14 | 空间检索(下):“查找最近的加油站”和“查找附近的人”有何不同?





讲述:陈东
时长17:00大小15.57M
直接进行多次查询会有什么问题?
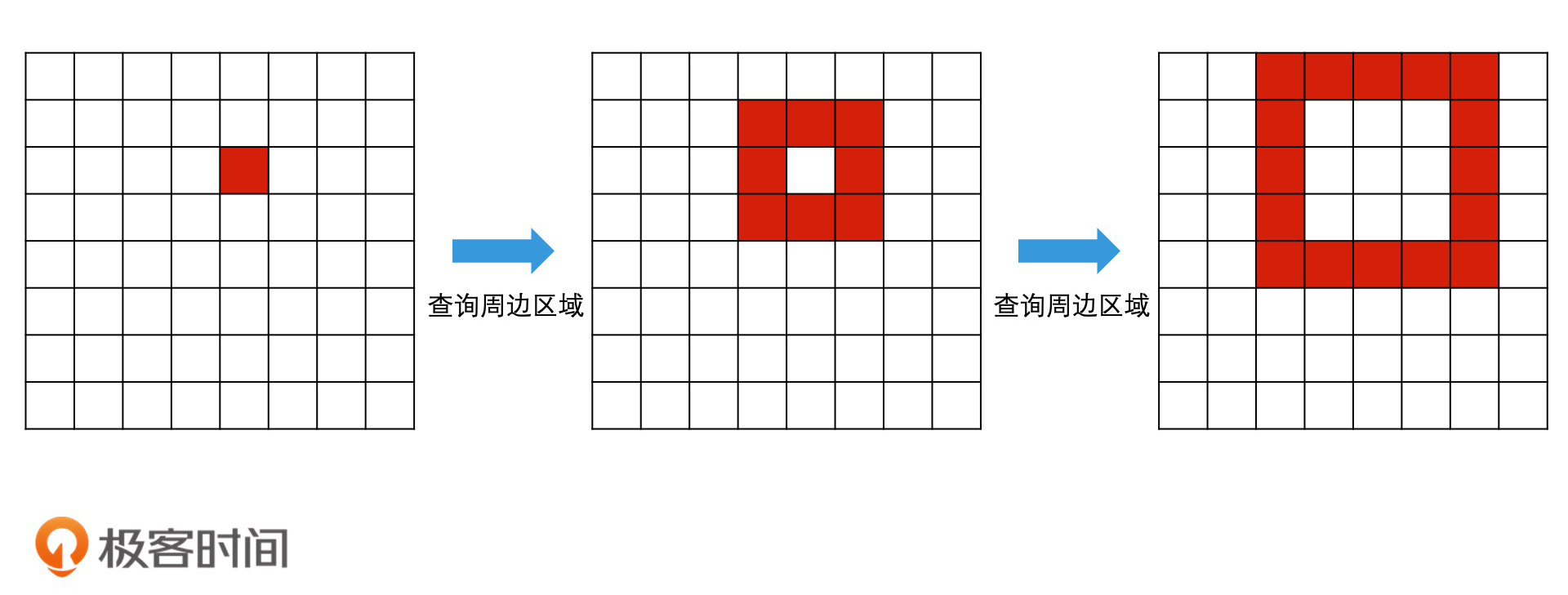
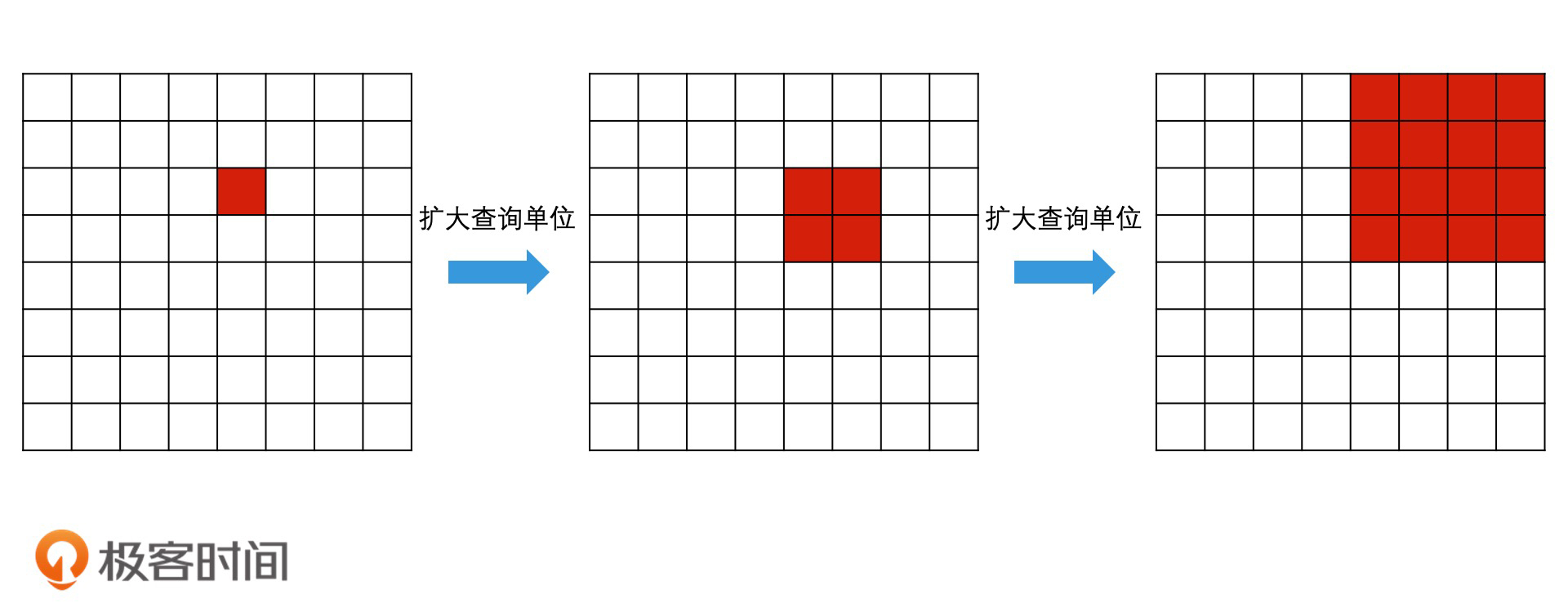
