04 | 元数据中心的关键目标和技术实现方案





讲述:郭忆
时长20:02大小18.35M
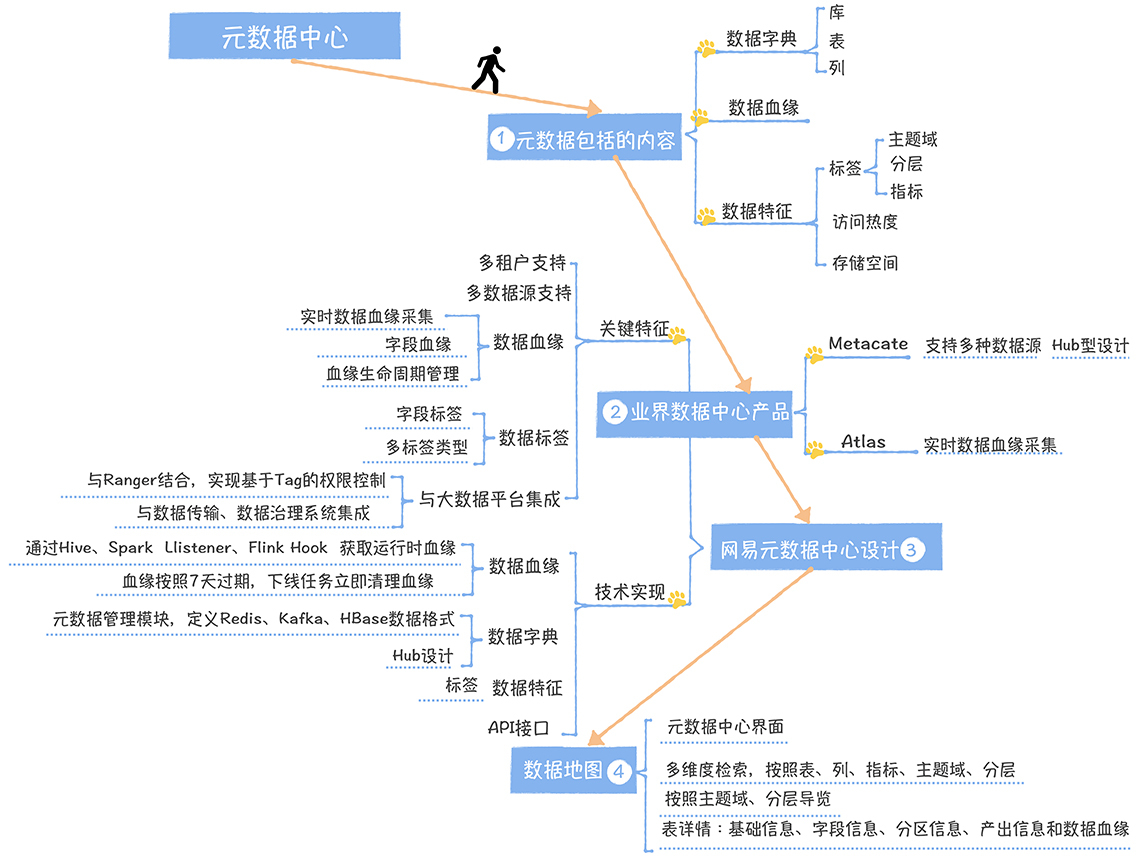
元数据包括哪些?



