17 | 存储系统:从检索技术角度剖析LevelDB的架构设计思想





讲述:陈东
时长20:25大小18.71M
如何利用读写分离设计将内存数据高效存储到磁盘?
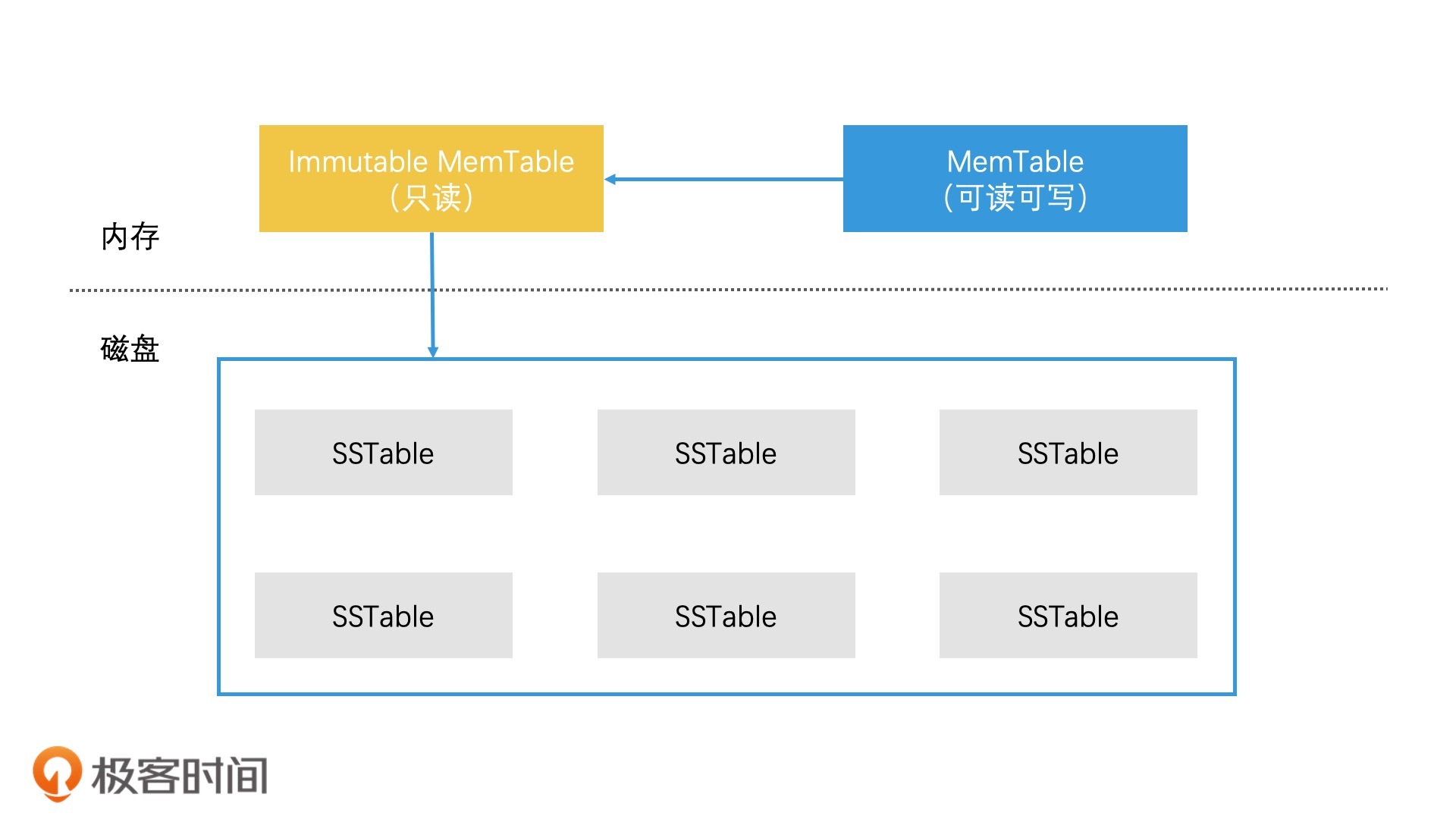
SSTable 的分层管理设计
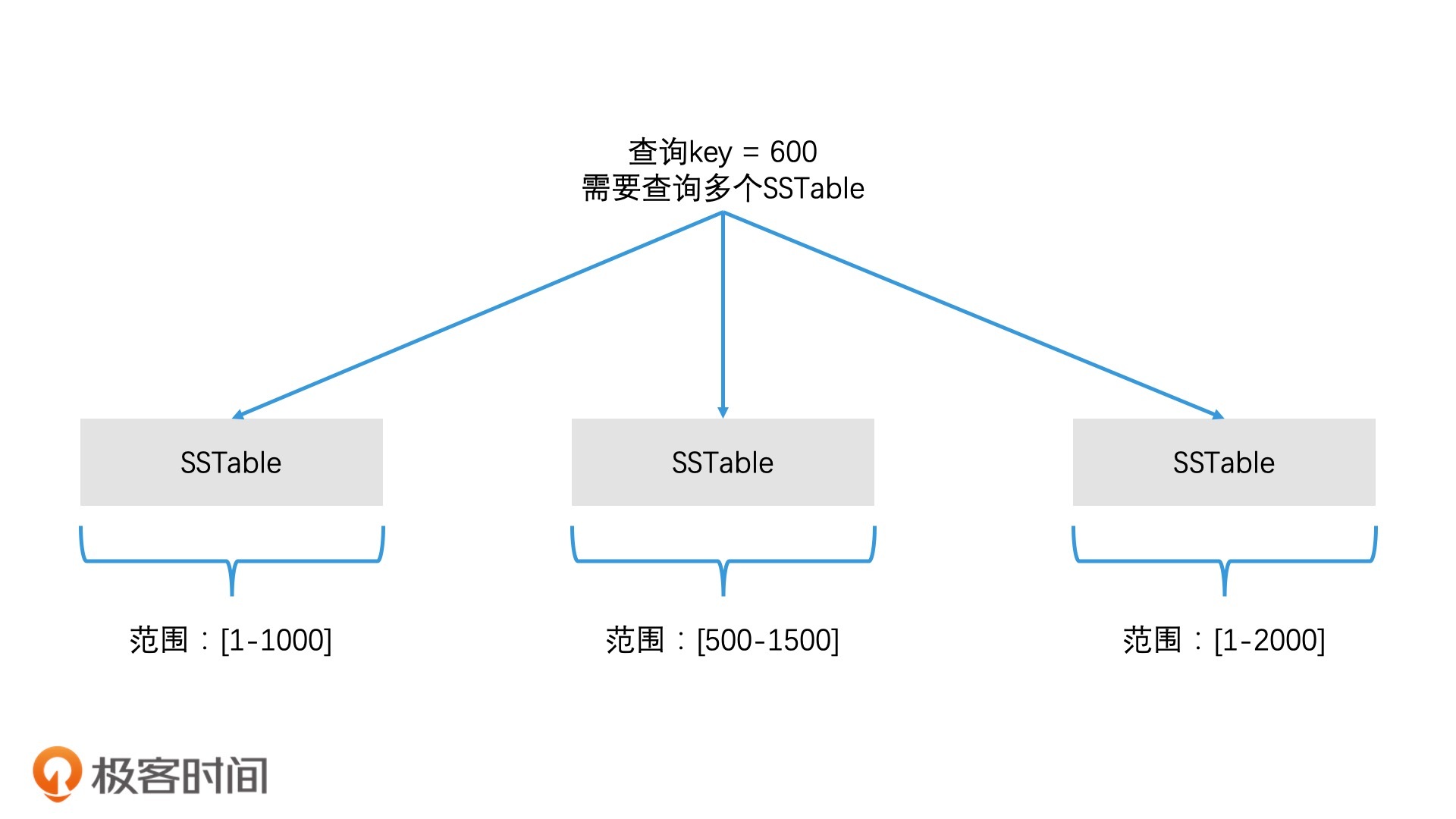
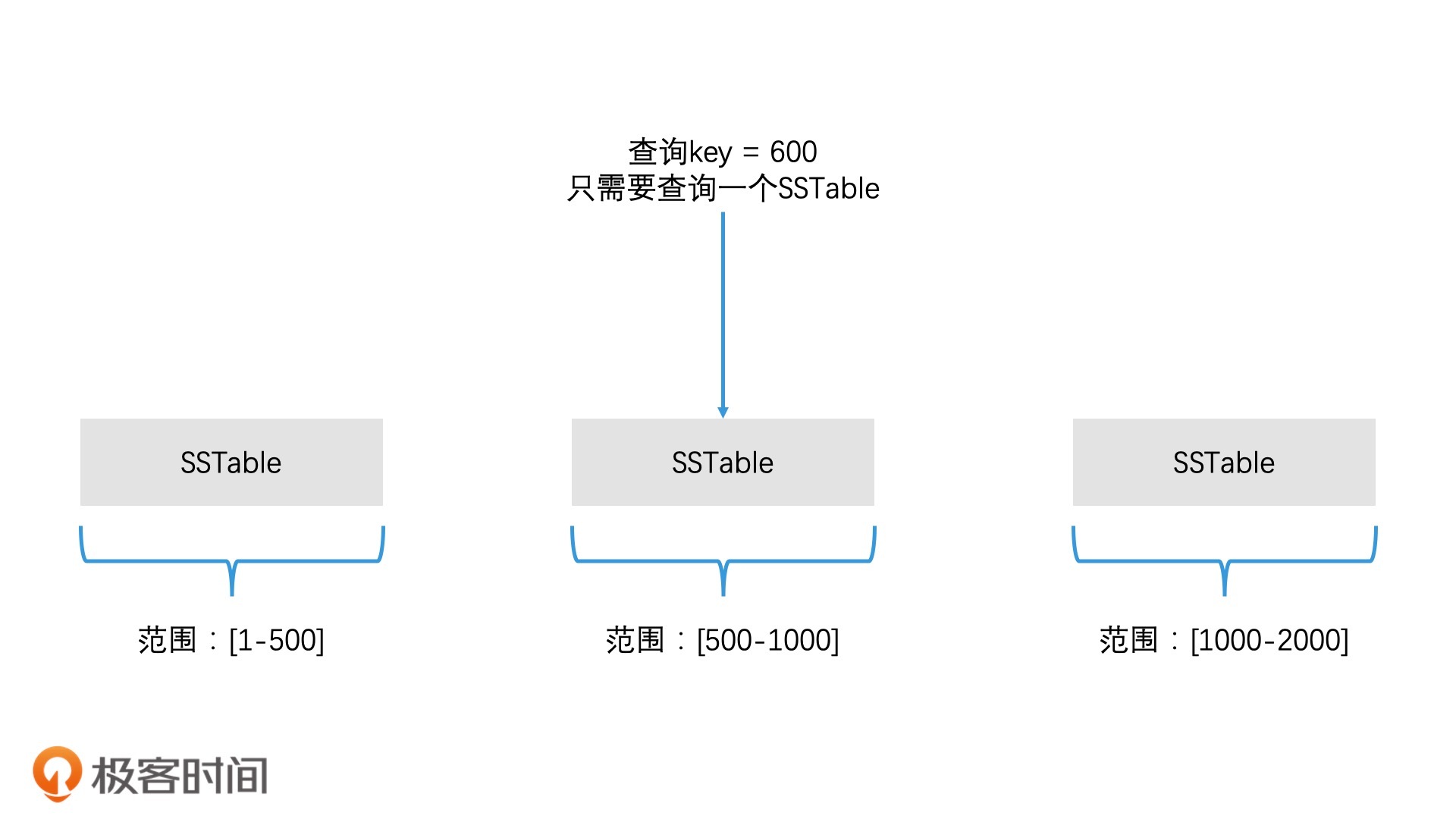
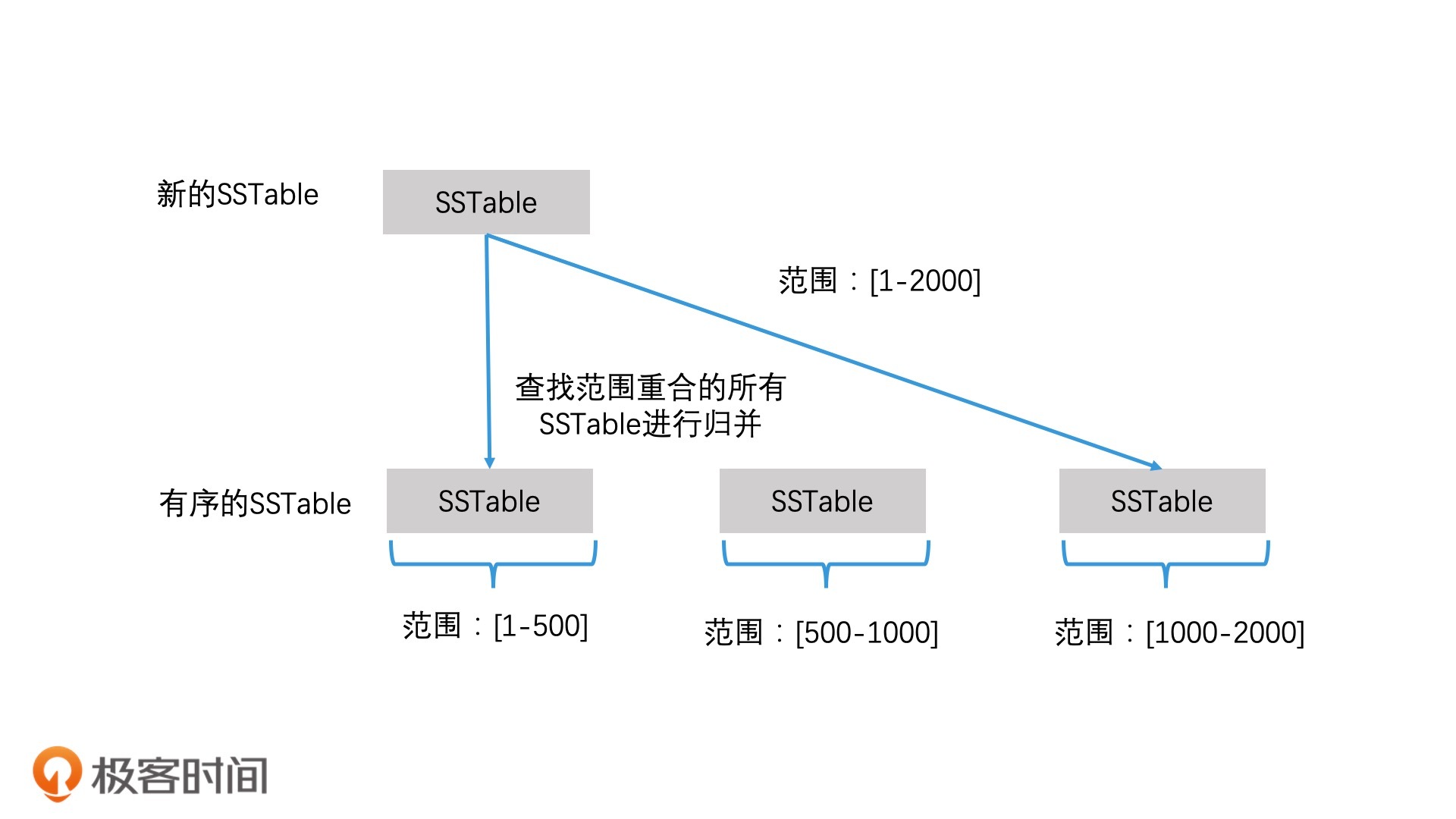
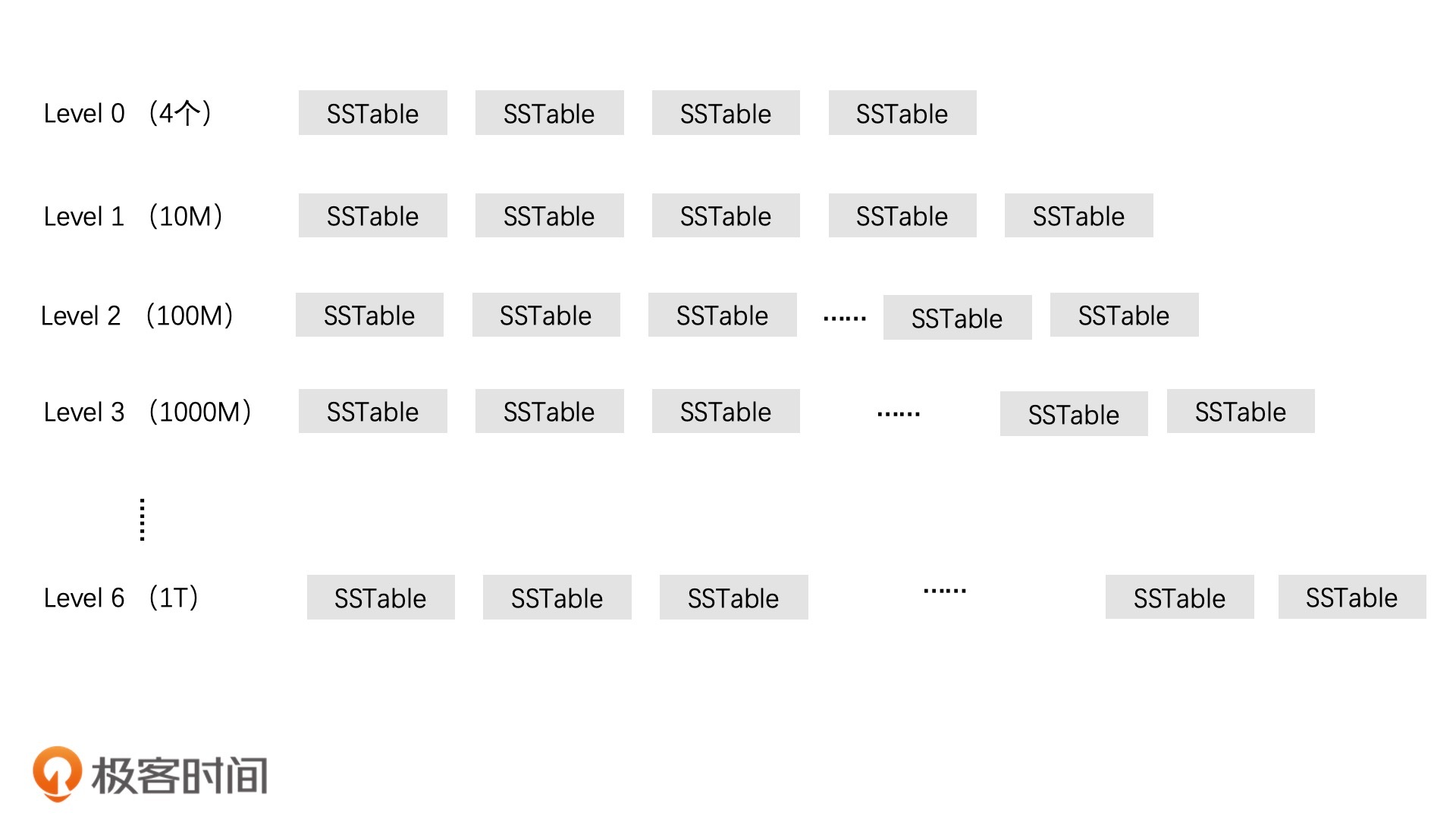
如何查找对应的 SSTable 文件
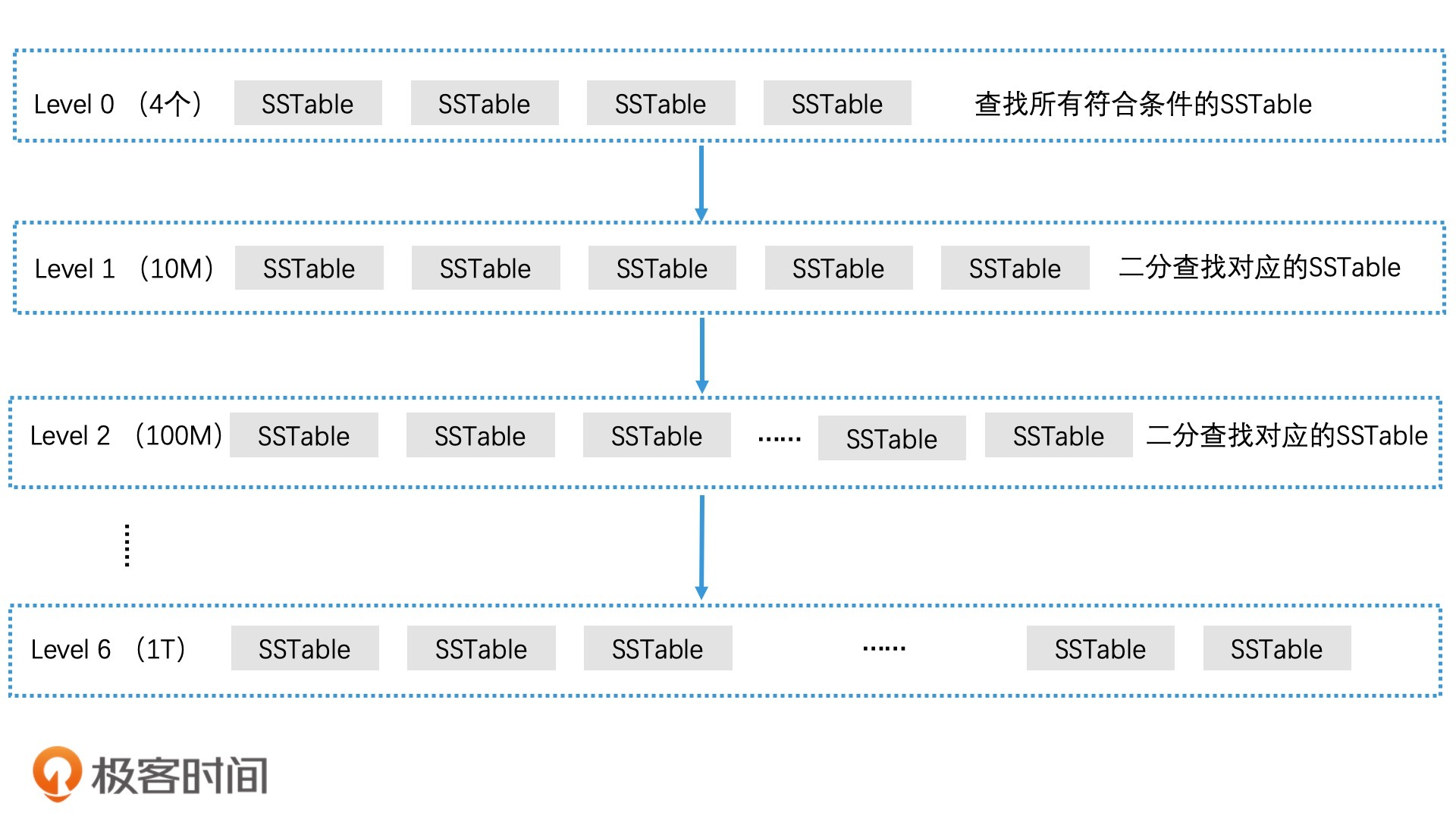