如何利用四叉树动态调整查询范围?
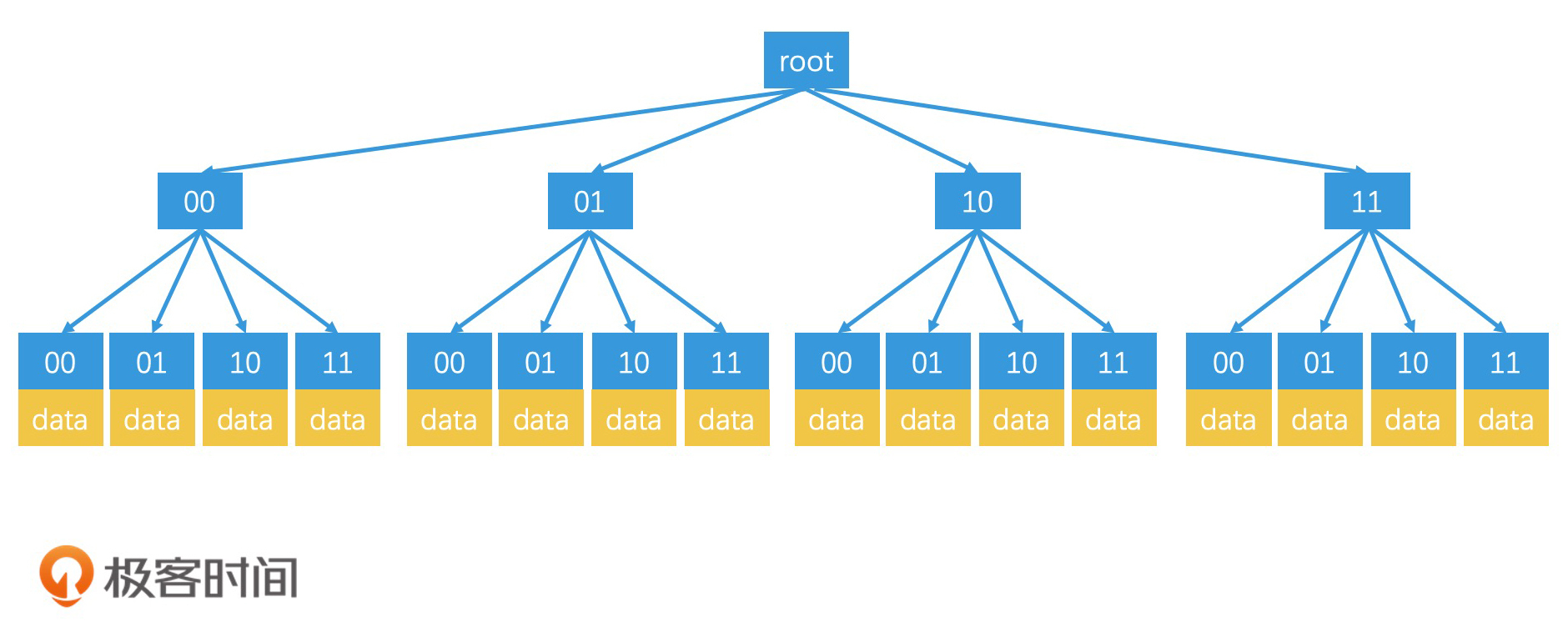
