06 | 数据模型无法复用,归根结底还是设计问题





讲述:郭忆
时长21:59大小20.14M
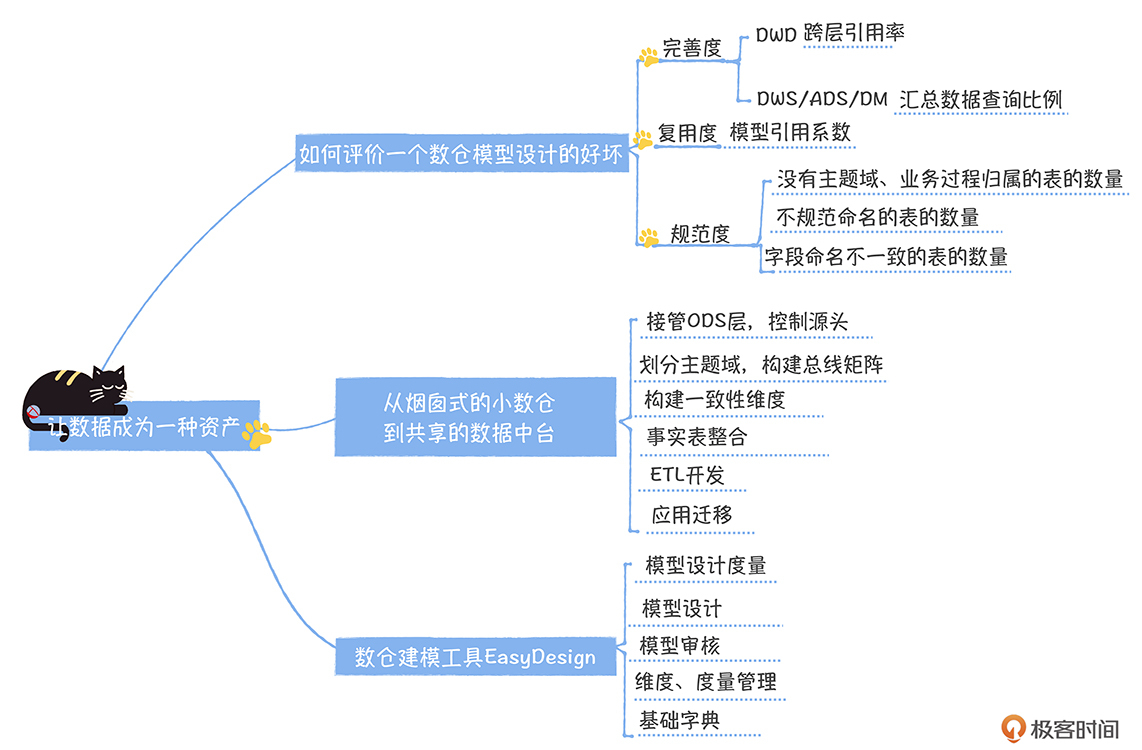
什么才是一个好的数据模型设计?
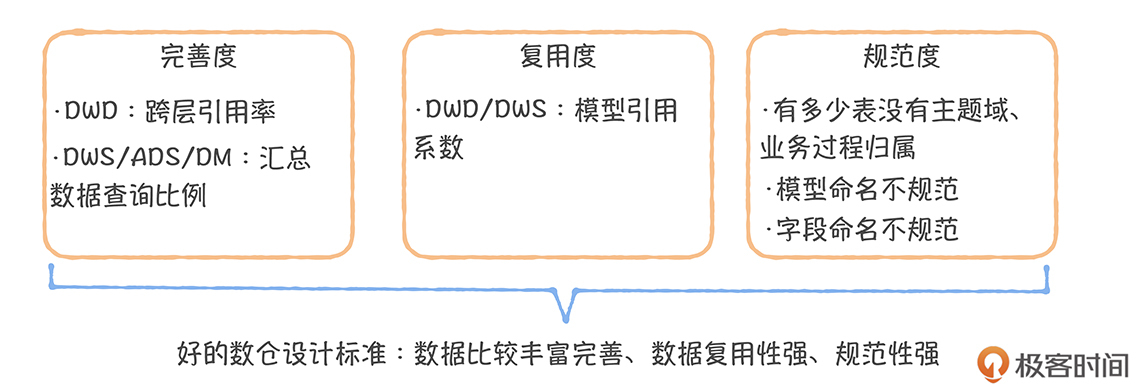
如何衡量完善度
如何衡量复用度
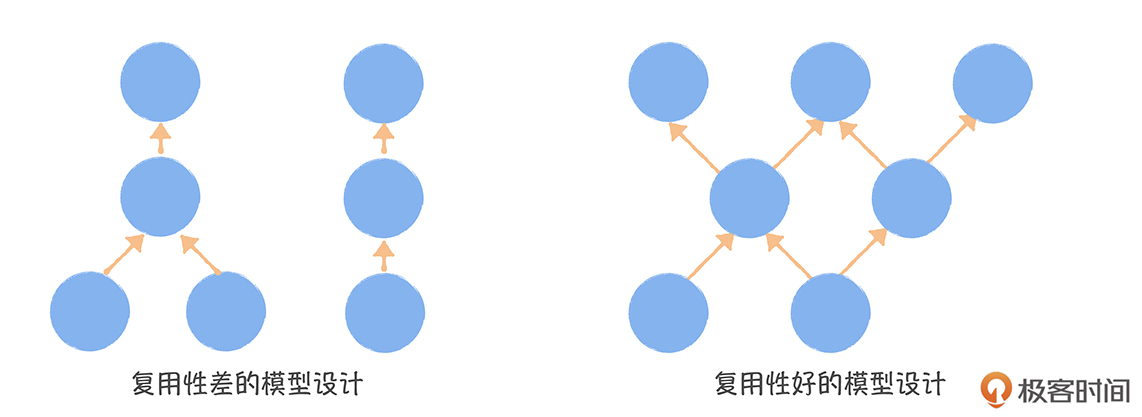
如何衡量规范度
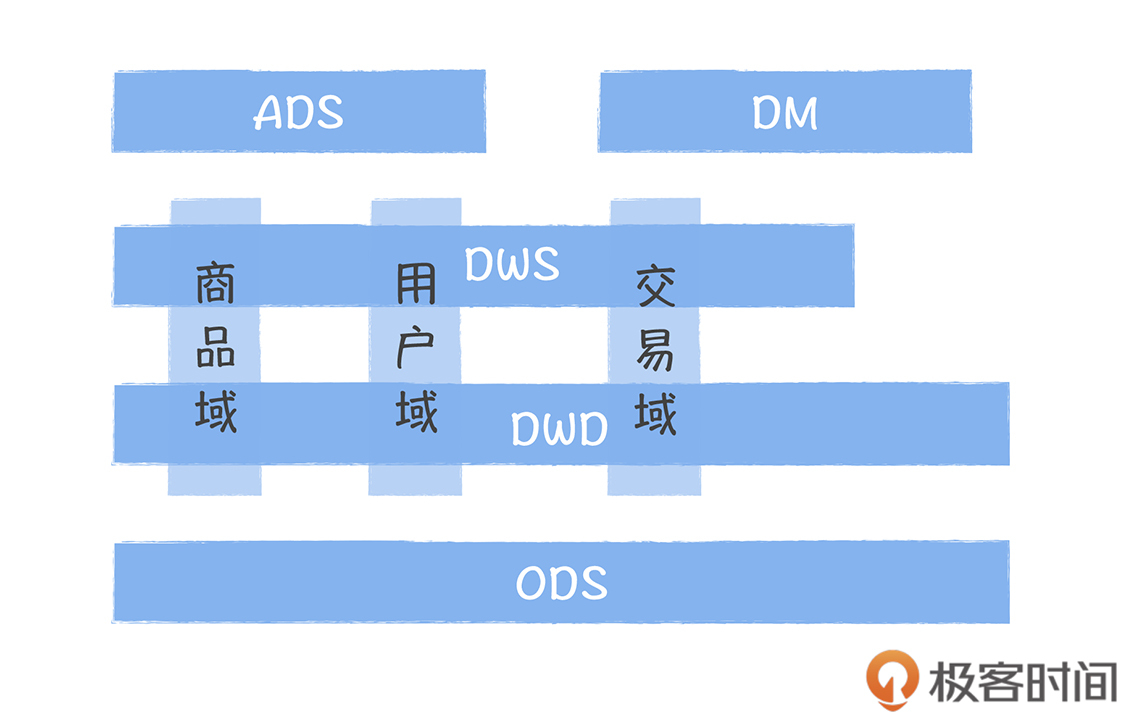
如何从烟囱式的小数仓到共享的数据中台

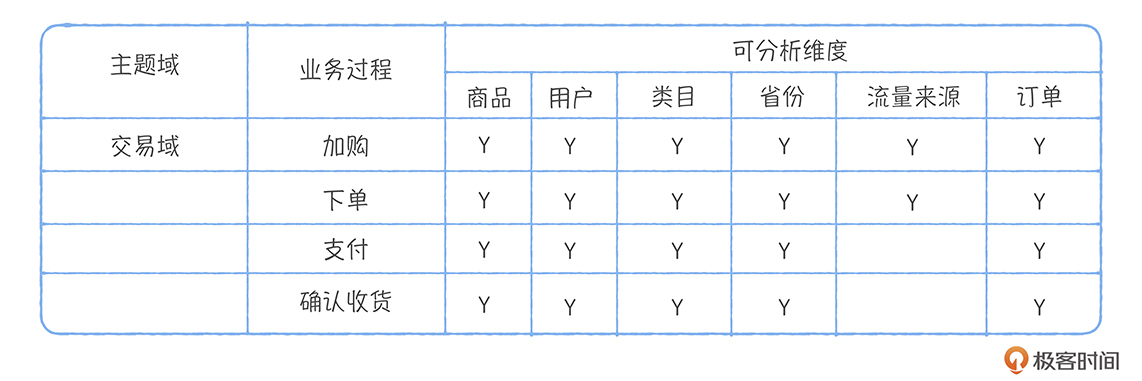

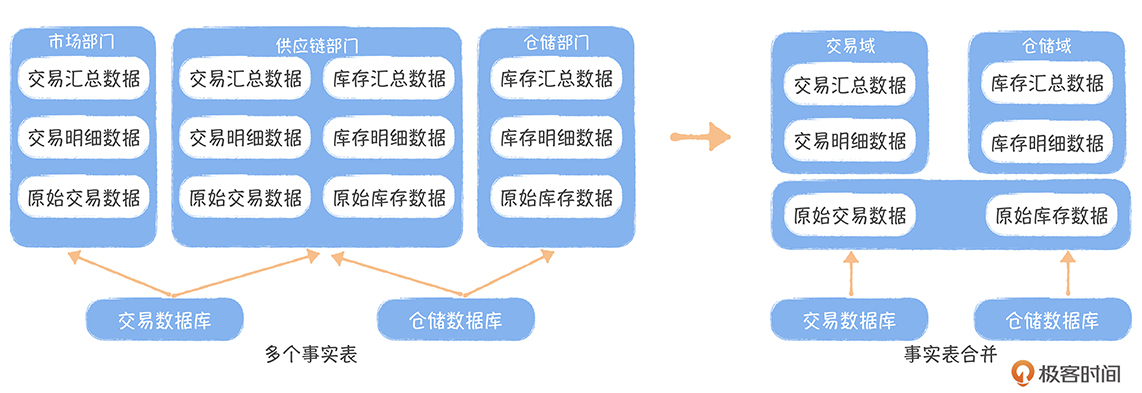