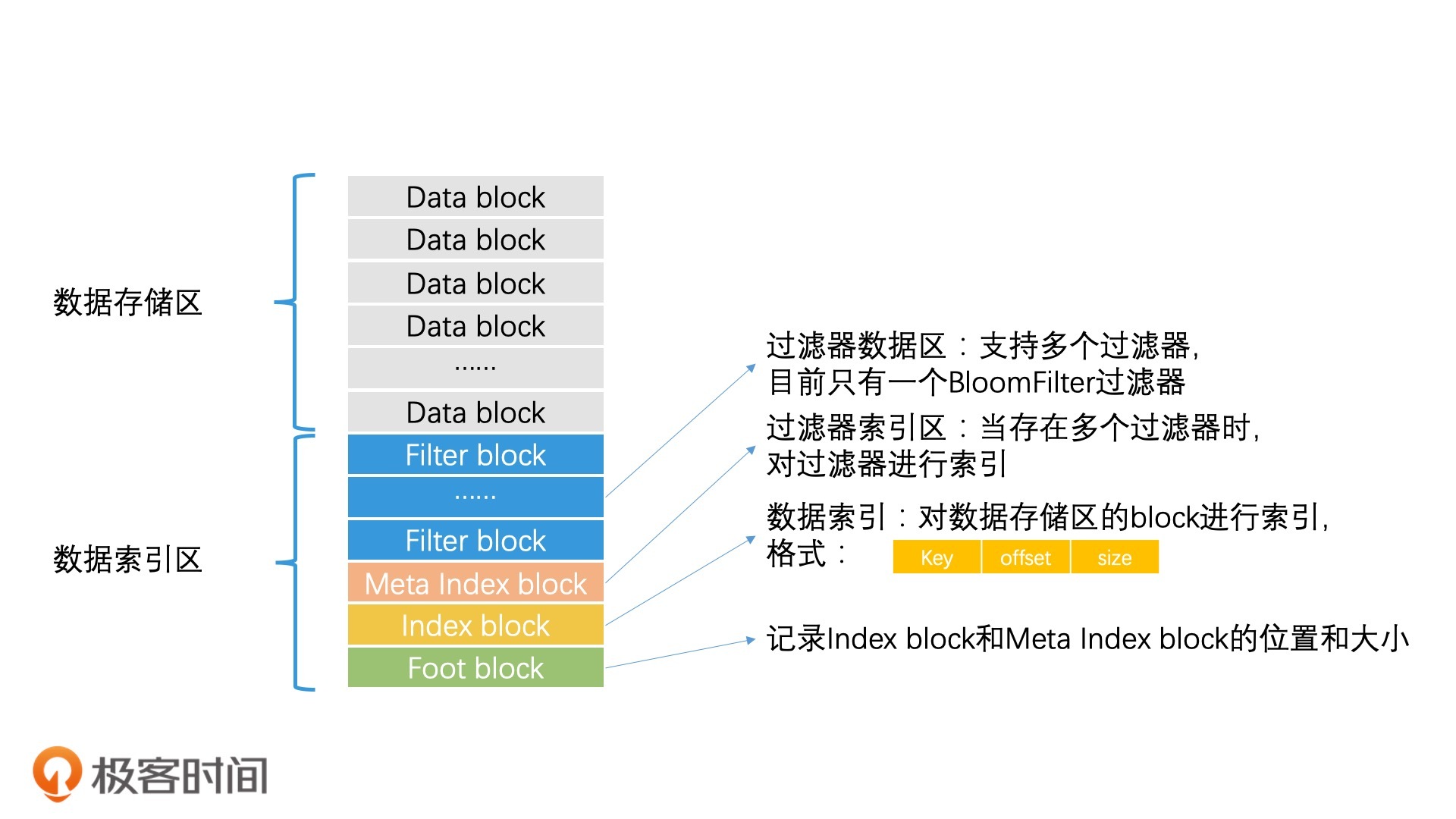
SSTable 文件中的检索加速
利用缓存加速检索 SSTable 文件的过程
重点回顾
课堂讨论

精选留言(13)
 2020-05-08当 MemTable 的存储数据达到上限时,我们直接将它切换为只读的 Immutable MemTable,然后重新生成一个新的 MemTable
2020-05-08当 MemTable 的存储数据达到上限时,我们直接将它切换为只读的 Immutable MemTable,然后重新生成一个新的 MemTable
------------------
这样的一个机制,内存中会出现多个Immutable MemTable 吗? 上一个Immutable MemTable 没有及时写入到磁盘展开作者回复: 这是一个好问题!实际上,这也是levelDB的一个瓶颈。