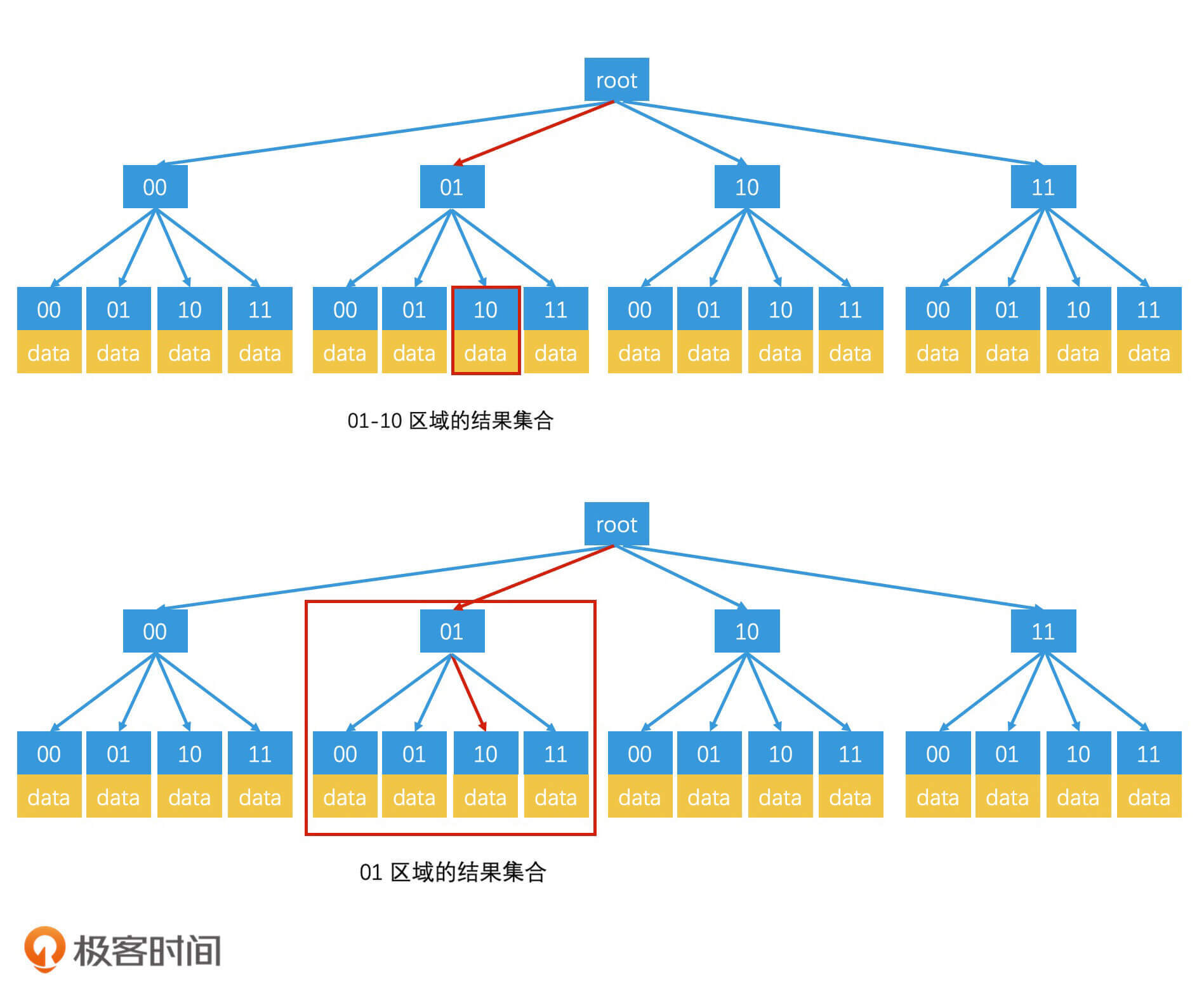
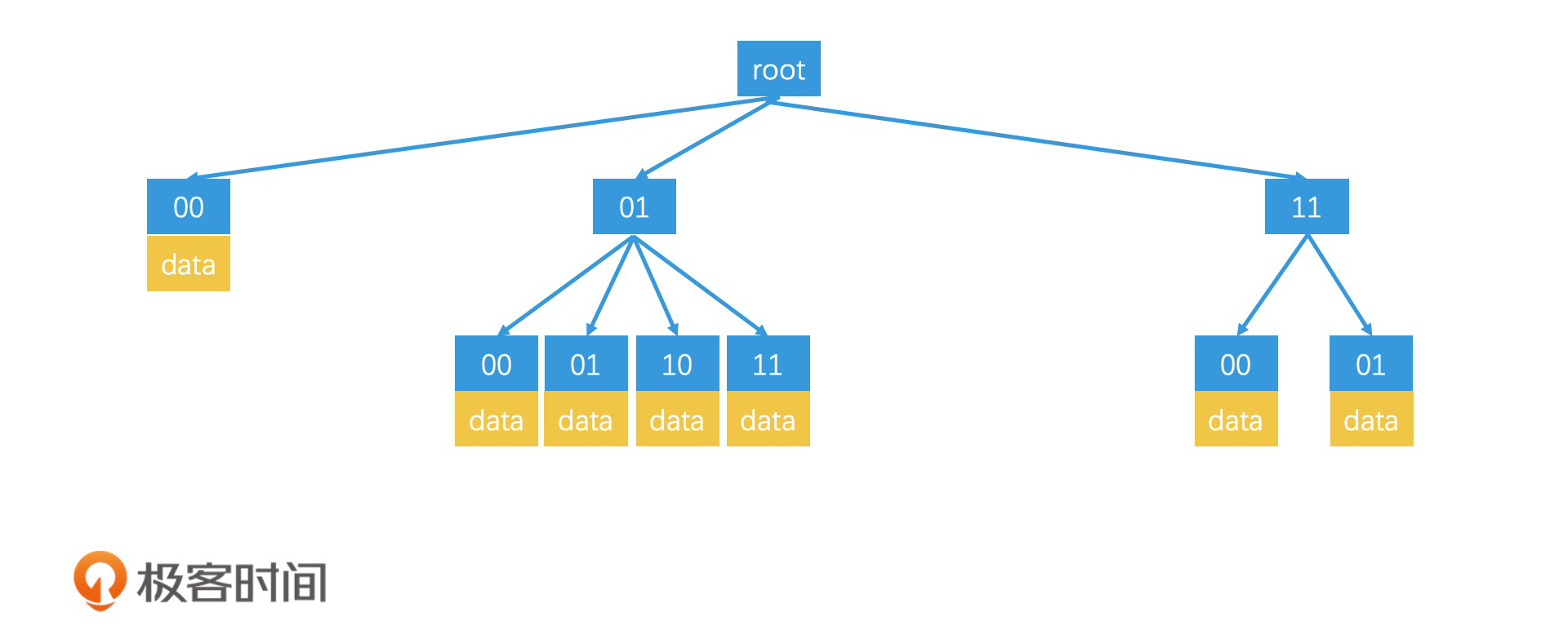
如何利用非满四叉树优化存储空间?