业界元数据中心产品
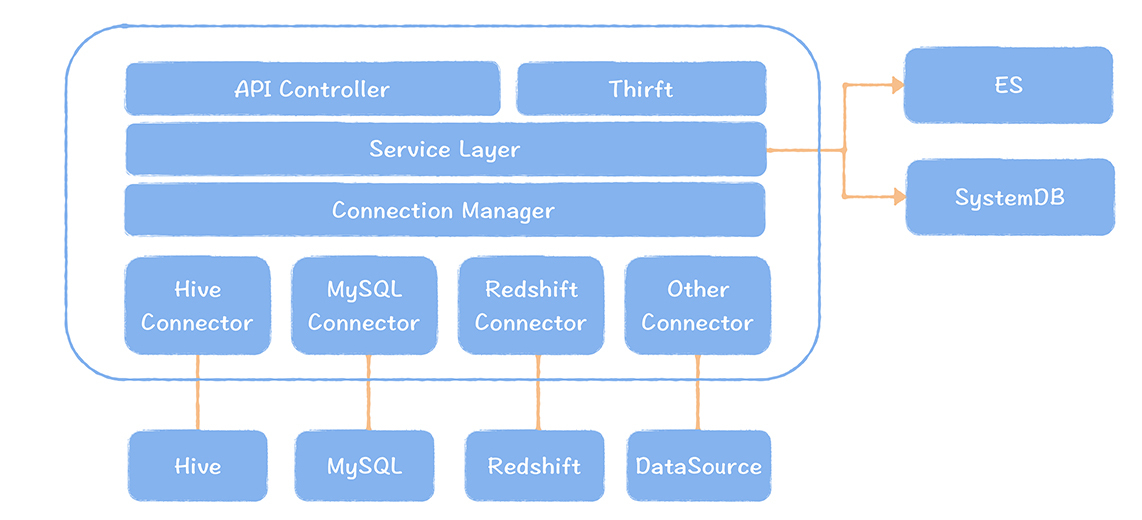
Metacat 多数据源集成型架构设计
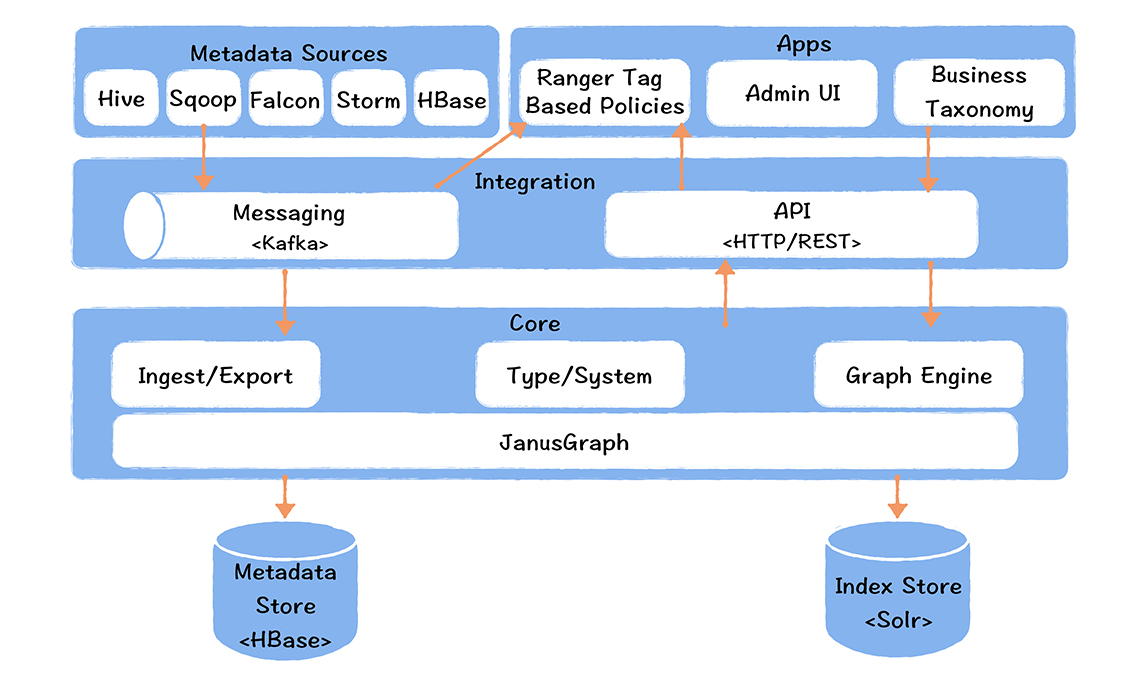
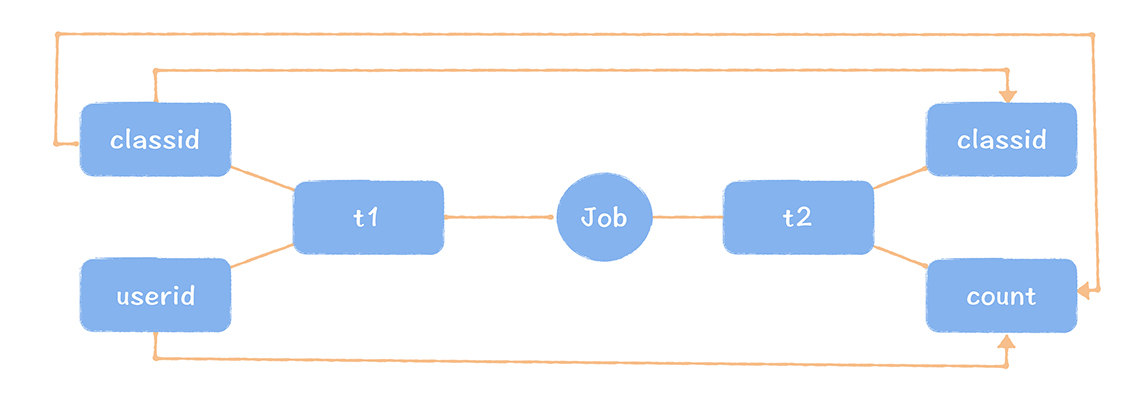
Apache Atlas 实时数据血缘采集
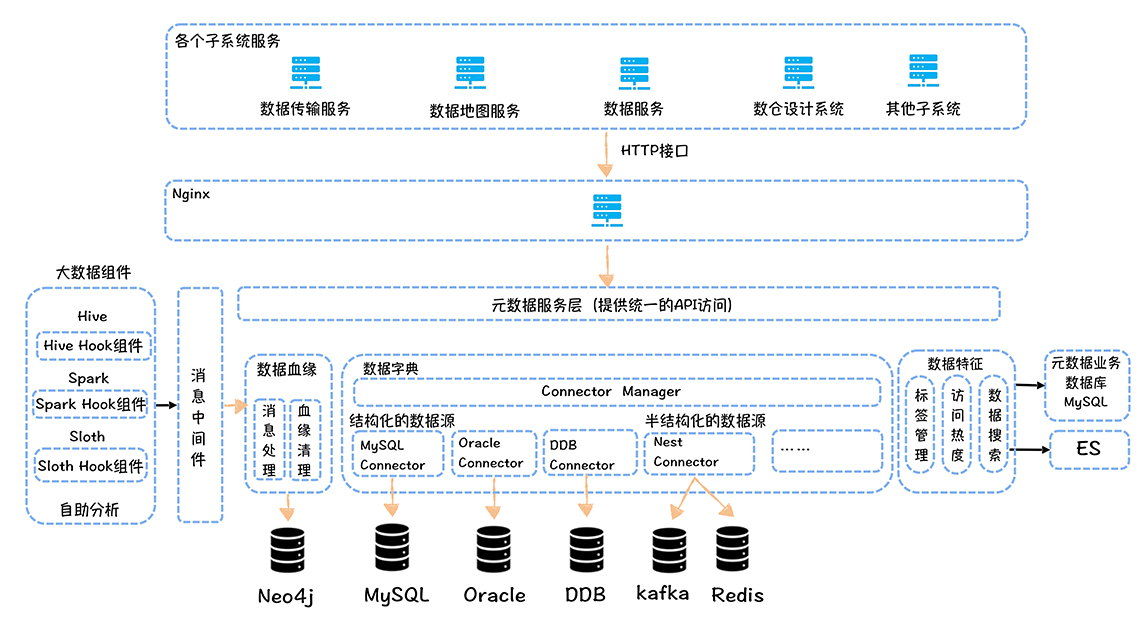
网易元数据中心设计
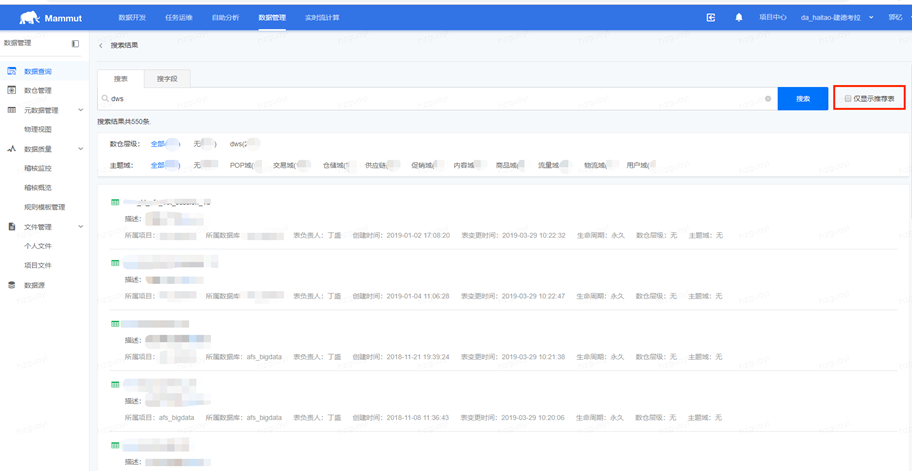
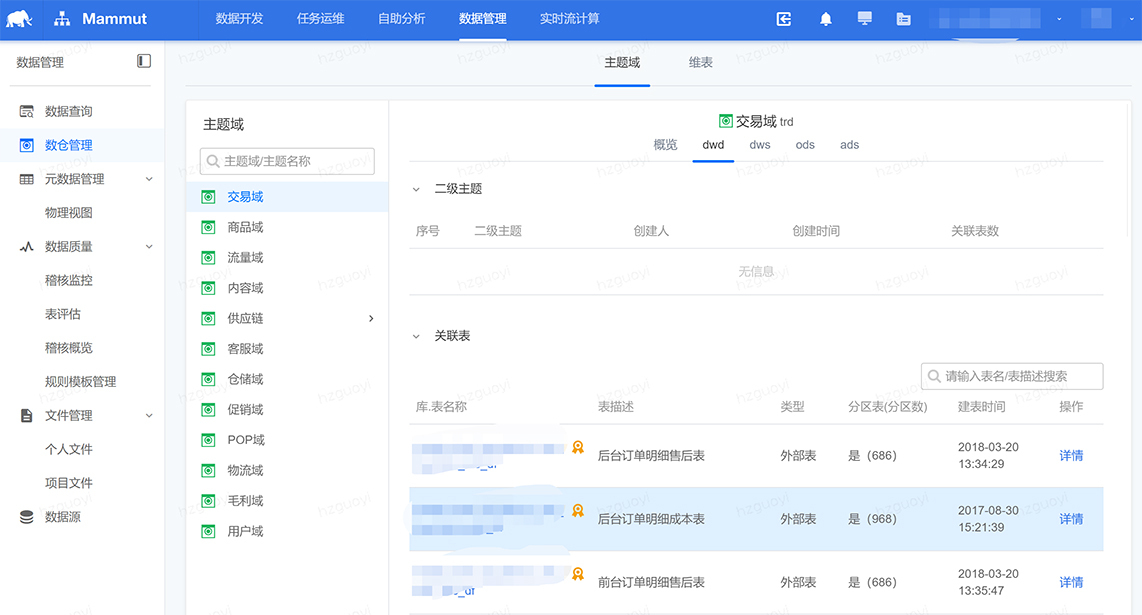