当immutable memtable还没有完全写入磁盘时,memtable如果写满了,就会被阻塞住。
因此,Facebook基于Google的levelDB,开源了一个rocksDB,rocksDB允许创建多个memtable,这样就解决了由于写入磁盘速度太慢导致memtable阻塞的问题。 3 2020-05-08之前看过基于 lsm 的存储系统的代码,能很好理解这篇文章。不过,还是不太理解基于 B+ 树与基于 lsm 的存储系统,两者的优缺点和使用场景有何不同,老师有时间可以解答一下。
2020-05-08之前看过基于 lsm 的存储系统的代码,能很好理解这篇文章。不过,还是不太理解基于 B+ 树与基于 lsm 的存储系统,两者的优缺点和使用场景有何不同,老师有时间可以解答一下。作者回复: lsm树和b+树会有许多不同的特点。但是如果从使用场景来看,最大的区别就是看读和写的需求。
在随机读很多,但是写入很少的场合,适合使用b+树。因为b+树能快速二分找到任何数据,并且磁盘io很少;但如果是使用lsm树,对于大量的随机读,它无法在内存中命中,因此会去读磁盘,并且是一层一层地多次读磁盘,会带来很严重的读放大效应。
但如果是大量的写操作的场景的话,lsm树进行了大量的批量写操作优化,因此效率会比b+树高许多。b+树每次写入都要去修改叶子节点,这会带来大量的磁盘io,使得效率急剧下降。这也是为什么日志系统,监控系统这类大量生成写入数据的应用会采用lsm树的原因。 2 2- 2020-05-09在评论下回复老师看不到啊,那就在评论问一下
第一问还有点疑问:level0层的每个sstable可能会有范围重叠,需要把重叠的部分提取到合并列表,这个这个合并列表是什么?还有就是提取之后呢,还是要遍及level0层的每个sstable与level1层的sstable进行归并吗?