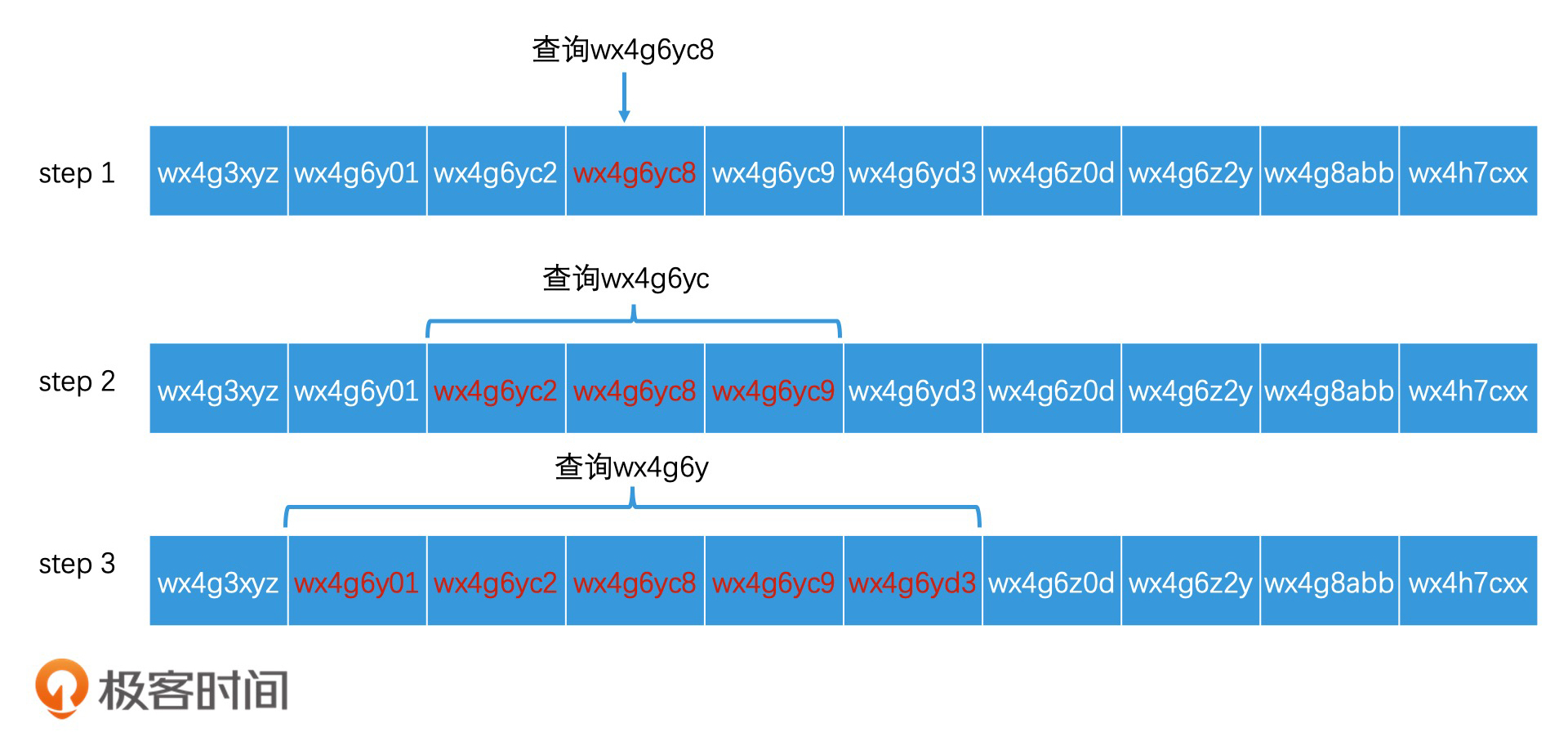