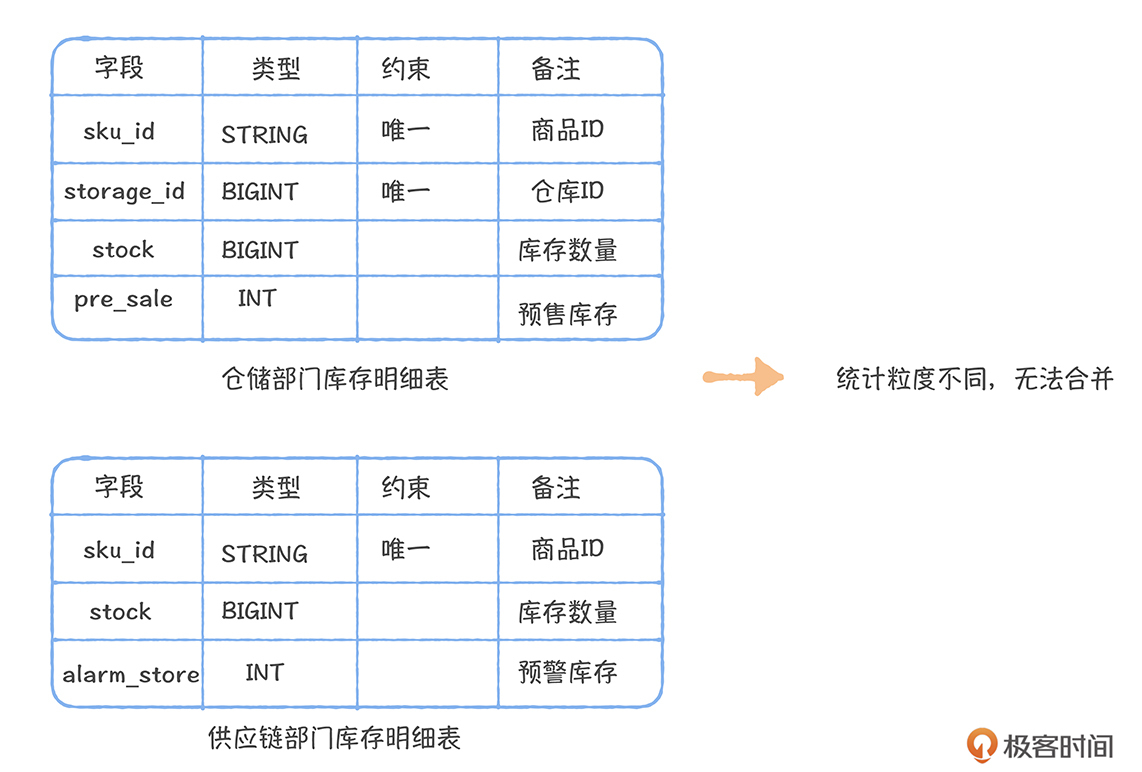
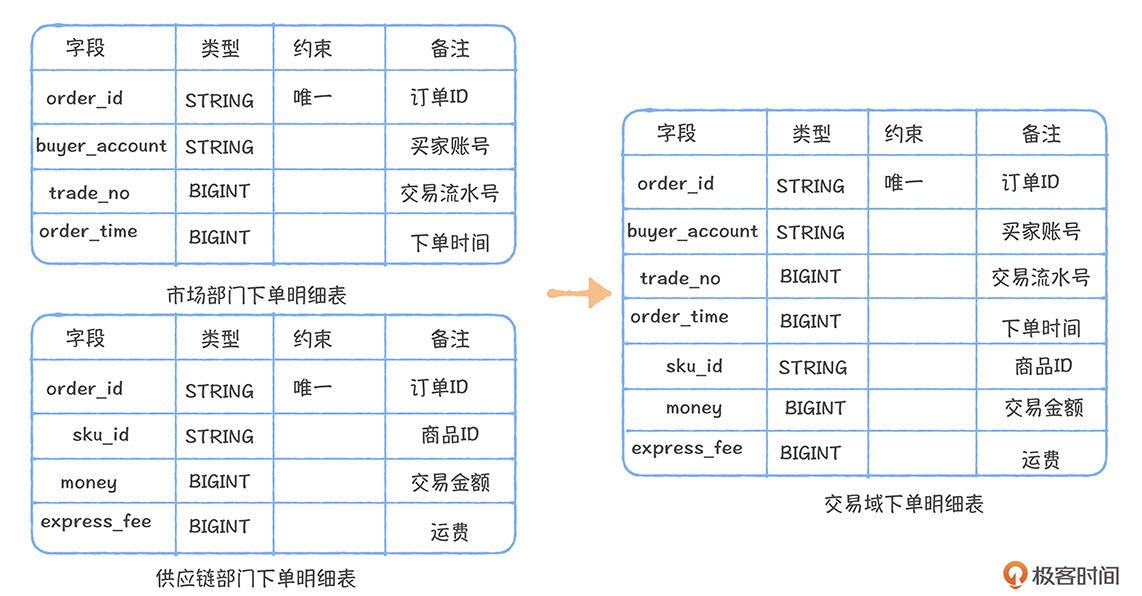
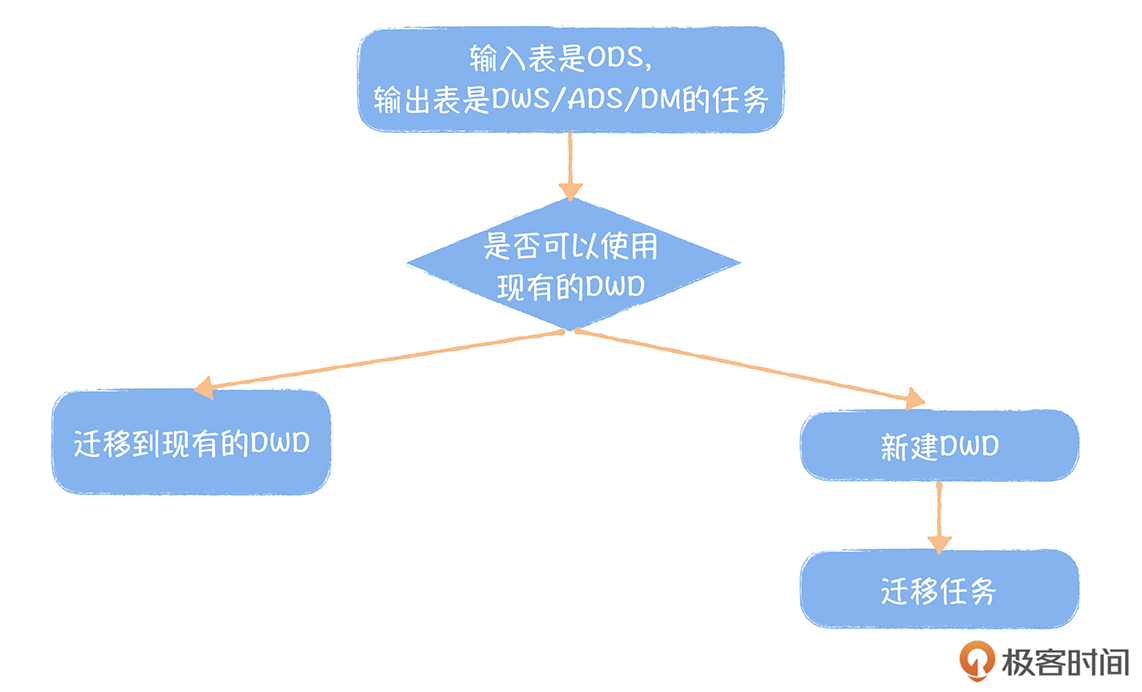
数仓建模工具 EasyDesign
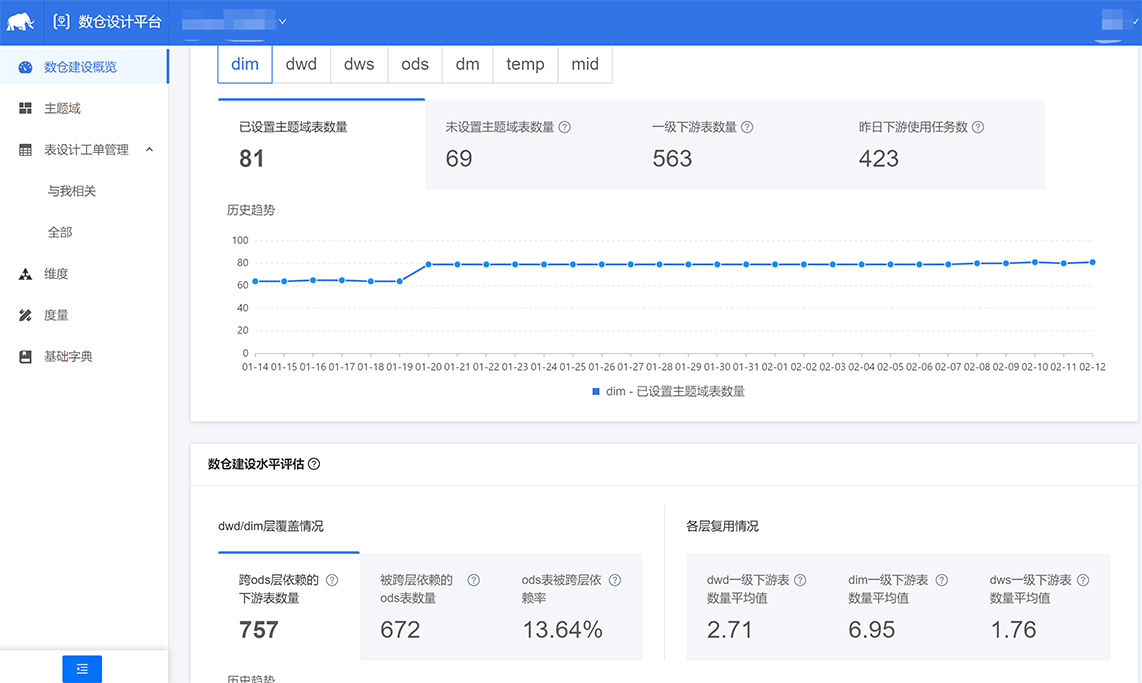
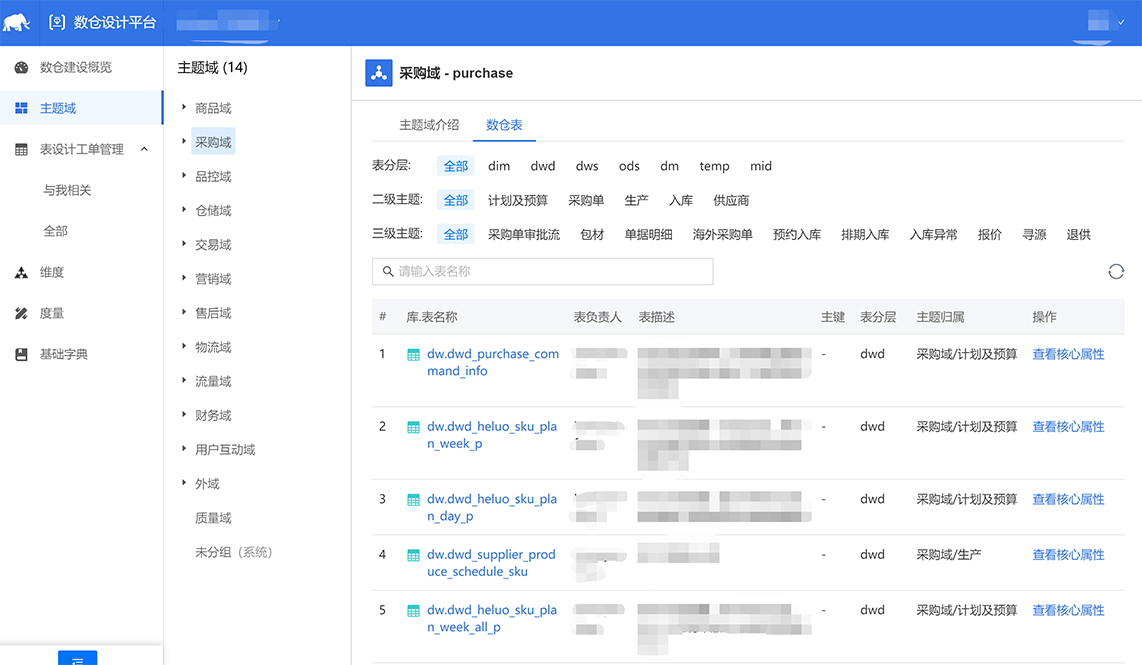
课堂总结
思考时间

精选留言(17)
 2020-04-151、先满足需求(活下去),再研发公共数据层(构建美好未来)。
2020-04-151、先满足需求(活下去),再研发公共数据层(构建美好未来)。
2、获得高层领导的支持,以获得更多的研发资源。
