02 | 分离关注点:软件设计至关重要的第一步





讲述:郑晔
时长11:20大小10.39M
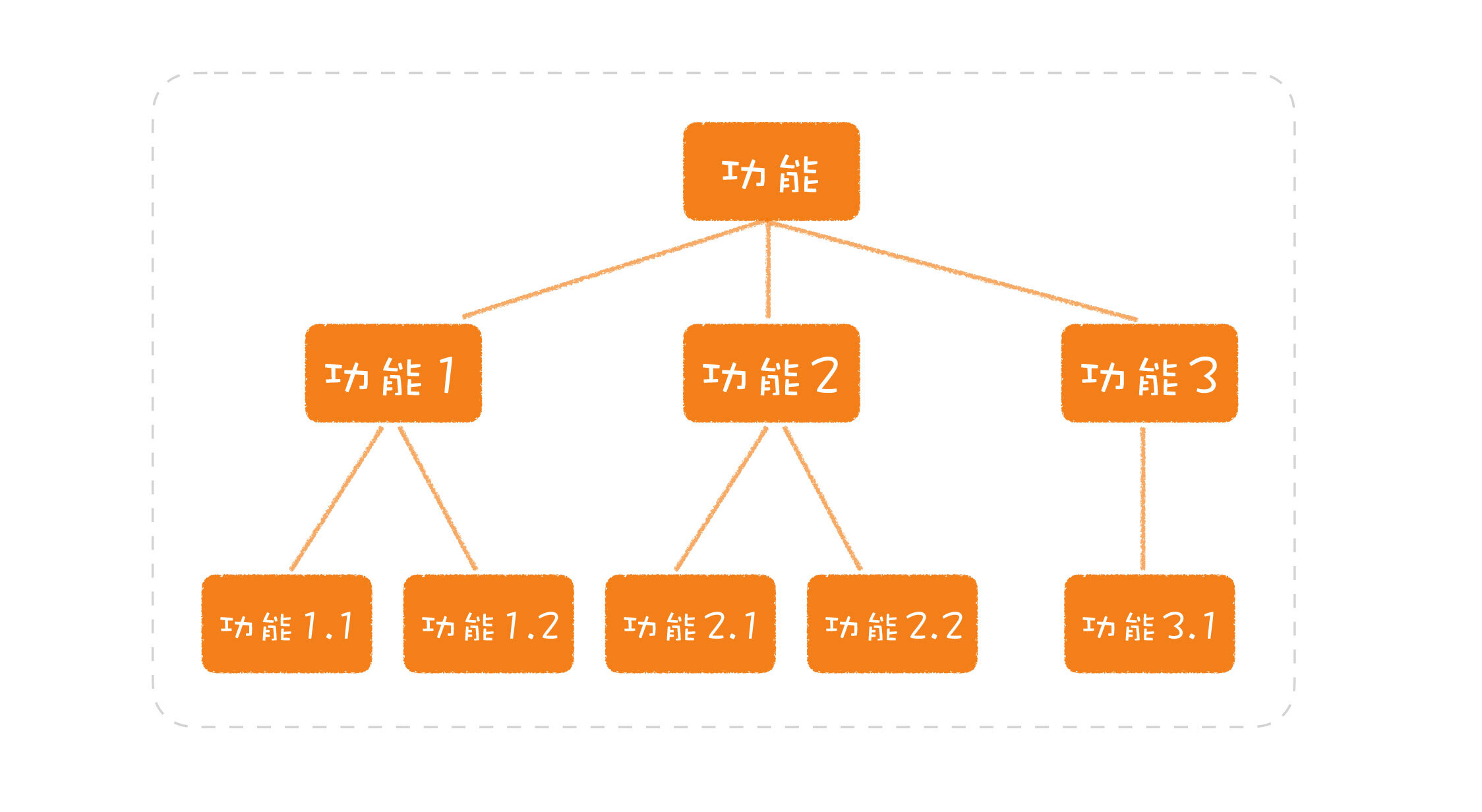
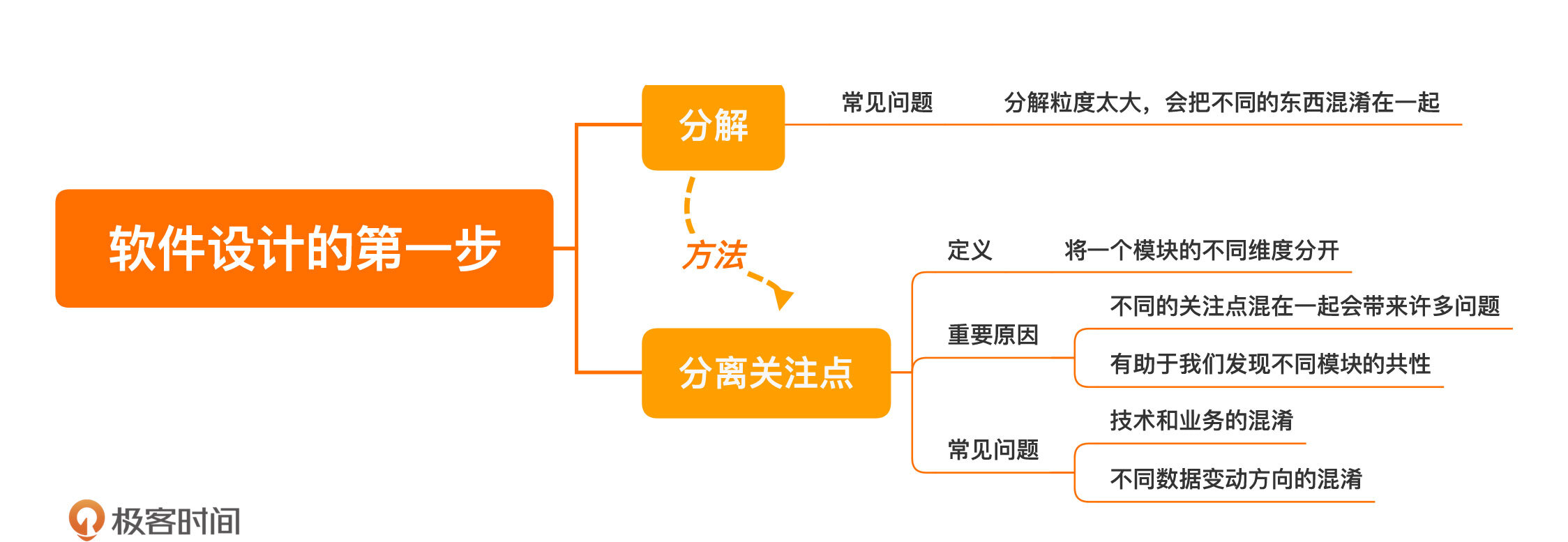
一个失败的分解案例
分离关注点
总结时刻
思考题

1716 143665 拼课微信(23)
 2020-05-27能提供关于分离关注点更多的例子或者相关资料吗?展开
2020-05-27能提供关于分离关注点更多的例子或者相关资料吗?展开作者回复: 专栏后面还会多次提到分离关注点的,敬请期待!
8 2020-05-28老师 比如说订单系统 先下单写到数据库 然后发送消息给消息队列 这两部 没法放到一个事务中去。 如果用本地消息表, order 写数据库 然后 在写本地消息表 这样这两步就放到一个事务中去了 保证肯定成功, 然后在有线程 读取本地消息表 发送队列 如果成功更改本地消息表状态 。 从设计角度讲这就没分离关注点, 这个应该怎么分呀?展开
2020-05-28老师 比如说订单系统 先下单写到数据库 然后发送消息给消息队列 这两部 没法放到一个事务中去。 如果用本地消息表, order 写数据库 然后 在写本地消息表 这样这两步就放到一个事务中去了 保证肯定成功, 然后在有线程 读取本地消息表 发送队列 如果成功更改本地消息表状态 。 