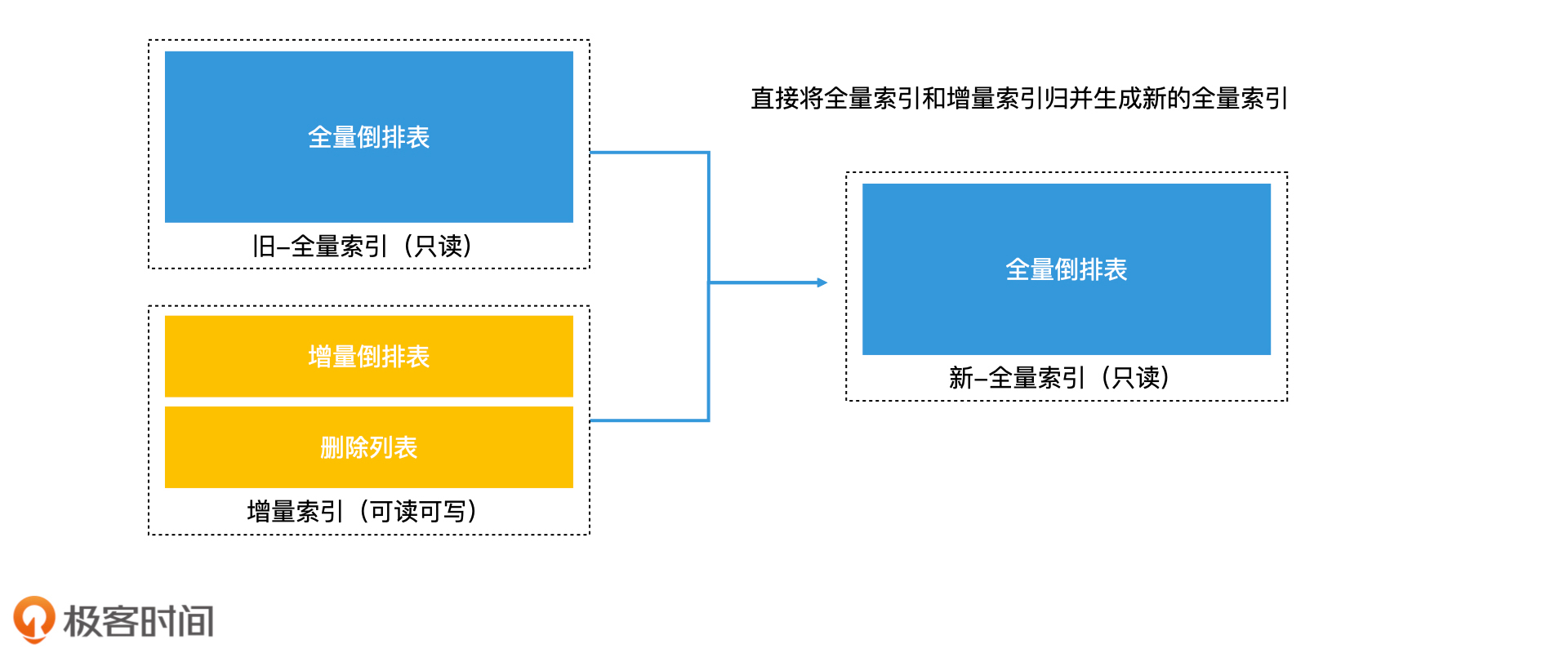
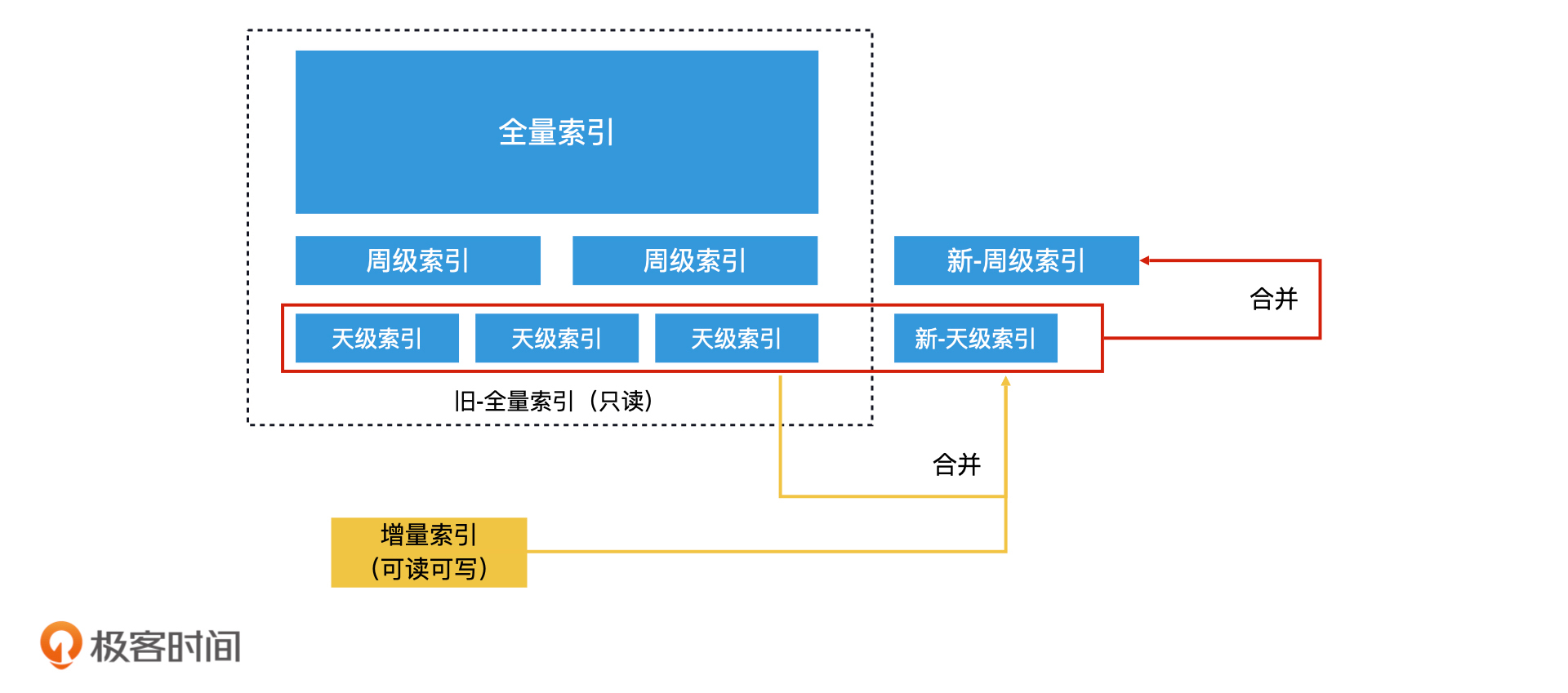
3. 滚动合并法
重点回顾
课堂讨论

精选留言(12)
 2020-04-15对于结尾的问题:我在补偿一下,除了上面说的原因还有就是,一个文档 会有多个 key, 也不可能对文档包含的每个 key 进行文档标记展开
2020-04-15对于结尾的问题:我在补偿一下,除了上面说的原因还有就是,一个文档 会有多个 key, 也不可能对文档包含的每个 key 进行文档标记展开作者回复: 综合你前一条一起回复,你说到了两个点上:
1.倒排索引和kv不一样,posting list元素很多,每个元素都加标记代价太大。
2.一个文档可能会影响多个key,因此每个文档都要修改标记的话,读写操作会很频繁,加锁性能下降。
此外,还有一点是,加上标记也没啥用,在posting list求交并的过程中,依然要全部留下来,等着最后和全量索引合并时才能真正删除。这样的话不如直接用一个delete list存着,最后求交集更高效。 2 2020-04-21双缓存机制有个疑问,假如A更新了一个数据1,B也需要更新数据1,这个如何保证呢?