还有个问题就是:当某层的sstable向下层转移的时候,碰巧下层的空间也满了,这时候的处理方案是向下层递归吗?一直往下找,然后在向上处理展开作者回复: 1.合并列表其实就是记录需要合并的sstable的列表。实际上,每次合并时,系统都会生成两个合并列表。
以你提问的level 0层的情况为例,先选定一个要合并的sstable,然后将level 0层中和它范围重叠的sstable都加入到这个列表中;这就是合并列表1。
然后,对于合并列表1中所有的sstable,我们能找到整体的范围begin和end。那么我们在下一层中,将和begin和end范围重叠的所有sstable文件加入合并列表2。
那么,对于合并列表1和合并列表2中的所有的sstable,我们将它们一起做一次多路归并就可以了。
2.如果下层空间满了,没关系,先合并完,这时候,下层空间就超容量了。那么,我们再针对这一层,按之前介绍的规则,选择一个sstable再和下层合并即可。
PS:再补充一下知识点:合并的触发条件。
系统会统计每个level的文件容量是否超过限制。超过上限比例最大的,将会被触发合并操作。 1 1 - 2020-05-09LevelDB 分层的逻辑没有理解
当 Level0 层 有四个 SSTable 的时候,这时候把这个四个进行归并,然后放到 Level1 层,这时候 Level0 层清空,这个有个问题是 当进行归并后 后生成几个 SSTable ,这里是有什么规则吗?
接下来,然后 Level0 层在满了之后,是Level0 层的每个 SSTable 分别与 Level1 所有的 SSTable 进行多路归并吗?
