22 | 知识串讲(下):带你开发一个书店应用
2020-06-25 罗剑锋
罗剑锋的C++实战笔记
进入课程





讲述:Chrono
时长11:58大小10.97M
你好,我是 Chrono。
在上节课里,我给出了一个书店程序的例子,讲了项目设计、类图和自旋锁、Lua 配置文件解析等工具类,搭建出了应用的底层基础。
今天,我接着讲剩下的主要业务逻辑部分,也就是数据的表示与统计,还有数据的接收和发送主循环,最终开发出完整的应用程序。
这里我再贴一下项目的 UML 图,希望给你提个醒。借助图形,我们往往能够更好地把握程序的总体结构。
图中间标注为绿色的两个类 SalesData、Summary 和两个 lambda 表达式 recv_cycle、log_cycle 是今天这节课的主要内容,实现了书店程序的核心业务逻辑,所以需要你重点关注它。
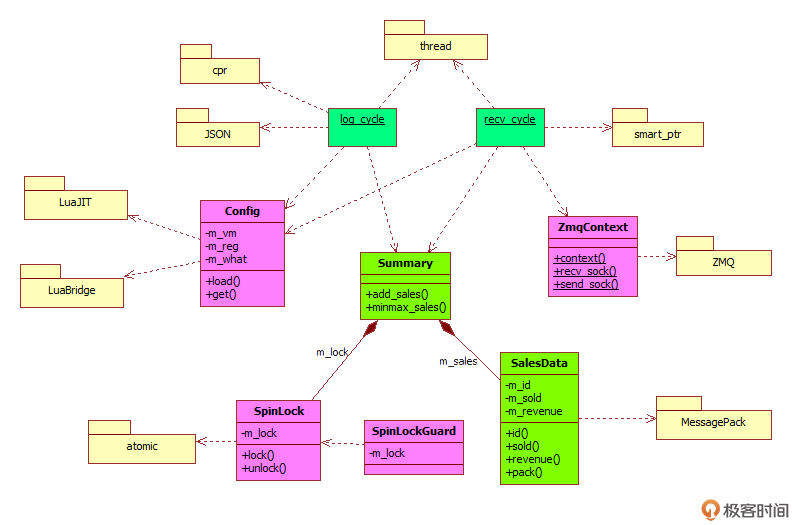
数据定义
首先,我们来看一下怎么表示书本的销售记录。这里用的是 SalesData 类,它是书店程序数据统计的基础。
如果是实际的项目,SalesData 会很复杂,因为一本书的相关信息有很多。但是,我们的这个例子只是演示,所以就简化了一些,基本的成员只有三个:ID 号、销售册数和销售金额。
上节课,在讲自旋锁、配置文件等类时,我只是重点说了说代码内部逻辑,没有完整地细说,到底该怎么应用前面讲过的那些 C++ 编码准则。
那么,这次在定义 SalesData 类的时候,我就集中归纳一下。这些都是我写 C++ 代码时的“惯用法”,你也可以在自己的代码里应用它们,让代码更可读可维护:
适当使用空行分隔代码里的逻辑段落;
类名使用 CamelCase,函数和变量用 snake_case,成员变量加“m_”前缀;
在编译阶段使用静态断言,保证整数、浮点数的精度;
使用 final 终结类继承体系,不允许别人产生子类;
使用 default 显示定义拷贝构造、拷贝赋值、转移构造、转移赋值等重要函数;
使用委托构造来编写多个不同形式的构造函数;
成员变量在声明时直接初始化;
using 定义类型别名;
使用 const 来修饰常函数;
使用 noexcept 标记不抛出异常,优化函数。
列的点比较多,你可以对照着源码来进行理解:
需要注意的是,代码里显式声明了转移构造和转移赋值函数,这样,在放入容器的时候就避免了拷贝,能提高运行效率。
序列化
SalesData 作为销售记录,需要在网络上传输,所以就需要序列化和反序列化。
为了方便使用,还可以为 SalesData 增加一个专门序列化的成员函数 pack():
不过你要注意,写这个函数的同时也给 SalesData 类增加了点复杂度,在一定程度上违反了单一职责原则和接口隔离原则。
如果你在今后的实际项目中遇到类似的问题,就要权衡后再做决策,确认引入新功能带来的好处大于它增加的复杂度,尽量抵制扩充接口的诱惑,否则很容易写出“巨无霸”类。
数据存储与统计
有了销售记录之后,我们就可以定义用于数据存储和统计的 Summary 类了。
Summary 类依然要遵循刚才的那些基本准则。从 UML 类图里可以看到,它关联了好几个类,所以类型别名对于它来说就特别重要,不仅可以简化代码,也方便后续的维护,你可要仔细看一下源码:
Summary 类的职责是存储大量的销售记录,所以需要选择恰当的容器。
考虑到销售记录不仅要存储,还有对数据的排序要求,所以我选择了可以在插入时自动排序的有序容器 map。
不过要注意,这里我没有定制比较函数,所以默认是按照书号来排序的,不符合按销售量排序的要求。
(如果要按销售量排序的话就比较麻烦,因为不能用随时变化的销量作为 Key,而标准库里又没有多索引容器,所以,你可以试着把它改成 unordered_map,然后再用 vector 暂存来排序)。
为了能够在多线程里正确访问,Summary 使用自旋锁来保护核心数据,在对容器进行任何操作前都要获取锁。锁不影响类的状态,所以要用 mutable 修饰。