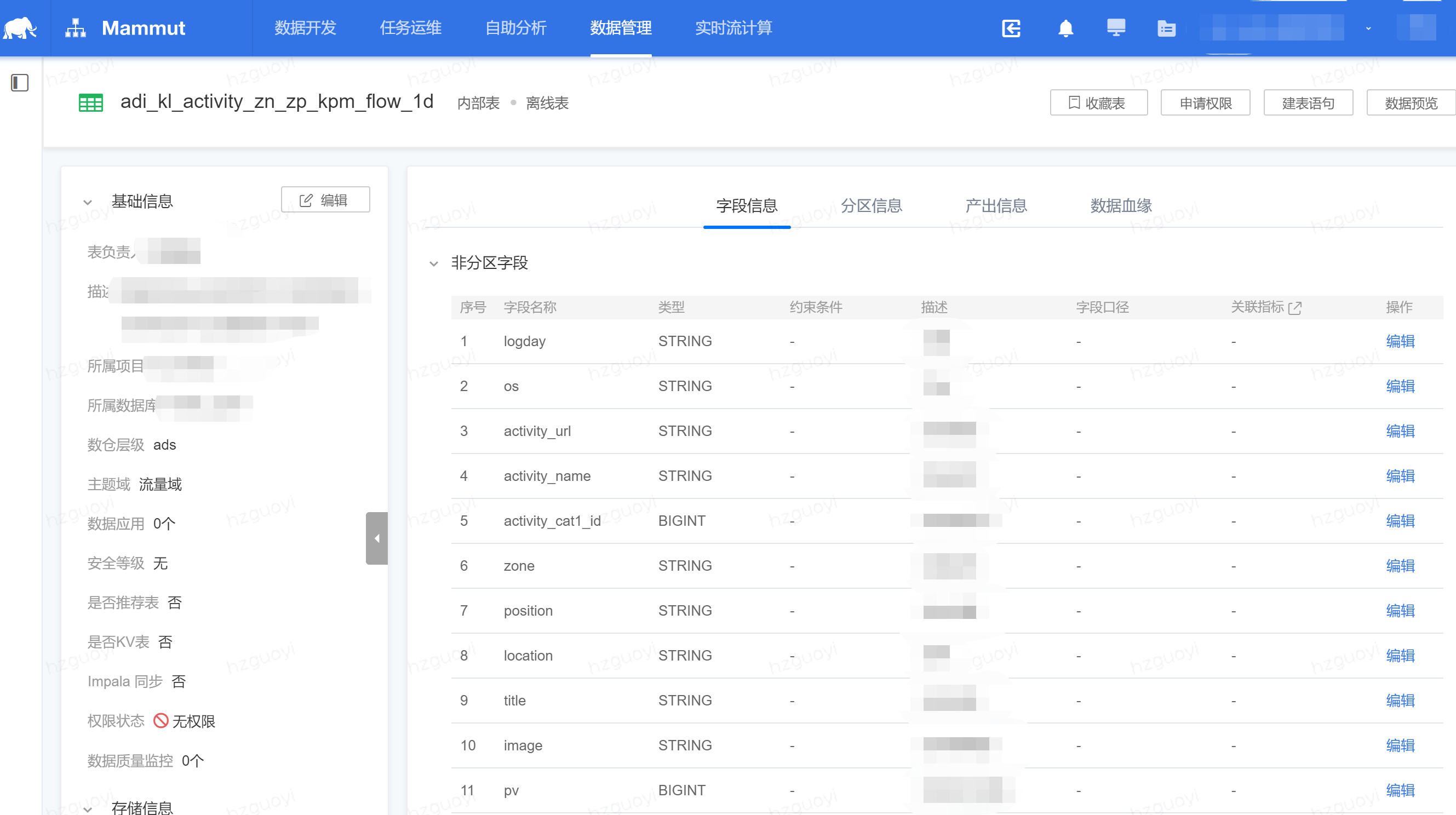
数据地图:元数据中心的界面
课程总结
课程思考

精选留言(17)
 2020-04-10业务指标
2020-04-10业务指标
数据来源
加工sql
把数据生命周期当作产品服务,提供给公司人员使用
和公司把具体产品提供给外面实验是一个思路
使用这些表的员工就是公司核心用户,平台上孵化更多产品服务客户
一层一层的内聚展开作者回复: 对的,其实思路是一致的,数据产品可以看成是一个C端产品,它的客户不是开发,而是运营,所以在产品设计上,要尽可能的降低门槛,注重引导。
1 3 2020-04-13郭老师好,听了您的课,感觉个个都直击痛点啊!本节课里数据字典和数据血缘感觉都有开源的可以参考或者直接使用,那么数据特征的管理是怎么处理的呢?手动维护吗?比如标签、关联指标之类描述性的。 1