2020-04-21双缓存机制有个疑问,假如A更新了一个数据1,B也需要更新数据1,这个如何保证呢?作者回复: 是这样,双缓存机制的设计理念是读写分离,一个索引只负责写,另一个索引只负责读。因此,不会存在你说的两个索引同时被写的情况。
1 2020-04-15看不懂滚动合并机制,老师能结合具体数据分析下,例如我今天增加了几个网页,有倒排索引关键字的value都要加上这个网页,这个滚动合并的流程是咋样的。展开
2020-04-15看不懂滚动合并机制,老师能结合具体数据分析下,例如我今天增加了几个网页,有倒排索引关键字的value都要加上这个网页,这个滚动合并的流程是咋样的。展开作者回复: 滚动合并机制的确是最复杂的一种。它的核心思想是“解决小索引和大索引合并的效率问题,避免大索引产生大量无谓的复制操作”。而解决方案则是“在小索引和大索引中间加入中索引进行过渡”。
这个设计方案其实会很常见。比如说在lsm树那一课,我说了“假设只有c0树和c1树”,而实际情况是c1树会非常大,合并效率会很低,因此lsm树的设计中就有着多棵不同大小的树。包括leveldb的实现,也会有着多层索引。因此,这是一个值得我们学习和掌握的方法。
至于你举的这个例子,结合文中的内容,使用滚动合并的流程是这样的:
1.今天增加的网页会先存在内存的增量索引中。
2.增量索引满了,要开始合并。
3.增量索引和当天的天级索引合并(天级索引不大,所以合并代价小)。
4.当天级索引达到了7天时,可以将多个天级索引合并,变成一个新的周级索引。
5.当有多个周级索引的时候,全量索引会和多个周级索引合并,生成一份新的全量索引。(不过,一般这一步会用重新生成全量索引来代替,你可以理解为为了保证系统的稳定性,需要定期进行索引重建。就像系统要进行定期重启一样)。 1 2020-04-16如果在doc的正排字段中做标记删除是不是也可以呢? 这样等各个索引进行合并的时候,看doc对应的正排的删除标记,如果是删除状态那边直接丢掉展开
2020-04-16如果在doc的正排字段中做标记删除是不是也可以呢? 这样等各个索引进行合并的时候,看doc对应的正排的删除标记,如果是删除状态那边直接丢掉展开作者回复: 你的想法很好,其实是有可能的。本质上,你是复用了正排表,让它承载了删除列表的功能。在最后posting list合并的时候,通过查正排表完成过滤(其实就是加餐一中说的哈希表法:将删除列表变成了哈希表)。
在系统比较简单的时候,这样使用是OK的。不过当系统足够复杂的时候,我们需要将不同功能和数据进行合理的划分,倒排检索和正排查询有可能是两个不同的环节和模块(包括中间可能还有其他环节,比如抽取特征,打分计算等)。因此从这个角度出发,复杂系统才会抽象出删除列表这个对象,这样就可以不依赖于正排表,从而完成了系统架构的解耦设计。 2020-04-15第一时间看到这个思考题,我没啥思路,看了大家的留言和老师的回复,学到了,把老师的回复总结了起来
2020-04-15第一时间看到这个思考题,我没啥思路,看了大家的留言和老师的回复,学到了,把老师的回复总结了起来
为什么在增量索引中,对于要删除的数据没有像 LSM 树那样一样在索引中直接做删除标记,而是额外增加一个删除列表?
1.倒排所以和 kv 存储还是有不一样的地方,倒排索引的 posting list 元素有很多,每个元素都做删除标记代价较大
2.一个文档可能存在多个 key,所以一个文档都要修改删除标记的话,读写很频繁,加班性能下降
3.加标记也没什么用处,因为在对 postlist 做合并的过程中,数据都是全部存在的,只有在最后和全量索引合并时才进行真正的删除操作,这样可能还没有把要删除的元素放到一个删除列表中,在最后做交集更高效展开作者回复: 总结得很认真。相信你学完这一课后,再去看es中的segment的处理就会很轻松了,比如segment的生成和合并,还有.del文件存储删除列表等。
此外,你还可以思考索引更新这一块,你们当前系统的实现方案是否合理,是否有优化空间等。- 2020-04-15在滚动合并方案中,查询也要一级一级的进行查询, 先查增量索引---> 天级索引----> 周级索引---> 最后是权量索引。 这个的话查询的链路增加了好多,查询的效率会降低多少?
作者回复: 这些是可以并行查找的。而不是串行。
而且一般来说,以现在的机器处理能力,周级索引其实也可以不用的,这样也能减少系统复杂度。
因此一般系统实现就是:
增量索引+ 天级索引+全量索引 三个索引并行检索,再合并结果。 - 2020-04-15为什么在增量索引的方案中,对于删除的数据,我们不是像 LSM 树一样在索引中直接做删除标记,而是额外增加一个删除列表?
