04 | 匹配模式:一次性掌握正则中常见的4种匹配模式





讲述:涂伟忠
时长13:00大小11.91M
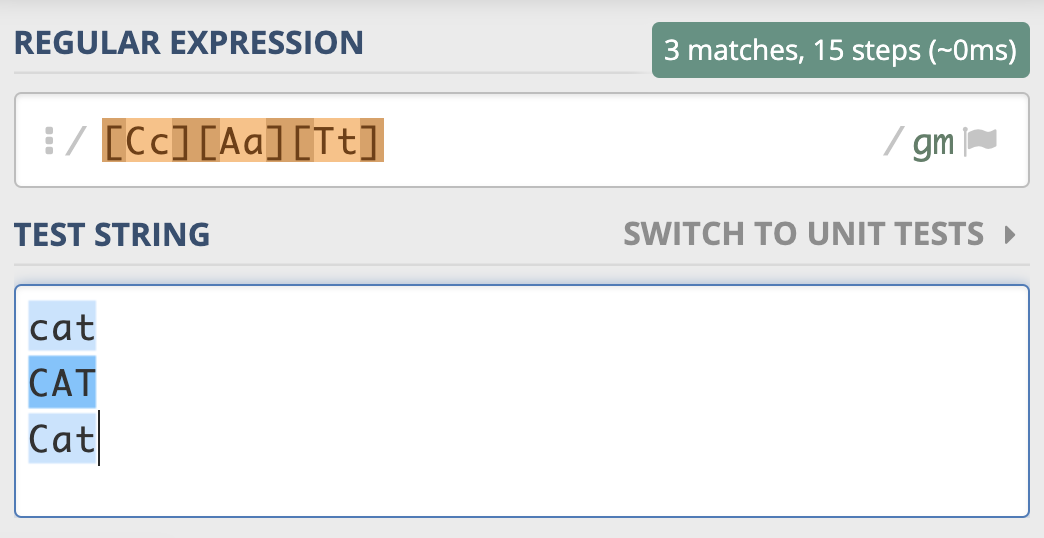
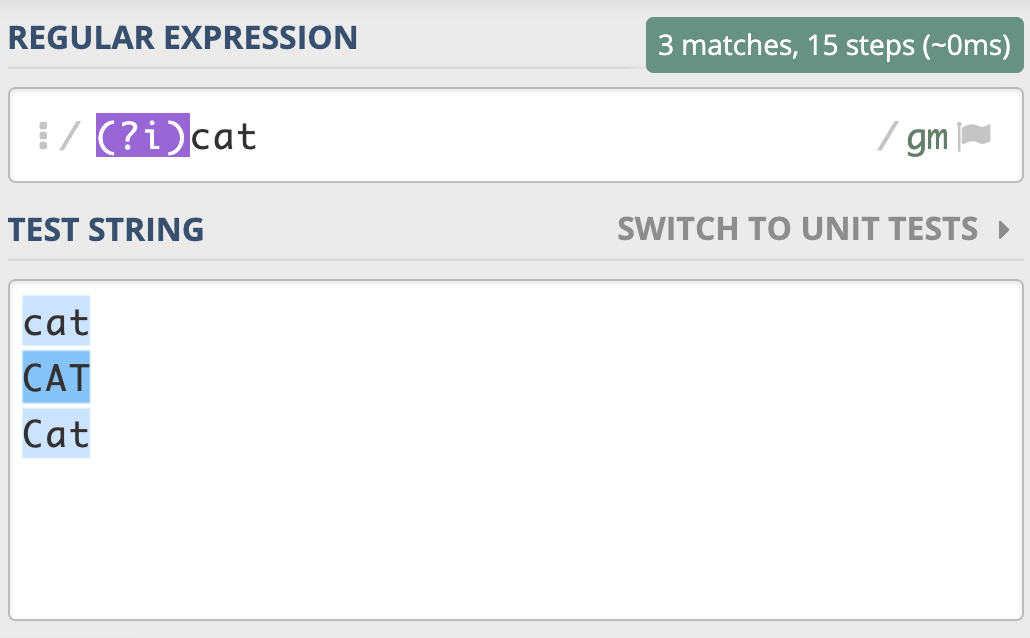
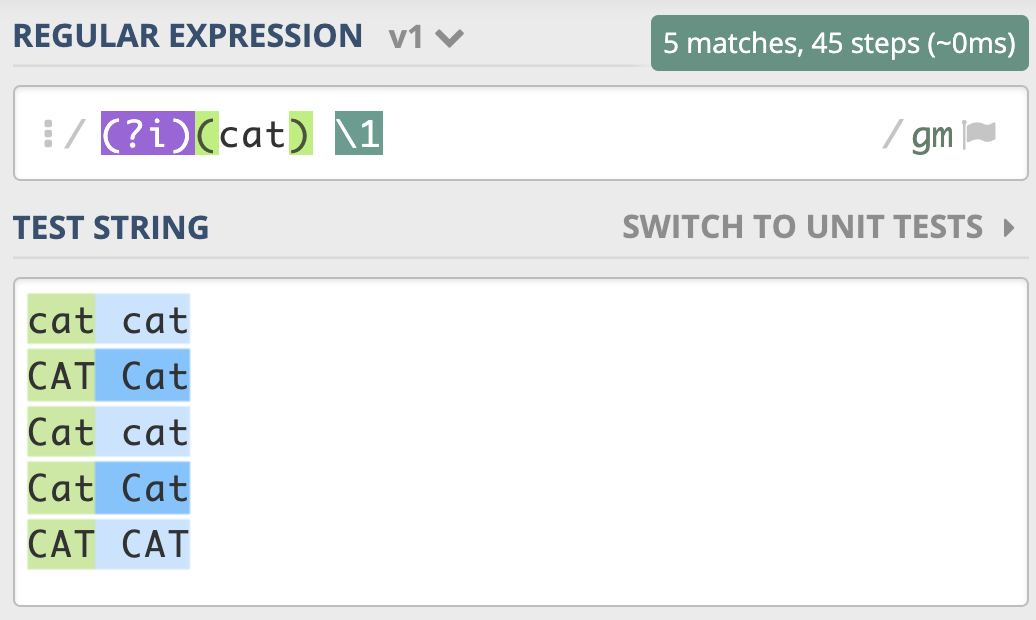
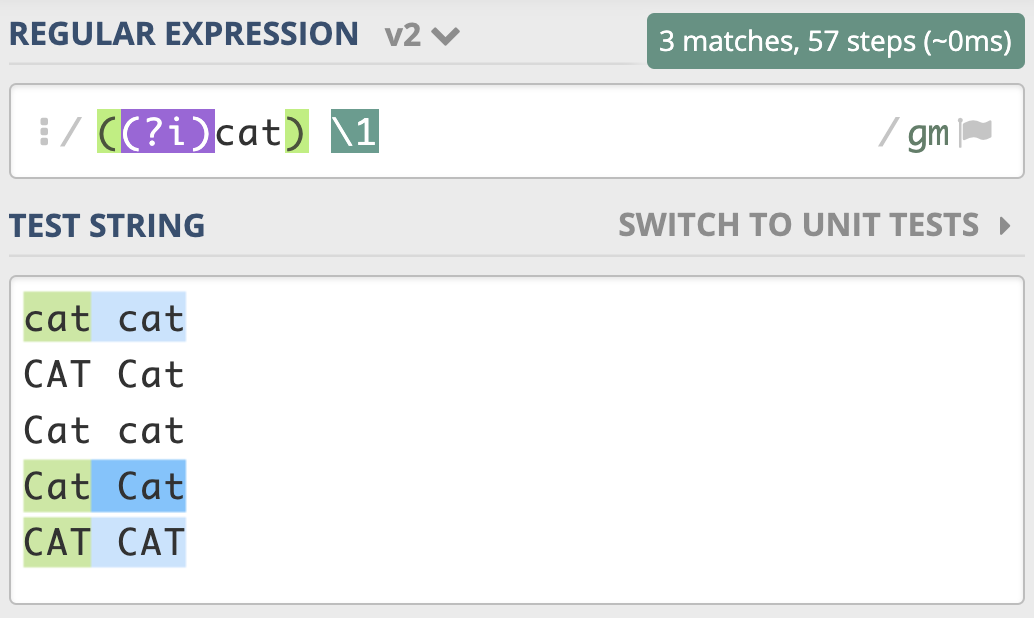
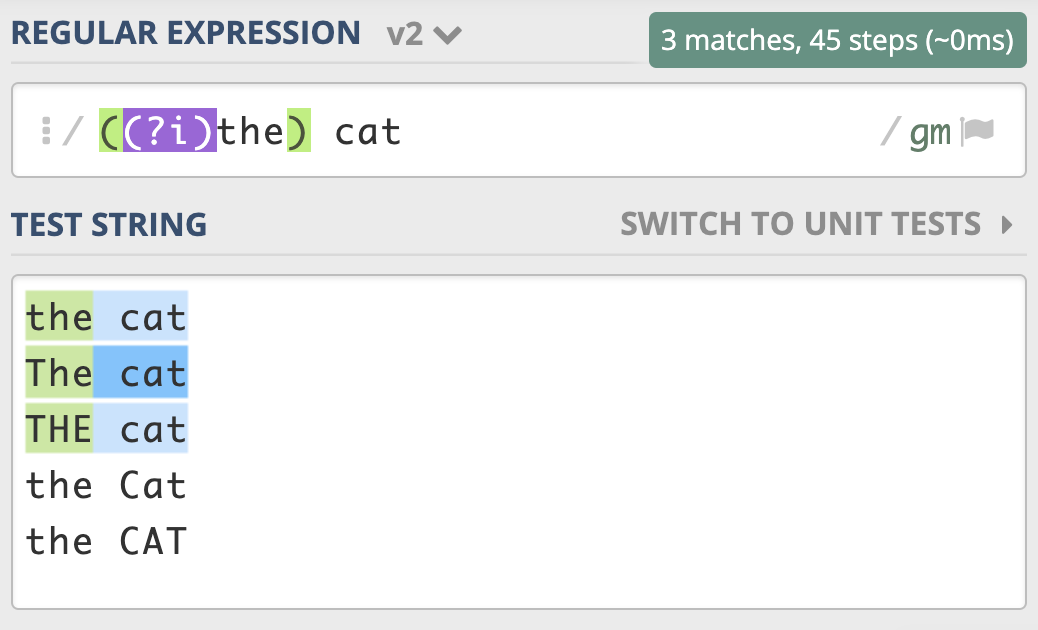
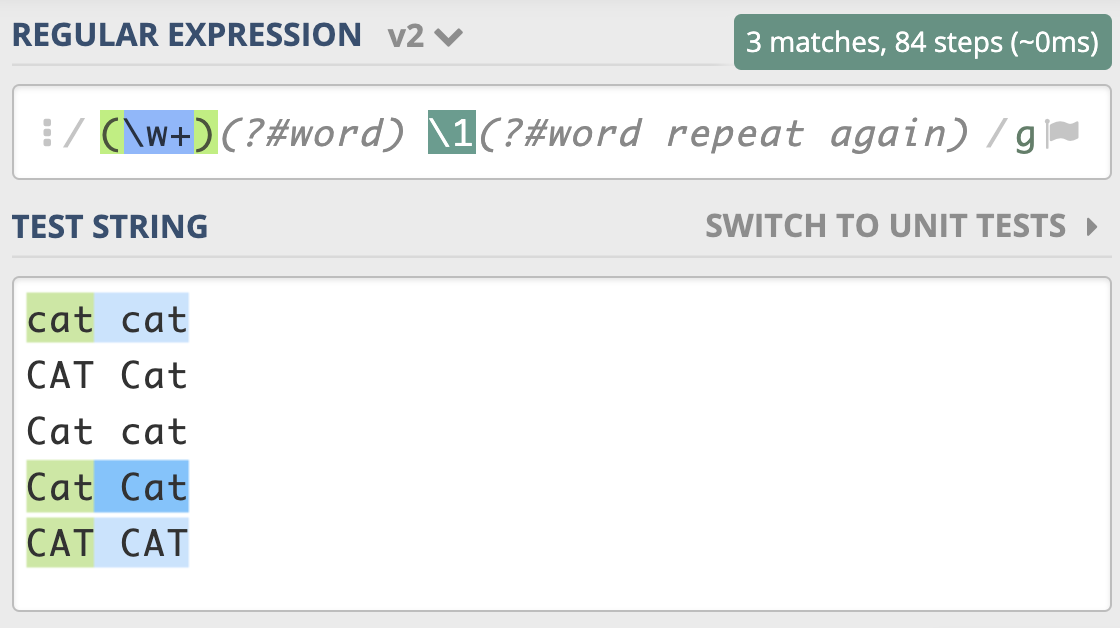
不区分大小写模式(Case-Insensitive)
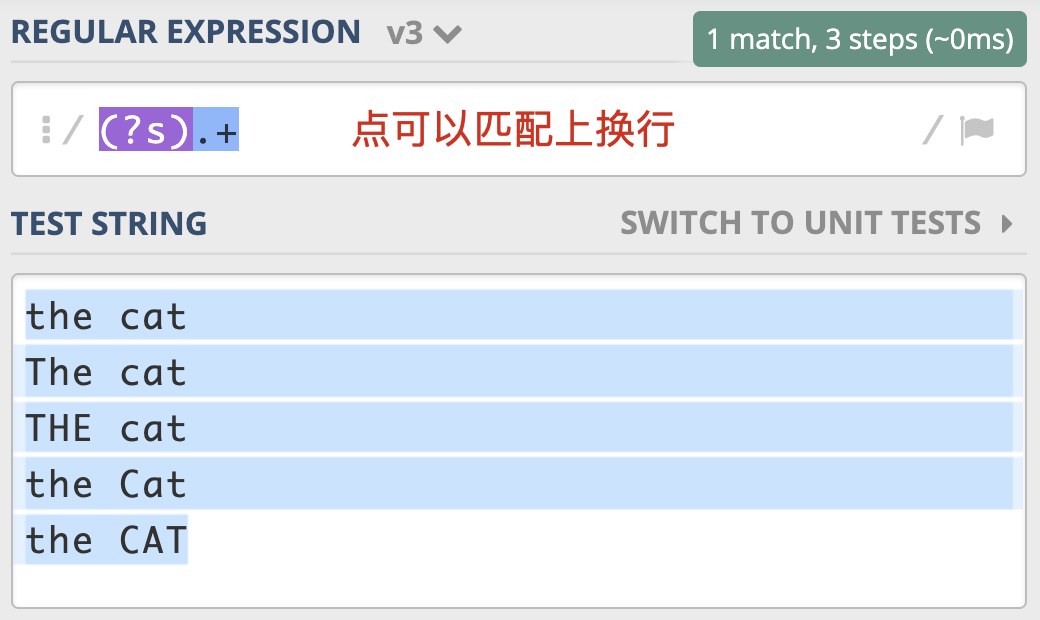
点号通配模式(Dot All)

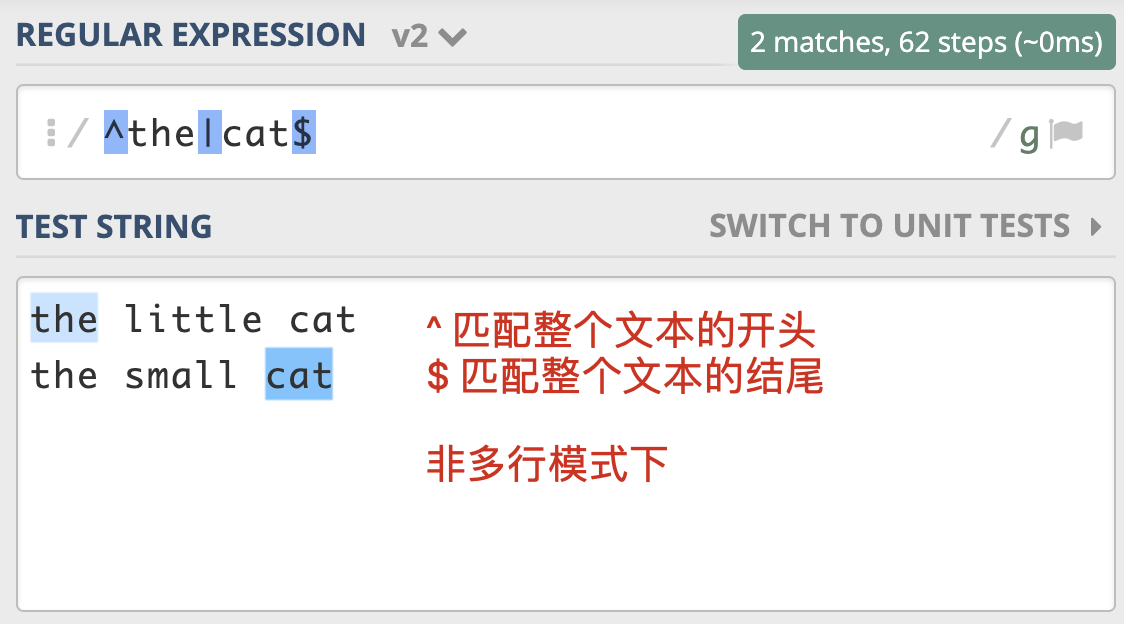
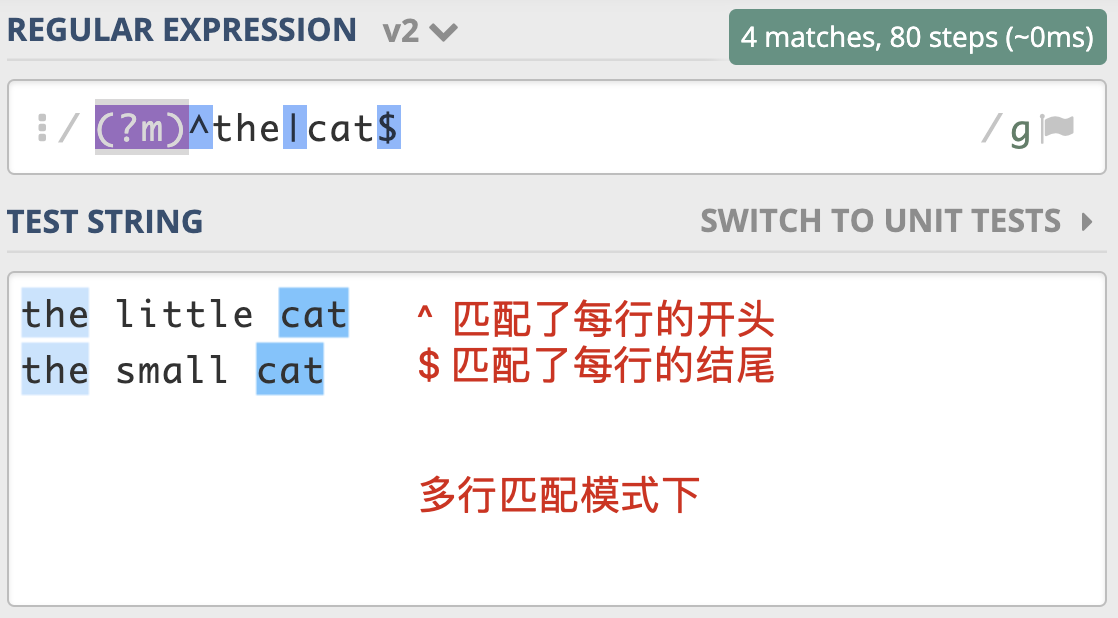
多行匹配模式(Multiline)
注释模式(Comment)
总结

思考题
精选留言(32)
 2020-06-19(?si)<head>(.*)<\/head>展开