再然后 Level1 层满了之后,是按照顺序取 Level1 层的一个 SSTable 与 Level2所有的 SSTable 进行多路归并吗?
这样会有大量的 磁盘 IO,老师说利用判断重合度进行解决的? 这个重合度是怎么计算计算判断的呢?
==============================
老师的文中的这句话没有看明白:
在多路归并生成第 n 层的 SSTable 文件时,LevelDB 会判断生成的 SSTable 和第 n+1 层的重合覆盖度,如果重合覆盖度超过了 10 个文件,就结束这个 SSTable 的生成,继续生成下一个 SSTable 文件展开作者回复: 你的问题我重新整理一下,尤其是level 0层怎么处理,这其实是一个很好的问题:
问题1:level 0层到level 1层合并的时候,level 0层是有多少个sstable参与合并?
回答:按道理来说,我们应该是根据轮流选择的策略,选择一个level 0层的sstable进行和下层的合并,但是由于level 0层中的sstable可能范围是重叠的,因此我们需要检查每一个sstable,将有重叠部分的都加入到合并列表中。
问题2:level n层中的一个sstable要和level n+1层中的所有sstable进行合并么?
回答:不需要。如果level n层的sstable的最大最小值是begin和end,我们只需要在level n+1层中,找到可能包含begin到end之间的sstable即可。这个数量不会超过10个。因此不会带来太大的io。
问题3:为什么level n层的sstable和level n+1层的合并,个数不会超过10个?
回答:在level n层的sstable生成的时候,我们会开始判断这个sstable和level n+1层的哪些sstable有重叠。如果发现重叠个数达到十个,就要结束这个sstable文件的生成。
举个例子,如果level n+1层的11个sstable的第一个元素分别是[100,200,300,400,……,1000,1100],即开头都是100的整数倍。那么,如果level n层的sstable文件生成时,准备写入的数据就是[100,200,300,400,……,1000,1100],那么在要写入1100的时候,系统会发现,如果写入1100,那么这个sstable文件就会和下一层的11个sstable文件有重叠了,会违反规则,因此,这时候会结束这个sstable,也就是说,这个sstable文件中只有100到1000十个数。然后1100会被写入到一个新的sstable中。 1 1  2020-05-09老师、我想请教下、levelDB是怎么处理`脏缓存`(eg. 有用户突然访问了别人很久不访问的数据(假设还比较大)、导致本来应该在缓存中的数据被驱逐, Data Block的优化效果就会打折扣)的 ?
2020-05-09老师、我想请教下、levelDB是怎么处理`脏缓存`(eg. 有用户突然访问了别人很久不访问的数据(假设还比较大)、导致本来应该在缓存中的数据被驱逐, Data Block的优化效果就会打折扣)的 ?
------
我是想到了Mysql 处理Buffer Poll的机制(分为Old 和 Young区)、类似的思想在jvm的gc管理中也有用到展开作者回复: 首先,levelDB并没有“脏缓存”的问题。因为lsm树和b+树不一样。
b+树的缓存对应着磁盘上的叶子节点,叶子节点是可以被修改的,因此会出现缓存在内存中的数据被修改,但是磁盘对应的叶子节点还未修改的“脏缓存”问题。
而levelDB中,data block存的是sstable的数据,而每个sstable文件是只读的,不可修改的,因此不会出现“脏缓存”问题。
另一点,如果缓存数据被大片读入的新数据驱除,是否会有优化方案?这其实就依赖于lru的具体实现了(比如分为old和young区),levelDB本身并没有做特殊处理。 1 2020-05-08老师,不好意思哈,再追问一下😬那为啥用change buffer + WAL优化后的MySQL的写性能还是不如LSM类的存储系统啊?原因是啥啊展开
2020-05-08老师,不好意思哈,再追问一下😬那为啥用change buffer + WAL优化后的MySQL的写性能还是不如LSM类的存储系统啊?原因是啥啊展开作者回复: 因为对于b+树,当内存中的change buffer写满的时候,会去更新多个叶子节点,这会带来多次磁盘IO;但lsm当内存中的memtable写满时,只会去写一次sstable文件。因此它们的主要差异,还是在怎么将数据写入磁盘上。
当然所有的系统设计都是有利有弊,要做权衡。b+树写入磁盘后,随机读性能比较好;而lsm树写磁盘一时爽,但要随机读的时候就不爽了,它可能得在多层去寻找sstable文件,因此随机读性能比b+树差。- 2020-05-08老师晚上好,请教个问题哈。
MySQL在写数据的时候,是先写到change buffer内存中的,不会立刻写磁盘的,达到一定量再将change buffer落盘。这个和Memtable的设计理念类似,按理说,速度也不会太慢吧?展开作者回复: 你说得对,在MySQL的b+树的具体实现中,其实借鉴了许多lsm树的设计思想来提升性能,比如使用wal技术+change buffer,然后批量写叶子节点,而不是每次都随机写。这样就能减少磁盘IO。的确比原始的b+树快。
不过在大批量写的应用场景中,这样优化后的b+树性能还是没有lsm树更好。因此日志系统这类场景还是使用lsm树更合适。 1 - 2020-05-08课后思考:
1: 因为 LevelDB 天然的具有缓存的特性,最经常使用的最新的数据离用户最近,所有在上层找到数据就不会在向下找了
2: 如果规定生成文件的个数,那么有可能当前层和下一层的存储大小相近了,起不到分层的作用了展开作者回复: 1.没错,最新的数据在上层,所以上层能找到,就不需要去下层读旧数据了。
2.是的,由于在生成sstable文件时,有这么一个限制:新生成的sstable文件不能和下层的sstable覆盖度超过十个,因此可能会生成多个小的sstable文件。那如果只看文件数的话,多个小的sstable文件可能容量和下一层差不多,这样就没有了分层的作用了。  2020-05-08有两个问题,请教下老师。
2020-05-08有两个问题,请教下老师。
1。在多路归并生成第 n 层的 SSTable 文件时,如何控制当前层最大容量呢?如果超过当前层的容量是停止计算还是把多余的量挪到下一层?