从设计角度讲这就没分离关注点, 这个应该怎么分呀?展开作者回复: 我们来分析一下这个需求,下单入库和发消息给下游,这确实是两个动作,但这两个动作的顺序一定是这样吗?它们一定要在一个线程里完成吗?
我们可不可以先发消息呢?比如,我们把消息发给下游之后,有一个下游接收到消息之后,再把消息入库。如果这样做的话,发消息,由消息队列保证消息不丢,下游入库,又可以保证订单持久化。你看,在这个设计中,其实,并不需要事务,所以,我们也不必为事务纠结了。 1 7 2020-05-271.cqrs,命令与查询分离,最早是在ddd实战里面看到。其分离啦增删改与查询这两个关注点。
2020-05-271.cqrs,命令与查询分离,最早是在ddd实战里面看到。其分离啦增删改与查询这两个关注点。
2.静态上,拆分了这两块的代码。使各自可以采用不同的技术栈,做针对性的调优。动态上,切分了流量,能够更灵活的做资源分配。
3.查询服务的实现。可以走从库,这有利于降低主库压力,也可以做到水平扩展。但需要注意数据延迟的问题。在异步同步和同步多写上要做好权衡。
也可以都走主库,这时候查询服务最好能增加缓存层,以降低主库压力,而增删改服务要做好缓存的级联操作,以保证缓存的时效性。
当然也可以走非关系型数据库,搜索引擎类的es,solr,分布式存储的tidb等等,按需选择。展开作者回复: 非常棒的分享!