2020-06-19(?si)<head>(.*)<\/head>展开作者回复: 对的,重要是点要能匹配换行,head不区分大小写
3 2020-06-23刊误
2020-06-23刊误
JavaScript已经支持单行模式了。支持 gimsuy 共6个flag。
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp/flags
测试代码:(打开任意一个网站,提取head标签内内容)
document.querySelectorAll('html')[0].innerHTML.match(/<head>.*<\/head>/gsi)[0]展开作者回复: 好的,感谢指出,我是在regex101上测试的,发现报错 pattern error,没有细看。
看了您提供的文档,发现 ES2018 新加了这个功能。 1 2020-06-20(?si)<head>.+<\/head>
2020-06-20(?si)<head>.+<\/head>
顺便问一下,怎么把<head>和</head>这2个过滤掉,就是只取他们直接的内容。作者回复: 这个可以后面的在断言里面会讲,下周一就能看到了
1 1 2020-06-20老师能不能多讲解下 实际应用啊 好比我是前端,更主要关注的是js方面的。可是听了几节你将的课以后,还是不知道如何在js中使用。也仅仅只会在你给的一个专门链接里进行测试。可是在js中呢 真的是一脸懵逼。可能是我太菜了[旺柴],也正是因为我菜 所以我才买了这门课程 哈哈哈哈, 麻烦老师回我一下啊展开
2020-06-20老师能不能多讲解下 实际应用啊 好比我是前端,更主要关注的是js方面的。可是听了几节你将的课以后,还是不知道如何在js中使用。也仅仅只会在你给的一个专门链接里进行测试。可是在js中呢 真的是一脸懵逼。可能是我太菜了[旺柴],也正是因为我菜 所以我才买了这门课程 哈哈哈哈, 麻烦老师回我一下啊展开作者回复: 先不要纠结具体的编程语言,要摆脱了字符的限制,深⼊到概念思维的层⾯。掌握了里面的各种概念之后,具体怎么写查一查文档,你肯定能表示出来。
文章中给出的链接,在练习的时候,页面左侧有 FLAVOR,ECMASCript(JavaScript),你可以切换成这个去练习。 2 1 2020-06-19课后练习题:
2020-06-19课后练习题:
(?is)<head>.*<\/head>
在将多行视作单行匹配相关内容,采用单行模式作者回复: 单行模式的意思是 点匹配所有(包括换行)。