3、在满足业务需求的过程中,根据业务需求不断对公共数据层进行迭代和优化。
4、随着时间的推移 ,越来越多的日常业务需求可以用公共数据层(中台来完成)。
5、日常业务需求开发和公共数据层构建是相互促进的循环。展开作者回复: 不错,总结的挺好的,其实我只想再补充一点,就是为了保障数据中台的推进速度,可以尝试成立专人团队,这些人的目标明确就是中台构建,模型的重构和整合,指标的梳理。这些人不接业务需求,这样可以避免日常业务需求对数据团队的中台建设的干扰。否则的话,数据中台的建设进度,经常会受到业务需求压力的干扰,而且如果没有明确的KPI,或者KPI权重不够大,中台建设的动力也会不足。
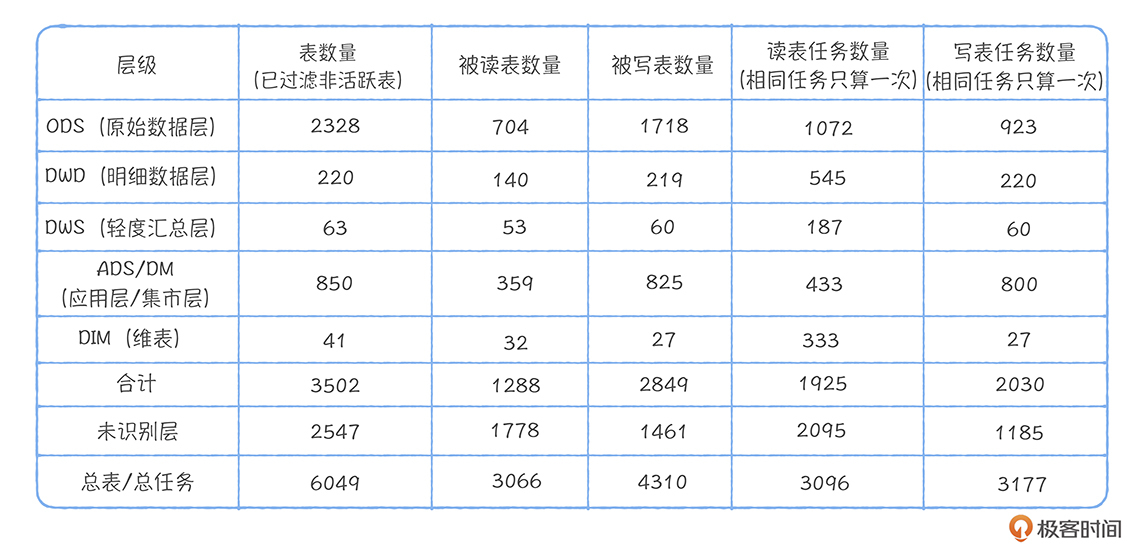
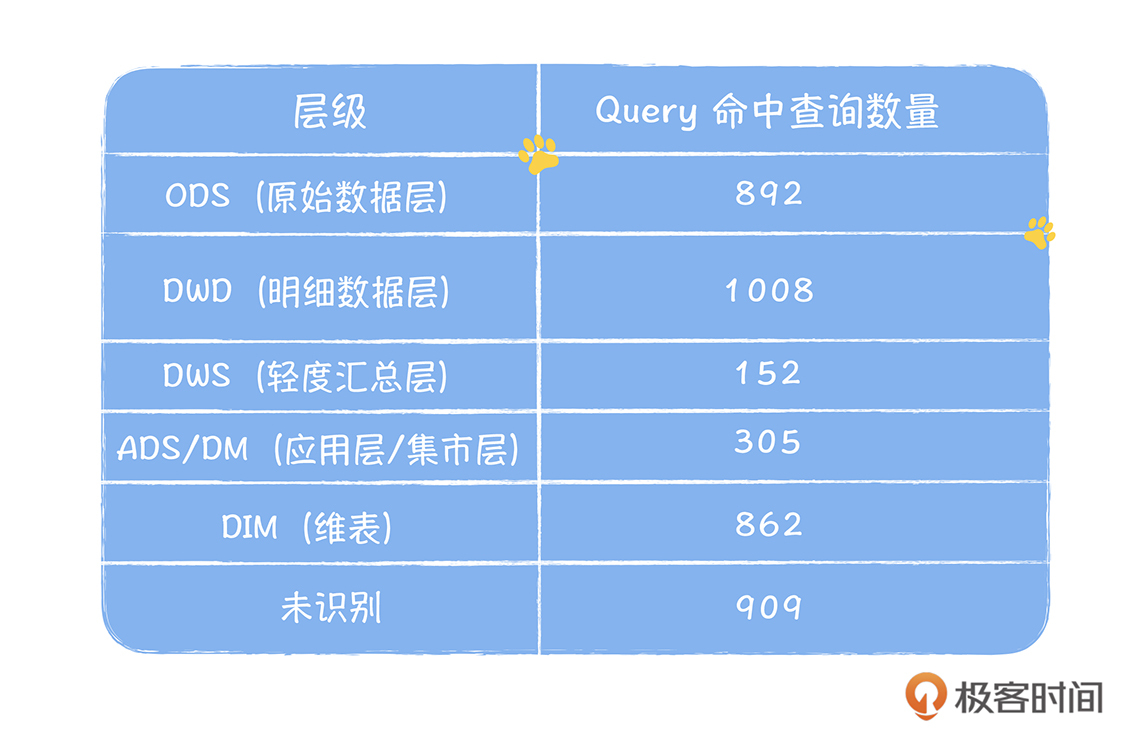