2。数据索引区里meta index block,当存在多个过滤器时,对过滤器进行索引。这是涉及到filter block过滤么?展开作者回复: 1.不用停止计算,而是算完后,判断容量是否达到上限,如果超过,就根据文中介绍的选择文件的方式,将多余的文件和下一层进行合并。
2.如果存在多个filter block,而且每个filter都很大的话(比如说bloomfilter就有许多数据),将所有的filter都读入内存会造成多次磁盘IO,因此需要有metaphor index block,帮助我们只读取我们需要的filter即可。- 2020-05-08讨论问题1:在某一层找到了key,不需要再去下一层查找的原因是,这一层是最新的数据。即使下一层有的话,是旧数据。这引申出另外一个问题,数据删除的时候是怎么处理的呢?是另外一个删除列表来保存删除的key吗?
问题2:如老师提示的这样,SSTable 的生成过程会受到约束,SSTable在归并的过程中,可能由于数据倾斜,导致某个分区里的数据量比较大,所以没有办法保证每个SSTable的大小。展开作者回复: 问题1:你进一步去思考删除问题。这一点很好。数据删除时,是会将记录打上一个删除标记,然后写入sstable中。
sstable和下一层合并时,对于带着删除标记的记录,levelDB会判断下层到最后一层是否还有这个key记录,有两种结果:
1.如果还有,那么这个删除标记就不能去掉,要一直保留到最后一层遇到相同key的时候才能删除;
2.如果没有,那么就可以删除掉这个带删除标记的记录。
问题2:因为在进行合并时,新生成的sstable会受到一个约束:如果和下一层的sstable重叠数超过了十个,就要停止生成这个sstable,要再继续生成一个新的sstable。这个机制会导致我们不好控制文件的个数。不如限定容量更合适。 - 2020-05-08老师辛苦了,经常都是凌晨更新,终于等到这篇文章了😁
作者回复: 哈哈,凌晨更新是系统默认上线操作,是由极客时间的工作人员们负责的,他们辛苦了。
 2020-05-08老师,如果是memtable有删除key的情况下,skiplist是不是设置墓碑标志,刷level 0的时候 sstable也还是有这个删除标记,只有在最下层的sstable合并时候再真的物理删除key啊,感觉不这么做,可能get时候会读出来已经被删除的key展开
2020-05-08老师,如果是memtable有删除key的情况下,skiplist是不是设置墓碑标志,刷level 0的时候 sstable也还是有这个删除标记,只有在最下层的sstable合并时候再真的物理删除key啊,感觉不这么做,可能get时候会读出来已经被删除的key展开作者回复: 你思考得很仔细,的确是的。sstable中,每一条记录都有一个标志位,表示是否是删除。这样就能避免误查询。
对于有删除标志的记录,其实查询流程是一致的,就是查到数据就返回,不再往下查。然后看这个数据的状态位是有效还是删除,决定是否使用。 1 2020-05-08问题1: 因为只是get(key), 所以上层的sstabe的数据是最新的,所以没必要再往下面查,但如果有hbase这样的scan(startkey,endkey) 那还是得全局的多路归并(当然可以通过文件元数据迅速排除掉一些hfile)
2020-05-08问题1: 因为只是get(key), 所以上层的sstabe的数据是最新的,所以没必要再往下面查,但如果有hbase这样的scan(startkey,endkey) 那还是得全局的多路归并(当然可以通过文件元数据迅速排除掉一些hfile)
问题2:SSTable 的生成过程会受到约束,无法保证每一个 SSTable 文件的大小。哈哈哈,我在抄答案,我其实有疑问,就算限定文件数量,那么在层次合并的时候,假设我是先合成一个整个sstable再切,面临的对这一整个sstable怎么切成文件的问题,那就顺序的2m一个算会不会文件数量超标,决定是否要滚动下一层,不过我这样想法过于理想显然假设那块就不成立,应该是多路归并式的动态生成,否则对内存压力太大,但是如果按整个层的文件大小分,就不用考虑文件量的问题,只要key连续性大点,文件大小不超过2m就生成就好了。展开作者回复: 1.你提到的这个问题非常好,lsm的范围查询比较弱,需要遍历。一种优化思路是先在level 1层中找到range,然后基于start和end的位置,去下一层再找start和end的位置。这样能提高范围查询的性能。
2.我说一下我的理解,由于有“生成的每个sstable和下一层的sstable重合度不能超过十个”这个约束,所以sstable生成过程中可能随时被截断,因此不好控制sstable的数量。不如控制容量简单。