1 7 2020-05-27有感觉,但是又不明确,没有get到那个点,应该举一下具体的业务来说明或者证明,感觉是理论上的
2020-05-27有感觉,但是又不明确,没有get到那个点,应该举一下具体的业务来说明或者证明,感觉是理论上的作者回复: 你把你困惑的点提出来,我争取进一步讲清楚。
我在部落里写了一个回答,可以参考一下。
http://gk.link/a/10iHp 6 2020-05-27想起Kent Beck 说的一句话,大致意思是:我不准备在这本书里讲高并发问题,我的做法是把高并发问题从我的程序里移出去展开
2020-05-27想起Kent Beck 说的一句话,大致意思是:我不准备在这本书里讲高并发问题,我的做法是把高并发问题从我的程序里移出去展开作者回复: 没错,就是这样。
6 2020-05-27近期有一本书《被统治的艺术》,正好和软件设计中的职责分离策略异曲同工。
2020-05-27近期有一本书《被统治的艺术》,正好和软件设计中的职责分离策略异曲同工。
我们知道明朝自朱元璋开始有一个顶层设计,就是每家每户做什么,一开始就规定好了。军队也是一个固定职业,即军户制。比如说国家需要100万个士兵,那就要有100万个军户,每户出一个兵,世世代代都是这样。如果这个兵逃了或者死了怎么办?家族里就再出一个来补充。
这会带来什么后果呢?你可以想象一下,如果儿童节的时候你正坐在家里跟妻子儿女享天伦之乐,忽然有人闯进来,把你抓走了去当兵,只是因为你家族里面的另外一个人当了逃兵或者死掉了。
可见,这样的顶层设计会给自己的家族带来各种不确定性甚至家庭悲剧。人民群众想出了很多的策略来对付这样的制度。
有种设计是这样的,就是每个家族中选出一个分支代表整个家族去当兵,与之相对的是家族的其他分支需要共同出一笔钱,世世代代赡养这个当兵的分支。此外还有其他一些「福利」,比如说,如果原本他在家族中的排位比较低,那他的后代就可以在家族的各项活动中提升座次。
这个世世代代当兵的分支会比较惨,但带来的好处是这个家族中的其他分支就会少受骚扰,得以繁衍。
事实上这样的策略运行得不错,有些家族好几代人一直都执行这样的策略,甚至贯穿了几乎整个明代。
某种角度说,这就是一种职责分离,将国家统治的要求和家族稳定繁衍的需要分开。展开作者回复: 刚好最近万维钢老师讲了这本书中的内容,但你从软件设计的角度去理解这个问题,确实让人有一种耳目一新的感觉。
1 3 2020-05-27技术和业务混杂的情况,让我想起来一篇文章,大意是说要区分技术异常和业务异常的。也就是说,技术层面的异常信息不应该暴露给上层的业务人员。典型的例子就是大型网站的错误页面,而不是直接把后台的npe堆栈信息抛给用户。展开
2020-05-27技术和业务混杂的情况,让我想起来一篇文章,大意是说要区分技术异常和业务异常的。也就是说,技术层面的异常信息不应该暴露给上层的业务人员。典型的例子就是大型网站的错误页面,而不是直接把后台的npe堆栈信息抛给用户。展开作者回复: 这是一个很好的例子,确实要做区分。
1 3 2020-05-29老师,我觉得补偿机制还是要的吧,就算换吞吐量大的消息队列,丢失消息还是有可能出现的,只是几率小很多。只是他补偿机制设计得不合理?展开
2020-05-29老师,我觉得补偿机制还是要的吧,就算换吞吐量大的消息队列,丢失消息还是有可能出现的,只是几率小很多。只是他补偿机制设计得不合理?展开作者回复: 如果我们分析是不是丢消息,就要看它在什么情况下丢消息。在之前的业务场景中,丢消息就是因为消息队列处理不过来,而我们换了吞吐更好的队列就不存在这个问题了。
其实,我们真正需要的是可靠的信息传送通道,至于是不是消息队列不重要。如果怕丢消息,可以在生产者端重试,可以在消费者端做幂等。补偿是一个能把场景弄复杂的做法,不鼓励。 2- 2020-05-27老师 能具体说说加了消息队列的数据流成什么样了 为啥能解决对消息问题呀
作者回复: 这里并不是说增加了消息队列解决的问题,原有的解决方案用的也是消息队列。
这里的重点是,用了一个吞吐能力更强的队列,保证了消息的不丢失,这样我们就不必专门处理消息丢失的问题了。通信的问题在通信的层面得到了解决,就不会影响到其它的代码了。 2 - 2020-05-27我发现大家在工作中往往不做分离,分析需求的时候把方案揉在一起。