这个我认为 ,删除的数据相对全量的数据是非常少的,如果用删除标记,那么全部的数据都要进行标记,这样大量的没有删除的数据都会有个未删除的标志,极大的浪费空间资源展开作者回复: 在另一条下面统一回复你了。
 2020-04-15对这个问题,老师故意在文章里说的很含糊,只说了个记录删除列表的思路😜。
2020-04-15对这个问题,老师故意在文章里说的很含糊,只说了个记录删除列表的思路😜。
lsm之所以可以和删除标记一起存,核心在于类似kv存,删除标记和对应的v是共享k的,所以要拿是会一起拿出来,就可以判断数据这个时候存在不存在,相当于拿到了值的变迁历史。
而这个场景,删除文档,对文档集合而言,也可以添加个删除标记,但对于索引而言,它涉及到很多关键字的poslist里对它的指向,这要一个个都加上吗,如果删除的不多,显然还不如最后返回的时候做一个全局的deletelist判断。展开作者回复: 哈哈,的确说得没那么透,只说了“怎么做”,但没说“为什么”。因此才在课后讨论题让大家想想为什么。
你说到了很重要的一点,kv只有一个值,但倒排表是一整个posting list,所以修改代价会大。
另一方面,即便是使用double buffer技术对增量索引做无锁更新,但增量索引检索过程中,依然要把所有被删除的文档保留到最后,再和全量索引做合并。
那既然所有的标记都要保留到最后一步,不如直接在最后一步用一个delete list来求交集更快,逻辑也清晰。 2020-04-151.如果增加一个删除标记,相当于增量索引的每个内容都有这样一个标记,随着增量的数量变大,内存占用会更高。
2020-04-151.如果增加一个删除标记,相当于增量索引的每个内容都有这样一个标记,随着增量的数量变大,内存占用会更高。
2.利用删除列表就不会有这样的问题,同样可以避免加锁。展开作者回复: 这两点都很好。
的确posting list里每个元素都加标记,这个代价会远大于lsm这种只存一个元素kv的场景。
此外,一个文档被删除,它可能会影响很多key和posting list,这个读写加锁代价不小。
还有,即使使用double buffer实现增量索引,但是这个标记也没什么用。我们在增量索引中求交集和并集时,依然要保留所有的元素,这样和全量索引的结果合并时才不会出错。因此提前打上标记并不能加快检索效率。不如最后记录一个delete list,然后快速求交集处理掉。- 2020-04-15按照索引的高性能选择,全量索性是只读的,而增量索引和删除项是可读可写的,所以不会选择在索引上添加删除项,会拉低系统效率。展开
作者回复: 你很好地吸收了读写分离的思想。全量索引上肯定是不能加删除项的。不过可读写的增量索引上面能否加上删除标记呢?你可以想一想。
提示:
1.加的话是否有性能损失。
2.不管有没有性能损失,加上后,求检索结果的过程是怎么样的?加上这个标记和单独记录一个删除列表相比有帮助么?
你在思考以后,可以再看看我的回复。  2020-04-15在滚动更新中,周索引往全量索引更新的时候,需要加锁操作么?
2020-04-15在滚动更新中,周索引往全量索引更新的时候,需要加锁操作么?作者回复: 这一步我没有画,不过你可以沿着前面天级索引和周级索引合并的思路思考一下,包括总结时我强调的“读写分离”去想想,我相信,你应该可以得到“不要加锁”这个结论的。
这里我也补充一点,就是周级到全量索引的合并,其实由于隔的时间已经很久了,因此,很多时候我们会直接完全重建全量索引,一方面,重建时间是足够的,另一方面,也等于定期给系统“重启”,保证系统的稳定性和正确性。 2020-04-15用删除列表而不是打删除标记,可以避免对增量索引加锁
2020-04-15用删除列表而不是打删除标记,可以避免对增量索引加锁作者回复: 避免加锁操作的确是一个考虑因素。新删除一个文档,这个文档里可能有很多key,如果要打删除标记,就意味着这些key和posting list都要执行加锁操作,这个代价的确会比较大。
而且,即使我们使用double buffer,对于增量索引不加锁,那么你可以想想处理过程,如果对于增量索引的posting list中的文档打上删除标记,在进行交并操作的时候,所有的文档都依然要被留下!因为增量索引的结果需要和全量索引结果合并,如果增量索引的结果没有保留删除标记,那么合并时会出错。
既然删除标记要在增量索引处理过程中一直保留,那不如单独记录来得方便。