不过你说的“将多行视为单行”好像有那么点意思。
正则没问题,可以继续考虑下 head 中有属性的情况。
比如 <head id="my-head">xxxx</head>
你这个正则还能继续工作不? 1 2020-06-19PCRE: (?i)<head>(?s).+<\/head>
2020-06-19PCRE: (?i)<head>(?s).+<\/head>
在 JS 中不支持 ?i 模式的书写形式: /<head>.+<\/head>/igs展开作者回复: 没问题,不过这个题目是要求你提取出里面的内容,不是查找到了就行。另外可以再想一下,如果 head 标签中有属性呢,比如下面这样,又该怎么写呢?
<head id="title">和伟忠一起学习正则表达式</head>
支持的属性可以看这里 https://www.w3school.com.cn/tags/html_ref_standardattributes.asp 1 2020-06-19我的答案:
2020-06-19我的答案:
第一步查找:(?i)<head>((?s).+)<\/head>
第二步替换:\1
为什么是\1 而不是\2 , 我觉得是模式修饰符的括号不算分组。老师,你怎么看?展开作者回复: 没问题,模式修饰符的括号不算分组
1- 2020-06-19老师,正则默认是多行匹配吗?我在您提供的链接上测试是。 ^the|cat$ 我不加(?m)也可以匹配到多行!
作者回复: 看一下后面有没有gm之类的,那个网站可以在后面指定多行模式
1 1  2020-06-24课后习题答案: (?i)<head>([\s\S]*)<\/head>
2020-06-24课后习题答案: (?i)<head>([\s\S]*)<\/head>
在JavaScript下:/<head>([\s\S]*)<\/head>/gi 需要使用 RegExp.$1 取出值展开- 2020-06-23/(<head>)[\s\S]+<\/head>/gi
javascript 语言下使用展开  2020-06-23(?i)^<head>(?s).+</head>$展开
2020-06-23(?i)^<head>(?s).+</head>$展开 2020-06-23使用sublime, 勾选:Case Sensitive. 然后键入: (?s)<head>.*<\/head>
2020-06-23使用sublime, 勾选:Case Sensitive. 然后键入: (?s)<head>.*<\/head>作者回复: 可以的,找到之后剪切出来,再把<head>和</head>部分替换去掉,就相当于提取出来了
 2020-06-23老师,您多行匹配那一部分文章,在编辑时被转译成了katex格式了,还有文章最下面的脑图,还是关于多行匹配的,您文字,匹配,写成了区配。展开
2020-06-23老师,您多行匹配那一部分文章,在编辑时被转译成了katex格式了,还有文章最下面的脑图,还是关于多行匹配的,您文字,匹配,写成了区配。展开作者回复: 感谢指出,我找编辑修改一下
 2020-06-23(?si)<(head).*?>.*?<\/\1>展开
2020-06-23(?si)<(head).*?>.*?<\/\1>展开 2020-06-23老师请问下,
2020-06-23老师请问下,
一个有json语法错误的字符串,如下:
"closeBtn":"close",
},
"ecp_webcore_component_EntitySelect":{
简单想用正则把多余的逗号","替换掉。
在正则验证器里【\",\n{】很容易匹配,然后用【"\"\n{"】替换掉。
但相同的正则在Java运行时就会报错(Pattern.SyntaxException)异常,请问老师,此正则在JAVA应该如何修改?