感谢你的阅读,总结的很棒! 3 2020-04-15郭老师好,请教一个小白的问题,运行任务和分析查询的统计是怎么统计的呢?我们现在的平台有用hive直接查的,有tableau连impala查询的,还有spark定时任务,各种各样的,怎么才能统计出像您这样的表格呢。也想做下自己的模型指标分析。十分感谢!展开
2020-04-15郭老师好,请教一个小白的问题,运行任务和分析查询的统计是怎么统计的呢?我们现在的平台有用hive直接查的,有tableau连impala查询的,还有spark定时任务,各种各样的,怎么才能统计出像您这样的表格呢。也想做下自己的模型指标分析。十分感谢!展开作者回复: 你好,可以基于数据血缘来实现,一个表的产出任务以及它的下游引用任务,数据血缘都是有的。
对于分析查询,目前我们有两个平台,一个是网易有数,类似tableau,一个是自助分析平台,就是执行SQL的,我们把这两个平台的日志执行信息会拿出来进行离线的分析和统计,然后去看每个query查询了哪些表。
如果你是tableau,可能没这么方便,不过可以试试从impala入手,impala侧日志中是有SQL信息,可以抓出来分析统计。对于spark和hive,可以基于数据血缘来实现。
感谢你的阅读~ 1 2 2020-04-16首先高优先级需求一定是先开发。
2020-04-16首先高优先级需求一定是先开发。
我觉得压缩空间在中台项目本身,
1.尽早搭建共享数仓部分。
措施:
技术上把各个小数仓的元信息和数据模型 通过自动化采集到同一个数据库中,进行分析,提炼指标。分析复用率。
业务上拉上各个部门核心BA,进行指标砍伐和提炼。
优先共享数仓产出,同时也应该按照优先级顺序。 高优先级的共享数据仓尽快产出,这样能用上,大家都会觉得中台的重要性。
2.中台开发过程挑选技术能手和业务能手快速完成迭代。
3.中台结束应该由业务方发起验收,减少建模的链路提高易用性是核心,这样才能让人人都用上中台。
4.后期运维需要建立强大监控环节,自顶向下监控资源,减少成本开销。
总结:技术上按照数仓设计就可以,中台的难点是对人员的业务和技术能力要求极高,同时需要一个优秀的PM。展开作者回复: 说的好,中台对数据开发的要求真的是挺高的,当然,也需要一些好用的工具产品来降低他们的工作量和复杂度,一个优秀的PM当然也是必须的。
我一直强调一个观点,不要用技术的思维看待数据中台,要用管理的思维,数据中台它是一个系统性的工程,对整个数据建设是一次革命!