2020-04-13郭老师好,听了您的课,感觉个个都直击痛点啊!本节课里数据字典和数据血缘感觉都有开源的可以参考或者直接使用,那么数据特征的管理是怎么处理的呢?手动维护吗?比如标签、关联指标之类描述性的。 1 2020-04-11郭老师我听了您数据中台实战课,我们单位有需求且量比较大,能军民融合一下么?特别需要您的指点
2020-04-11郭老师我听了您数据中台实战课,我们单位有需求且量比较大,能军民融合一下么?特别需要您的指点作者回复: 好啊,数据中台与业务结合更紧密,具备行业属性,因为网易业务比较多元化,所以我们做过电商、在线音乐、新闻、在线教育等行业,对外也做过零售、物流、农业、制造业等行业,希望能够有更多的行业实践~
1 1 2020-04-11感觉一般的小团队,搞不定啊展开
2020-04-11感觉一般的小团队,搞不定啊展开作者回复: 你好,其实不然, 元数据中心业界有开源的产品,其实最差也可以用开源的来搭一套,只是没有那么易用罢了。元数据中心本身还是一个偏实现层的产品,基于元数据中心之上,我会为你介绍五个元数据的应用场景,这部分开源的产品会比较少涉及,但是如果你能深入理解这些产品背后设计思想,应用场景,解决的问题,即使你要选取外面的商业化产品,你也可以有自己的一个判断。
感谢你的阅读,期待与你在留言区再次相遇~ 1 2020-04-10老师,如果表数据是通过java 程序的etl,又如何解析血缘关系?