可以怎样去练习做分离呢?展开作者回复: 有一种从小事练起的方法,就是写代码时,把自己写的函数行数限定在一定的规模之下,比如,10行。超过10行的代码,你就要去仔细想想是否是有东西混在了一起。
这种方法锻炼的就是找出不同关注点的思维习惯,一旦你具备了这种思维习惯,再去看大的设计,自然也会发现不同的关注点。 2  2020-05-271. 在软件设计中,大家是期望将粒度分解的越小越好,但又往往嫌分解太小过于麻烦。就像,希望别人把文档写好,自己却又不写( ̄_, ̄ )
2020-05-271. 在软件设计中,大家是期望将粒度分解的越小越好,但又往往嫌分解太小过于麻烦。就像,希望别人把文档写好,自己却又不写( ̄_, ̄ )
2. 业务处理和技术实现很容易被混在一起,原因也确实是分离的不够┭┮﹏┭┮展开作者回复: 太过真实了:想好,又不希望自己做得太多。
2- 2020-05-29最近听到大家的一些技术设计。有些同事在偏业务数据驱动的系统里用了juc里的比如原子操作。虽然对大家提升技术水平有一定益处,但从软件设计角度来说,未必是好事,应该尽力避免。
作者回复: 把技术和业务分开,至少意识上要先行。
1  2020-05-28似懂非懂,技术与业务的分割线太模糊。代码的重构优化会点,但是分离关注点就涉及到具体的业务了,具体业务的划分与分离就又迷茫了。😭😭😭😭😭😭😭展开 1
2020-05-28似懂非懂,技术与业务的分割线太模糊。代码的重构优化会点,但是分离关注点就涉及到具体的业务了,具体业务的划分与分离就又迷茫了。😭😭😭😭😭😭😭展开 1 2020-05-28一身冷汗,要从根本上提升分解能力展开
2020-05-28一身冷汗,要从根本上提升分解能力展开作者回复: 赶紧分解起来。
1 2020-05-28其实这里面很多问题是由于无意识造成的,在设计时需要有意识的设计,逐渐把有意识训练成下意识
2020-05-28其实这里面很多问题是由于无意识造成的,在设计时需要有意识的设计,逐渐把有意识训练成下意识作者回复: 很好的点,确实需要有意识的训练。
我在部落里写了一个回答,可以参考一下。
http://gk.link/a/10iHp 1 2020-05-28注意分解粒度,分离关注点,这些很重要,
2020-05-28注意分解粒度,分离关注点,这些很重要,
但问题是如何分解,如何分离关注点,具体有哪些工程实践?展开作者回复: 我在部落里面写了一个回答,可以看一下。
http://gk.link/a/10iHp 1- 2020-05-28软件设计第一步是对业务功能进行分解,如何分解是有讲究的,分解子功能的粒度尽量要小。文中提到交易原语的例子,通过子功能来实现大功能的逻辑,其实也就是分层的思想。每一层关注自己的业务逻辑,对外提供接口展开 1
 2020-05-27“如果将前台访问(处理增删改查)和后台访问(统计报表)分开,纠结也就不复存在了。”
2020-05-27“如果将前台访问(处理增删改查)和后台访问(统计报表)分开,纠结也就不复存在了。”
老师请恕我愚钝,所以将高低频分开之后是分别采用Spring Data JPA和Mybatis来实现进行数据库访问吗?如果是的话,那不是相当于在同一个项目中引入了两套数据库访问规范,会不会造成开发规范上的困惑甚至混乱?如果不是的话,那正确做法又应该是什么?展开作者回复: 如果把二者分开,这可以就是两个项目,一个前台项目,一个后台项目。两个独立的项目各自采用一套编程规范,不就很正常了。
1 2020-05-27看完貌似懂了,细想完全没懂展开
2020-05-27看完貌似懂了,细想完全没懂展开作者回复: 欢迎把困惑提出来,我争取帮你解惑。
1 2020-05-27分解的粒度一般到什么样的层级才能更好的分析共通性以及更好的组合呢?
2020-05-27分解的粒度一般到什么样的层级才能更好的分析共通性以及更好的组合呢?作者回复: 这就是我建议的由来,越小越好。最小的粒度就是函数,函数写得越小越好。怎么写小呢?就是要分解出更小的粒度,这是一种练习的方法。
1