因为有了 RAII 的 SpinLockGuard(第 21 讲),所以自旋锁用起来很优雅,直接构造一个变量就行,不用担心异常安全的问题。你可以看一下成员函数 add_sales() 的代码,里面还用到了容器的查找算法。
Summary 类里还有一个特别的统计功能,计算所有图书销量的第一名和最后一名。这用到了 minmax_element 算法(第 13 讲)。又因为比较规则是销量,而不是 ID 号,所以还要用 lambda 表达式自定义比较函数:
服务端主线程
好了,所有的功能类都开发完了,现在就可以把它们都组合起来了。
接下来的服务器主循环,我使用了 lambda 表达式,引用捕获上面的那些变量:
主要的业务逻辑其实很简单,就是 ZMQ 接收数据,然后 MessagePack 反序列化,存储数据。
不过为了避免阻塞、充分利用多线程,我在收到数据后,就把它包装进智能指针,再扔到另外一个线程里去处理了。这样主循环就只接收数据,不会因为反序列化、插入、排序等大计算量的工作而阻塞。
我在代码里加上了详细的注释,你一定要仔细看、认真理解:
你要特别注意 lambda 表达式与智能指针的配合方式,要用值捕获而不能是引用捕获,否则,在线程运行的时候,智能指针可能会因为离开作用域而被销毁,引用失效,导致无法预知的错误。
现在我们就能够接收客户端发过来的数据,开始统计了。
数据外发线程
recv_cycle 是接收前端发来的数据,我们还需要一个线程把统计数据外发出去。同样,我实现一个 lambda 表达式:log_cycle。
它采用了 HTTP 协议,把数据打包成 JSON,发送到后台的某个 RESTful 服务器。
搭建符合要求的 Web 服务不是件小事,所以这里为了方便测试,我联动了一下《透视 HTTP 协议》,用那里的 OpenResty 写了个的 HTTP 接口:接收 POST 数据,然后打印到日志里,你可以参考第 41 讲在 Linux 上搭建这个后台服务。
log_cycle 其实就是一个简单的 HTTP 客户端,所以代码的处理逻辑比较好理解,要注意的知识点主要有三个,都是前面讲过的:
你如果有点忘了,可以回顾一下,再结合下面的代码来理解、学习:
然后,还是要在主线程里用 async() 函数来启动这个 lambda 表达式,让它在后台定时上报数据。
这样,整个书店程序就全部完成了,试着去编译运行一下看看吧。
小结
好了,今天我就把书店示例程序从头到尾给讲完了。可以看到,代码里面应用了很多我们之前讲的 C++ 特性,这些特性互相重叠、嵌套,紧凑地集成在了这个不是很大的程序里,代码整齐,逻辑清楚,很容易就实现了多线程、高性能的服务端程序,开发效率和运行效率都非常高。
我再对今天代码里的要点做个简单的小结:
编写类的时候要用好 final、default、using、const 等关键字,从代码细节着手提高效率和安全性;
对于中小型项目,序列化格式可以选择小巧高效的 MessagePack;
在存储数据时,应当选择恰当的容器,有序容器在插入元素时会自动排序,但注意排序的依据只能是 Key;
在使用 lambda 表达式的时候,要特别注意捕获变量的生命周期,如果是在线程里异步执行,应当尽量用智能指针的值捕获,虽然有点麻烦,但比较安全。
那么,这些代码是否对你的工作有一些启迪呢?你是否能够把这些知识点成功地应用到实际项目里呢?希望你能多学习我在课程里给你分享的开发技巧和经验建议,熟练地掌握它们,写出媲美甚至超越示例代码的 C++ 程序。
课下作业
最后是课下作业时间,这次就不是思考题,全是动手题,是时候检验你的编码实战能力了:
再补充一点,在动手实践的过程中,你还可以顺便练习一下 Git 的版本管理:不要直接在 master 分支上开发,而是开几个不同的 feature 分支,测试完确认没有问题后,再合并到主干上。
欢迎你在留言区写下你的思考和答案,如果觉得今天的内容对你有所帮助,也欢迎分享给你的朋友。我们下节课见。


© 加微信:642945106 发送“赠送”领取赠送精品课程 发数字“2”获取众筹列表。
上一篇
21 | 知识串讲(上):带你开发一个书店应用
下一篇
期末测试 | 这些C++核心知识,你都掌握了吗?