2020-04-10老师,如果表数据是通过java 程序的etl,又如何解析血缘关系?作者回复: 目前,我们数据中台中所有的数据都是以表的形式存在的,血缘都是以表的血缘。并没有做文件、数据集的血缘。
感谢你的阅读,期待与你在留言区再次相遇。 1 2020-04-10表字段信息是实时采集的,像表负责人这些信息怎么关联上的?
2020-04-10表字段信息是实时采集的,像表负责人这些信息怎么关联上的?作者回复: metastore是有owner属性的,它可以作为表的负责人角色。
另外,对于非hive表,负责人可以作为一种类型的标签,和表建立关联。
期待与你下一次在留言区互动~ 1 1 2020-04-10郭老师,您好,元数据中心建设,是否可以理解主要以元数据管理工具进行落地,只是需要配置,就可以实现呢?还是需要有相关的代码开发的工作,才能落地元数据中心的建设?
2020-04-10郭老师,您好,元数据中心建设,是否可以理解主要以元数据管理工具进行落地,只是需要配置,就可以实现呢?还是需要有相关的代码开发的工作,才能落地元数据中心的建设?作者回复: 元数据中心的建设,对于数据字典中直连数据源获取元数据的数据源,以及数据血缘部分,工具落地就可以统一收集到元数据。
但是对于数据特征,尤其是指标、维度标签,这部分是需要数据开发实施介入的,需要进行规范化梳理,一个表,哪些字段是指标,哪些字段是维度,这些不是工具落地就可以自动获取的。
感谢你的阅读,期待与你在留言区再次互动~ 1- 2020-04-13郭老师好,看了元数据我又两个问题请教一下:
1.文中元数据中心依赖了Atlas,ranger,neo4j,es,kafka等,是否依赖的太多,太重
2.ranger通过tag实现权限管理,是否数据权限管理都使用ranger,不会另外单独一个数据权限模块么?
还有一个额外的非本篇的问题,在网易大数据环境中,是否使用了kerberos?展开  2020-04-13网易的元数据中心是完全自研的吗?中小型企业自建元数据中心是推荐在MetaCat或者Atlas上改还是自研呢?
2020-04-13网易的元数据中心是完全自研的吗?中小型企业自建元数据中心是推荐在MetaCat或者Atlas上改还是自研呢? 2020-04-12郭老师,你好,就元数据的存储模型,是否能分享下经验?之前看了普元专门做元数据管理的公司,说底层都是兼容cwm模型展开
2020-04-12郭老师,你好,就元数据的存储模型,是否能分享下经验?之前看了普元专门做元数据管理的公司,说底层都是兼容cwm模型展开 2020-04-11在传统企业里,高层领导都是业务出身,而像元数据中心这种产品,如何能说服业务领导同意建设,同时数据地图在设计时如何能让纯业务人员感受到其价值?展开
2020-04-11在传统企业里,高层领导都是业务出身,而像元数据中心这种产品,如何能说服业务领导同意建设,同时数据地图在设计时如何能让纯业务人员感受到其价值?展开作者回复: 你好,你说的很对,元数据中心本身是一个偏实现层的产品,领导其实根本就不关心是否存在这样的一个数据中台的底层。
但是数据地图,是元数据中心的界面,通过数据地图,领导可以看到数据中台的统一元数据视图,另外,结合数据地图的使用频率、使用范围,可以凸显数据地图的价值。
数据地图在设计时,一方面他的使用对象是数据开发,另外一方面,他的使用对象又是业务人员。让业务人员感受到数据地图的价值,主要是能够让业务人员搜索指标、数据报表,帮助他们快速找到自己想要的数据。无论是数据表,还是数据报表,还是指标,都能够通过数据地图进行搜索和导览。- 2020-04-11对于静态数据结构、动态血缘分析这种可以通过工具采集,但是数据库中没有中文,是否还是需要人工梳理录入登记?这个工作量也不小了。展开
作者回复: 你好,你是指的数据字典中字段级别的业务元数据信息? 有的数据库中,并没有相关的commet描述,或者comment 不适合查看,此时可以通过标签的形式,作为一种特定类型的标签,关联到表的字段中。
本身这个梳理的工作是跑不掉的,但是也可以采取用到的时候再补充,数据源是数据集成阶段登记到数据中台的元数据中心中,此时再梳理补充,并不需要一口气全部补充完整。  2020-04-11郭老师,您觉得不同规模的企业,构建一个数据中台大概需要多少人手和多久时间?