感谢你的阅读,期待与你在留言区再次相遇,也期待你继续发表你的观点,很棒! 1 2020-04-16郭老师,刚接触数据中台,提的问题可能还比较初级,维表是一个基于的事实表的维表吗?他们之间是什么关系?需要ID关联吗?还是放到一张大的宽表中?多谢了!展开
2020-04-16郭老师,刚接触数据中台,提的问题可能还比较初级,维表是一个基于的事实表的维表吗?他们之间是什么关系?需要ID关联吗?还是放到一张大的宽表中?多谢了!展开作者回复: 你好,我来回到一下你的问题。
维表和事实表,可以通过ID关联,构建星型模型,甚至维度本身也可以构建有层次关系的星座模型。
在数据中台的集市层,或者汇总层,为了方便使用者使用,我们会做一些维度退化的设计,降低Join的次数,因为通过id关联,必须就会是涉及到join,join操作对计算引擎的性能要求比较高,所以会把一些常用的维度属性退化到事实表中,这个还是主要取决于业务场景和需求。
感谢你的阅读,期待与你再次相遇~ 1- 2020-04-15一致性维度能否详细解释下,有点不太理解展开
作者回复: 你好,我来回到一下你的问题。
在业务系统中,可能会存在用户表不一致的情况,那如果到数据中台来,我们就必须要构建统一的用户维表,不能存在多个用户维表,那这就导致我们没办法做一致性上卷,基于公共维度,实现多个事实的关联查询分析了。
所以在数据中台中,我们必须要统一维度,构建一致性维表。
感谢你的阅读,期待与你再次相遇~ 1  2020-04-15目前在做一个全新的领域,警务中台系统,跟原本的电商模式有着很大差别,本来一头雾水的项目,读了老师的课有点云开见月明的意思,提出一点个人的感想,不论是模型,还是输出的指标,个人感觉越来越多的应该从底层业务出发,自底向上来驱动整个业务中台,这里需要模型与业务与数据的多项循环反馈机制才能逐渐完善整个中台,如何将指标模块化,如何让各种模型即产中中间层结果,又产出直接结果,形成真正的积木式中台,让一线最懂业务的业务人员能够尽情发挥,搭建出自己想要的结果,形成逐层累积。
2020-04-15目前在做一个全新的领域,警务中台系统,跟原本的电商模式有着很大差别,本来一头雾水的项目,读了老师的课有点云开见月明的意思,提出一点个人的感想,不论是模型,还是输出的指标,个人感觉越来越多的应该从底层业务出发,自底向上来驱动整个业务中台,这里需要模型与业务与数据的多项循环反馈机制才能逐渐完善整个中台,如何将指标模块化,如何让各种模型即产中中间层结果,又产出直接结果,形成真正的积木式中台,让一线最懂业务的业务人员能够尽情发挥,搭建出自己想要的结果,形成逐层累积。
2.同时还要考虑这些模块和指标以及管理真的是我提了一个醒,目前是自己负责一个中台项目的指标模型建设,业务是自己,模型是自己,指标也是自己,但是当个多人参与进来要如果管理是我要学习的地方。
3.最后感慨一下,数据中台对从业人员的要求真的是高,要懂数据,懂运营,懂业务,懂模型,还要兼顾公司内过个部门的协同和沟通,不过也显示除了,未来人才的趋势就是全方位的人才才能真正立足于未来互联网。展开作者回复: 首先,感谢你的认可。看到对你的实际工作有所帮助和启发,我感到很高兴。
你说的非常正确,业务和数据中台之间本来就要相互反馈,业务人员经常去查一些明细表,那我们中台就要考虑,是不是需要完善汇总层的模型。
你说数据中台对从业人员要求高,我也非常赞同,数据中台从业务中来,最终必须要回到业务。数据中台团队独立于业务,但是绝对不能脱离业务。我在第13讲中,会详细的介绍,感谢你在留言区发表的想法,非常棒!