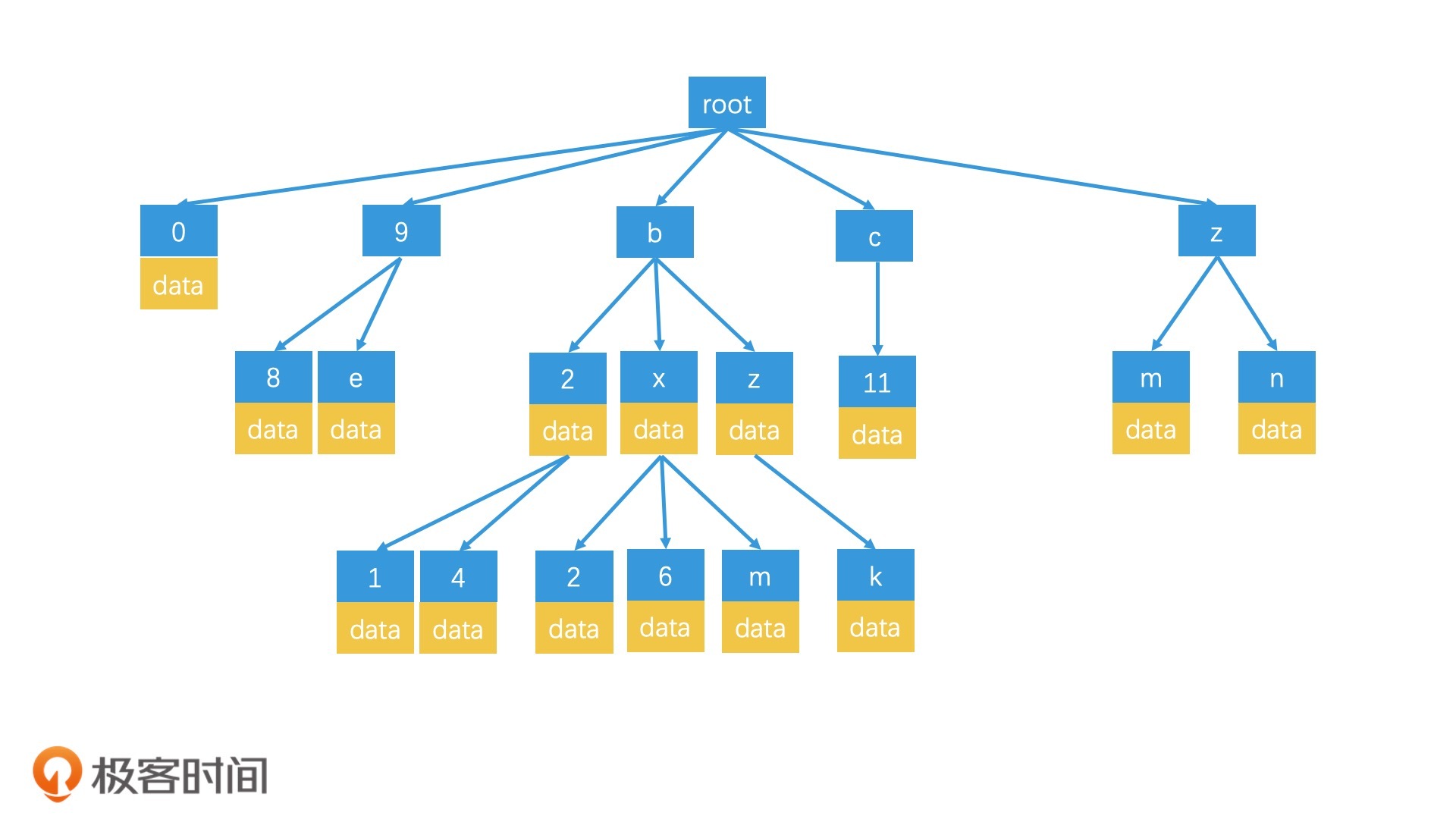
如何用前缀树优化 GeoHash 编码的索引?