2020-04-11郭老师,您觉得不同规模的企业,构建一个数据中台大概需要多少人手和多久时间?作者回复: 你好,其实这个问题,没有办法给出一个统一的标准答案,因为不同企业的业务复杂度,数据应用的水平、建设水平差异都很大。
我会在专栏第13节介绍网易电商数据中台项目从立项到实施的完成过程,可以给你一定的参考。
但是我要多说一句,既然问到这个问题,很可能就是你在担心数据中台建设,前期需要投入很多的资源。而我的建议是,数据中台的建设可以采取滚雪球的方式,逐步以场景化的方式落地。这样既可以控制前期的资源投入风险,又可以保证数据中台有一些阶段性成果的输出。
感谢你的阅读,期待你在留言区再次与我互动~ 2020-04-10静态解析可以在任务开始之前提供给SQL开发者一些信息,如:上游表有问题、当前资源不足、已存在类似任务等信息,避免错误和资源浪费。
2020-04-10静态解析可以在任务开始之前提供给SQL开发者一些信息,如:上游表有问题、当前资源不足、已存在类似任务等信息,避免错误和资源浪费。
另外,提前统计也可以让数据中台开发者对任务量级有个预估展开作者回复: 其实,主要是解决SQL还没有执行过,没有血缘产生,而此时又需要用到血缘的场景~
感谢你的阅读,期待与你在留言区再次相遇~ 2020-04-10请问下,元数据中心在项目运维中是怎么和调度系统结合的? 比如表的使用热度等信息是基于什么指标进行判断的?展开
2020-04-10请问下,元数据中心在项目运维中是怎么和调度系统结合的? 比如表的使用热度等信息是基于什么指标进行判断的?展开作者回复: 你好,表的使用热度,是根据平台上调度运行的job和adhoc执行的query计算来的。
通过数据血缘,我们可以获取到表和任务、query的关联关系,然后可以计算这部分的引用热度。数据血缘是通过hive/spark插件的方式获取的。
感谢你的交流,期待与你在留言区再次相遇~ 2020-04-10这一期录音频真是辛苦老师了,哈哈。
2020-04-10这一期录音频真是辛苦老师了,哈哈。
老师有一个问题想请教下,元数据的初始真实性您在实战中是如何解决的呢。展开作者回复: 你好,你所指的真实性是指什么?
能有一个具体的例子么?
因为在文章中,我也提到元数据中心,管理了所有数据中台的元数据,所有系统都与元数据中心打通,把元数据的管理入口都收归到元数据中心,可以确保元数据的一致。
期待与你再次在留言区相遇~- 2020-04-10我能想到的一个场景是:静态血缘解析可以对一个正在开发的SQL提供参考信息,看系统中表有哪些SQL处理,避免SQL冗余和冲突。展开
作者回复: 我来举个场景,你来看看。
当我们要提交任务上线,建立任务依赖时,如果我们依赖的表,还没有被调度产生数据,此时就会导致我们根据这张表找不到表的产出任务,系统就无法自动推荐依赖任务。
所以此时就需要静态血缘的介入啦。 对于还未执行,但是保存,SQL语法检查通过的任务,我们可以通过解析SQL获取静态血缘,然后当其他任务读取这张表,要建立到这张表产出任务的依赖时,我们可以根据静态血缘,找到这张表的产出任务。
欢迎你继续在留言区与我互动~ 1