听说JAVA正则匹配有逻辑错误,各种"\"转义容易出问题,有替代解决方案吗?简单讲就是,在正则匹配器内可以运行的正则表达式如何能在JAVA中直接使用呢?
谢谢。展开- 2020-06-22(?si)<head(\s(profile|accesskey|class|contenteditable|contextmenu|data-[\w\d]|dir|draggable|dropzone|hidden|id|lang|spellcheck|style|tabindex|title|translate)(=".*?")?)*>.*<\/head>
https://regex101.com/r/x1lg4P/6
(?si)<head(.*?)>.*<\/head>
https://regex101.com/r/x1lg4P/5展开  2020-06-21v1: <(?:(?i)head)>(?#case insensitive <head>)((?s).+)(?#match \n)<\/(?:(?i)head)>(?#case insensitive </head>)
2020-06-21v1: <(?:(?i)head)>(?#case insensitive <head>)((?s).+)(?#match \n)<\/(?:(?i)head)>(?#case insensitive </head>)
v1版本比较复杂,从做向右考虑:<(?:(?i)head)> 匹配不区分大小写的 <head> 并不保存分组;((?s).+) 点号通配模式,匹配换行;<\/(?:(?i)head)> 匹配不区分大小写的 <\head> 并不保存分组;
v2: (?is)<head>(?#case insensitive <head>)(.+)(?#match \n)<\/head>(?#case insensitive </head>)
优化后把匹配模式(?i) 和 (?s) 合并提前到表达式最前面(?is)(匹配模式对整个表达式生效),且调整后不会影响结果。展开作者回复: 赞,思路清晰
 2020-06-20js里面我一般用 /(?<=<head.*?>)(.*?)(?=<\/head>)/i展开
2020-06-20js里面我一般用 /(?<=<head.*?>)(.*?)(?=<\/head>)/i展开作者回复: 赞,相当于提已经提前把下一节要讲的断言给用上了
 2020-06-19课后思考: (?is)^<head>\s+(.+)\s+<\/head>
2020-06-19课后思考: (?is)^<head>\s+(.+)\s+<\/head>
参考代码: https://regex101.com/r/Xavyfv/3
不同语言的正则细节上还是有一些区别的, 这个需要多练习.作者回复: 对的,不同的语言有一些小区别,不过思路都是一样的,开始不要纠结在这些细节上,把主要的功能点都掌握了,后面要用到的时候,细节可以理查文档和测试下就好了。
另外可以考虑一下 html 如果是压缩了的,<head>后面没有空白,你这个正则还能工作么?比如这样
https://regex101.com/r/Xavyfv/4 2 2020-06-19(?i)<head>(\D*|\d*)+(?i)<\/head>展开
2020-06-19(?i)<head>(\D*|\d*)+(?i)<\/head>展开作者回复: 说一下几个问题:
1. 开头的 (?i) 已经表示正则是不区分大小写的了,后面没必要再加一次。
2. (\D*|\d*)+ 这种写法是非常不好的,括号里面是0到多次,然后后面又是一到多次,效率比较低。
你可以在这里测试下,你这个正则查找了2052步,https://regex101.com/r/kJfvd6/2/
我猜想你想想表示 [\d\D]+,改写成
(?i)<head>[\d\D]+<\/head>
之后,你会发现只需要查找23步。