重点回顾
课堂讨论

精选留言(7)
 2020-04-27在GeoHash通过去掉最后一位编码的方式来扩大搜索范围,比如这次搜索了四个编码块,下次搜索16个编码块。在这16个编码块里有上次已经搜索的四个编码块,请问老师,这里应该有去重处理吧?来避免重复查询。
2020-04-27在GeoHash通过去掉最后一位编码的方式来扩大搜索范围,比如这次搜索了四个编码块,下次搜索16个编码块。在这16个编码块里有上次已经搜索的四个编码块,请问老师,这里应该有去重处理吧?来避免重复查询。
想到一个方式就是对于已经搜索过的hash编码标记下,避免重复搜索。展开作者回复: 你说的对,肯定会有去重处理。不过16个编码块是覆盖4个编码块的,因此我们直接使用16个编码块的检索结果就好了。否则对四个编码块再进行去重比较,其实代价是差不多的。
2 1 2020-04-28当前地址的 GeoHash 编码为 wx4g6yc8,这个根据上节学的编码规范,前4个字母代码纬度,后面四个代表经度,如果去掉最后一个字符 不是代表纬度不变,经度的范围扩大 2 ^ 5 倍,这样的范围不应该是一个长方形吗? 怎么会是图中的正方形呢?
2020-04-28当前地址的 GeoHash 编码为 wx4g6yc8,这个根据上节学的编码规范,前4个字母代码纬度,后面四个代表经度,如果去掉最后一个字符 不是代表纬度不变,经度的范围扩大 2 ^ 5 倍,这样的范围不应该是一个长方形吗? 怎么会是图中的正方形呢?
----------------
作者回复: 你看得很仔细。Geohash由于是5个比特位为一个字符,因此的确是去掉一个字符的时候,范围形状是长方形。再去掉一个字符,就又变成正方形。
不过如果你再仔细看的话,你会发现这个图示是以二进制区域编码为例子的,因为它每次扩大只是四倍,而不是32倍。32倍的图不好画。。
我看看让编辑在图示里加上说明优化一下吧。
-----------------------
老师,这里我在追问一下,在上一条下面评论怕你看不见:
也就是经度和纬度的字符交替的去掉吗?我看文中是连续去了最后的两个字母,也就是只操作了经度,纬度没变。还有就是下面Trie树是不是也不应该按照字母的顺序形成一个链了?也应该是经度,纬度交替的形成了?展开- 2020-04-28当前地址的 GeoHash 编码为 wx4g6yc8,这个根据上节学的编码规范,前4个字母代码纬度,后面四个代表经度,如果去掉最后一个字符 不是代表纬度不变,经度的范围扩大 2 ^ 5 倍,这样的范围不应该是一个长方形吗? 怎么会是图中的正方形呢?展开
作者回复: 你看得很仔细。Geohash由于是5个比特位为一个字符,因此的确是去掉一个字符的时候,范围形状是长方形。再去掉一个字符,就又变成正方形。
不过如果你再仔细看的话,你会发现这个图示是以二进制区域编码为例子的,因为它每次扩大只是四倍,而不是32倍。32倍的图不好画。。
我看看让编辑在图示里加上说明优化一下吧。 2 - 2020-04-27在四叉树从当前子节点去搜索附近子节点时,需要去到上层父节点。如果子节点以双向链表类似B+树,是否可行呢?展开
作者回复: 你这个思考很好。四叉树能否使用b+树类似的双向链表呢?我来说说我的理解。