写留言
17161436 65 拼课微信(7)
 2020-06-28老师,还想问一下,为啥不用std::lock_guard,自己写一个lock呢,只为了性能嘛?
2020-06-28老师,还想问一下,为啥不用std::lock_guard,自己写一个lock呢,只为了性能嘛?作者回复: 示例代码,当然都是自己写出来比较好了,可以实践一下编码准则。
1- 2020-06-28代码里显式声明了转移构造和转移赋值函数,这样,在放入容器的时候就避免了拷贝,能提高运行效率。
那么被转移的类会被掏空了,使得内部数据无效吗?展开作者回复: 需要理解转移语义,它的目的就是要把原对象的内容给“偷走”,转移到新的对象里。
这样原对象就空了,但数据依然是有效的,比如0、nullptr,只是没有了实际意义,可以被安全、轻量地销毁。 1 - 2020-06-26我碰到一个pybind11的问题:代码Client.cpp使用了第三方zmq组件,如果要转化成python可以调用的模块,除了适配Client.cpp自身接口需要用pybind11声明外,zmq涉及到的接口也要做么?
看转换的格式比较固定,是不是有自动化的工具来做这件事呢?展开作者回复: 可以把zmq的调用封装起来,不对外暴露zmq接口,Python调用只传递几个参数。
- 2020-06-261、Thread生成的地方,没有去做异常检查,我不太确定需不需要?
2、假如使用python脚本去简化客户端测试,是不是通过PYBIND11的方式把Client.cpp里的接口转化成python能够加载模块,在利用python测试该模块?
3.可以将SalesData里面涉及pack和upack的部分拆分出来,用工厂方法进行替换;工厂类可以借用STL将不同类型数据格式和对应工厂类映射起来;在通过配置文件增加该类型的配置,解析到数据类型后,关联到对应的工厂类产生对应的对象,基于此来动态切换实现pack和unpack的数据格式。展开作者回复:
1.只要没有显式声明noexcept的地方,其实都应该加上try-catch。
2.对,用C++写底层接口,然后用Python、lua去调用。
3.思路很对。  2020-06-25为什么不用智能指针 unique_ptr,而是一定要自己重新写一个 SpinLockGuard?
2020-06-25为什么不用智能指针 unique_ptr,而是一定要自己重新写一个 SpinLockGuard?作者回复: unique_ptr只能管理对象的生命周期,自动销毁堆上的对象。而SpinLockGuard的目的是在生命周期结束时自动解锁。
虽然用的都是RAII技术,但两者的行为、作用不同。 2020-06-25课下作业第3应该说的是客户端和服务器端吧展开
2020-06-25课下作业第3应该说的是客户端和服务器端吧展开作者回复: 可以看一下21讲,这个服务器前面是前端服务,不是直接的客户端,当然,说是客户端也可以,毕竟是示例程序,不那么严格。
- 2020-06-25每次接受请求,都开启一个线程,是否合理?展开
作者回复: 每个请求开新线程的代价是比较高的,但课程里的代码只是为了演示目的,实际项目里最好用线程池。
1