期待与你再次相遇~ 1- 2020-04-15目前公司数据中台建设已有一年有余,今天的内容有很多共鸣之处,收获颇多。
作者回复: 谢谢你的鼓励,期望能够对你后续的工作有所帮助和启发~
1  2020-04-23请教,在主题域这一层,老师认为是范式建模好,还是范式模式?现在很多银行传统数仓的主题层都是三范式建模。展开
2020-04-23请教,在主题域这一层,老师认为是范式建模好,还是范式模式?现在很多银行传统数仓的主题层都是三范式建模。展开 2020-04-23对于维表一直有疑惑。请问维表是否就是一张大宽表,作用是根据id和具体记录关联起来,在生成DWD表记录时补全记录缺失的维度值?麻烦老师解答。展开
2020-04-23对于维表一直有疑惑。请问维表是否就是一张大宽表,作用是根据id和具体记录关联起来,在生成DWD表记录时补全记录缺失的维度值?麻烦老师解答。展开- 2020-04-22郭老师好,我想问个模型分层的问题,我计算的一个指标从dwd层到dws层后就可以直接给到应用层了,那这个汇总表到底算是dws层的表还是ads层的表?展开
- 2020-04-19领导安排落地数仓分层定义及可实在落地 可度量 在这找到答案了
1、明确每层都有哪些表
2、通过分析执行sql知道 哪些表的使用情况 计算出 使用率
3、指标体系建设明确了业务指标和表的关系
4,血缘关系分析 明确了表之间的关系
5、表的采集知道表的属性
6、数据特征标签明确表使用的热度
7、数据地图,利于业务it 可视化查询了解数据资产展开作者回复: 非常高兴可以帮助到你~
感谢你的阅读,期待与你再次相遇~ - 2020-04-17老师,维度表的分表策略这个没有看懂,我理解维度表的数据应该是变化不大的,为什么还分那么多区,您能详细的再解释一下吗?展开
作者回复: 不一定哦,维表不一定是变化不大的,例如用户维表,相比事实表,确实变化算小的,但是并不是说维表是不变化的。每天还有有很多新增注册用户的!
感谢你的阅读,期待与你再次相遇~  2020-04-17郭老师,您好,非常感谢这么精彩的分享。
2020-04-17郭老师,您好,非常感谢这么精彩的分享。
有个问题请教,关于“一致性维度”的,业务场景如下:企业X有A和B两个系统,都有客户表(数据有部分交集(根据一定规则例如名称相同判断的),没有统一的客户中心),数据中台中客户维度是否只有一个?客户表的维度歧义处理是否是数据中台的职责?展开作者回复: 你好, 首先要感谢你的认可和鼓励。
我来谈谈你的问题。在数据中台中,用户维表必须要统一,不同业务系统用户不统一,在构建数据中台统一用户维表时,需要由中台部门来解决,可以使用ID-Mapping技术,打通不同系统之间的账号,建立统一的用户维表。
感谢你的阅读,期待与你再次相遇~ 2020-04-16非常具有实战的指导意义,感谢老师分享👍展开
2020-04-16非常具有实战的指导意义,感谢老师分享👍展开作者回复: 感谢你鼓励和认可,希望对你有所帮助,这些经验也确实是我们在过去一年中沉淀和总结下来的,比较有实践指导意义。
如果后续你有什么问题,可以直接在留言区与我交流。再次感谢你的阅读,下次见~ 2020-04-15老师文章里面说的每一点都有比较明确的实施意义!赞!
2020-04-15老师文章里面说的每一点都有比较明确的实施意义!赞!作者回复: 感谢你的阅读,也谢谢你的鼓励。
 2020-04-15任何情况下,都是以业务需求为主。数仓模型的优化,在完成需求的情况下,一步步优化。
2020-04-15任何情况下,都是以业务需求为主。数仓模型的优化,在完成需求的情况下,一步步优化。
老师,说的回收ods层数据,太对了,避免重复计算,模型重复建设。
维度建模方面,老师能详细讲解个案例吗,我们现在建模还不规范,想参考一下。展开作者回复: 你好,管住ODS,就掌握了主动权。
为了保证数据中台的推进速度,我反而建议成立独立的中台重构小团队,否则很容易受到业务需求的挤压。
至于维度建模的方法,后续我可以拿个案例与你来具体分享。
感谢你的阅读~ 2020-04-15这种解决方案其实是项目管理的事情,雷蓓蓓老师的《项目管理实战20讲》学完之后觉得所谓的安排已经一切从容多了;如何去合理安排每个项目的时间和工作完成度。。。相关的策略是关键。
2020-04-15这种解决方案其实是项目管理的事情,雷蓓蓓老师的《项目管理实战20讲》学完之后觉得所谓的安排已经一切从容多了;如何去合理安排每个项目的时间和工作完成度。。。相关的策略是关键。
换个方式去讲吧。我手上既有数据系统架构和代码优化的工作,同时还有运维系统优化的工作;如何合理去安排其实是我每天早上或者每个周期会去规划的事情,合理规划好自己有限的时间和精力-一切都不是真正的问题;只有紧急情况出现时才会出现如何处理事情优先级的问题。
谢谢老师今天的分享,期待后续的分享。展开作者回复: 蓓蓓,我12年做网易分布式数据库项目的时候,就是我们项目的PM啦。数据中台是一项系统性的工作,自然项目管理也是不可或缺的一部分。
感谢你的阅读~