如果是满四叉树的话,那么我们可以将所有叶子节点使用双向链表连接起来。当我们查询到一个叶子节点不满足k个结果时,我们需要扩大范围,那么我们可以沿着左右两个方向去扩展。但是,我们是要扩展多少才OK呢?我们并不好判断新节点和当前节点的位置关系。你可以结合我文中的满四叉树的例子看看,如果查询到的节点是0110,其实离它最近的点可能是在1001区域中(见13讲中的区域编码图),它需要往右边走三个元素才能到达这个节点。因此,遍历并无法判断当前节点和新扩展节点之间的关系。不如递归便捷。
而如果是非满四叉树的话,叶子节点不是一个层级的,并且节点还会分裂。进行链表管理会更加麻烦。 - 2020-04-27想到一种情况一个节点不一定生成四个叶子结点,比如某个城市的加油站都集中在某个小范围区域内,在上层节点看分裂子节点数量可能小于四。展开
作者回复: 是的。极端情况就是所有插入的数据都属于一个小区域,那么根节点就不需要分裂出其他分叉了。
 2020-04-27刚看到四叉树那段,就想着这不前缀树嘛,看到前缀树,想空间检索怎么能木有kd-tree,然后r-tree呢,我放心了,没有了哈哈哈。
2020-04-27刚看到四叉树那段,就想着这不前缀树嘛,看到前缀树,想空间检索怎么能木有kd-tree,然后r-tree呢,我放心了,没有了哈哈哈。
以我的认知看,到了高维,先不是数据结构高效不高效的问题,先是高维诅咒引发的相似度不再有效问题,大家都很相似肿么搞,于是才有一帮人搞什么流形学习,在高维空间找低维表示,知识的世界就怎么无限延展开,我要老了=_=,哈哈哈,这个落点😜
最后回答下问题,这跟插入数据的分布情况有关,就比如根节点0011 0010 1001 1000,分裂,那根节点就可以多出两个二层节点00 10,然后一个节点指向0011 0010 ,另一个指向1001 1000,这种做法就偏b树的分裂方式,当然也可以优先对前缀最多的子节点集合进行分裂下推,都是动态分裂的策略问题,看你想达到什么效果,比如数据库b+树的分裂不会是两边子节点一样多,而是会让id 大的那边空一点,考虑的是id 经常是自增的,所以一般再有元素插入就在id 大的那边。展开作者回复: 哈哈,的确四叉树的这个用法和思路其实和前缀树很像。从这个角度来看,空间检索和字符串检索是有相似的地方的。
k-d树必须有,不过就像你说的,到了高维度以后,会有着无法精准检索的问题,因此许多高维度的相似检索问题都是使用近似最近邻检索方案来完成,而不是使用k-d树。这在后面会有介绍。 2020-04-27四叉树最终分裂的时候不是4个节点,可能是因为数据分布造成的.假设有00 01 和10三类节点,如果00和01的数据量大,那分裂的时候可能就只有00和01.10被分到了01节点上
2020-04-27四叉树最终分裂的时候不是4个节点,可能是因为数据分布造成的.假设有00 01 和10三类节点,如果00和01的数据量大,那分裂的时候可能就只有00和01.10被分到了01节点上作者回复: 不会的哦。如果有10这个数据的话,那么它会是和01平行的独立一个分支,并不会合并到01中。
其实你在前面已经说出了正确答案了,就是“数据分布造成的,假设有00,01和10三类节点”。
你可以看这么一个例子,根节点阈值是4,目前只存有3个数据,分别属于00,01和10三个区域。如果再加一个00区域的数据,引发了根节点分裂,那么由于数据分布只在00,01和10三个区域上,因此只需要分裂出这三个叶子节点就好,并不需要分裂出11这个没有存任何数据的叶子节点。 1



