01|什么是分布式数据库?





讲述:王磊
时长17:37大小16.15M
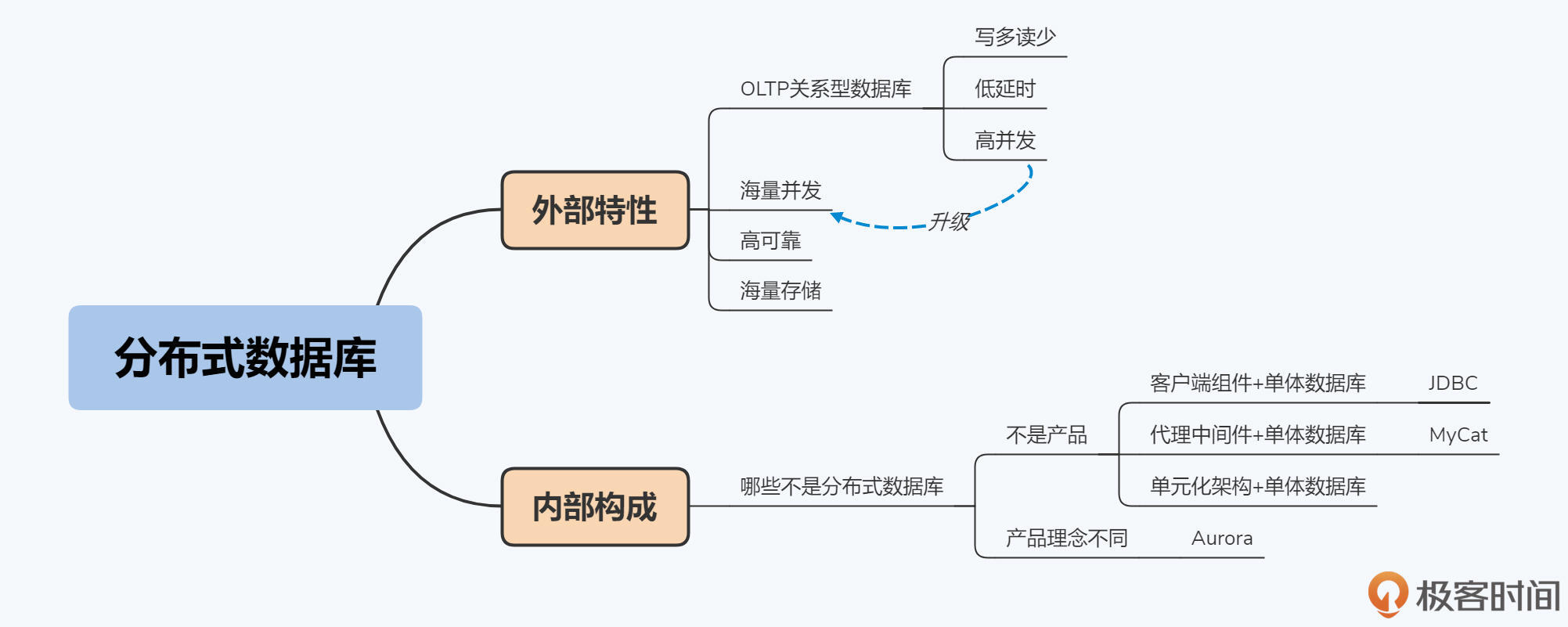
外部视角:外部特性
定义 1.0 OLTP 关系型数据库
定义 2.0 + 海量并发
定义 3.0 + 高可靠
定义 4.0 + 海量存储
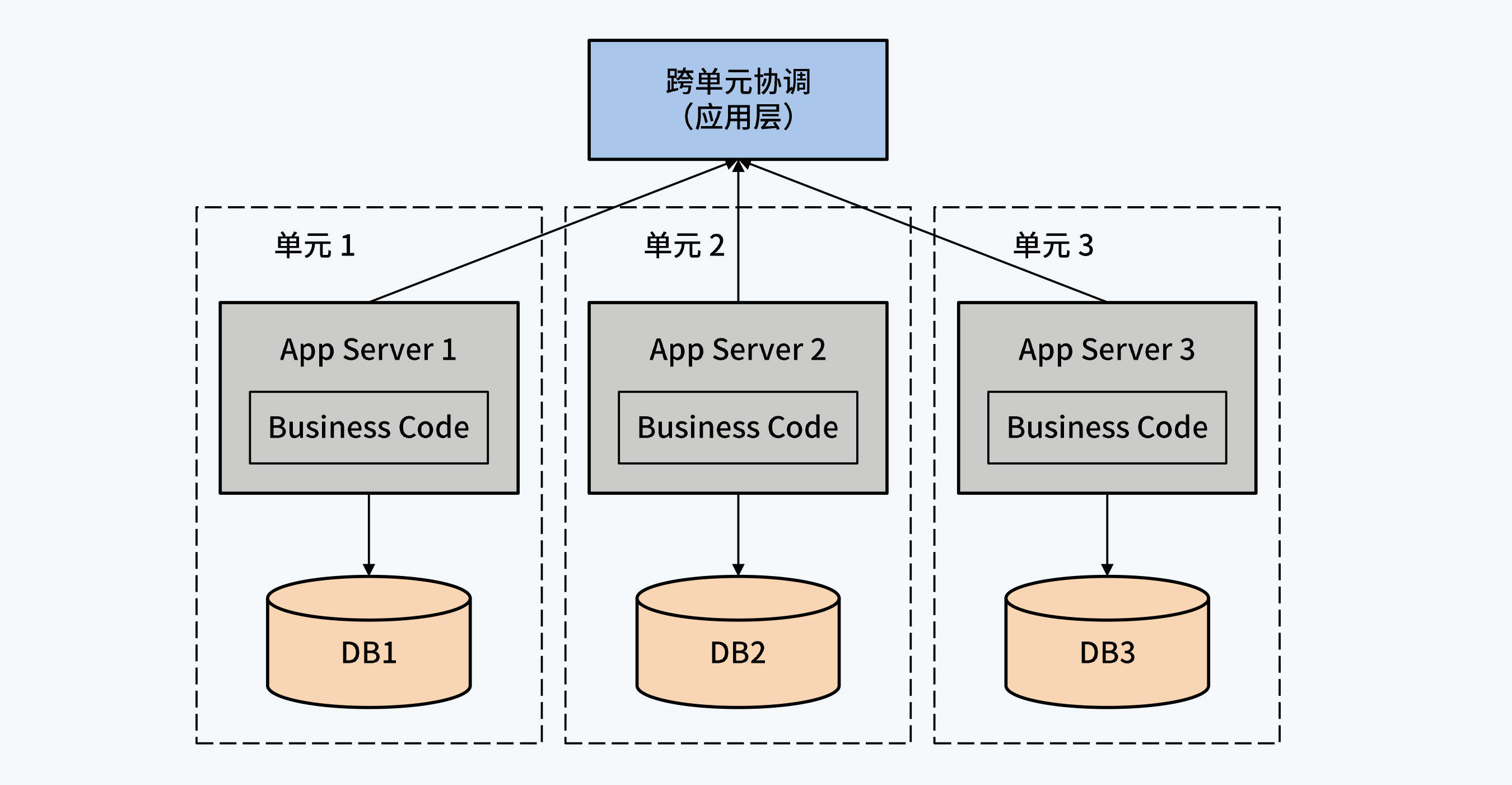
内部视角:内部构成

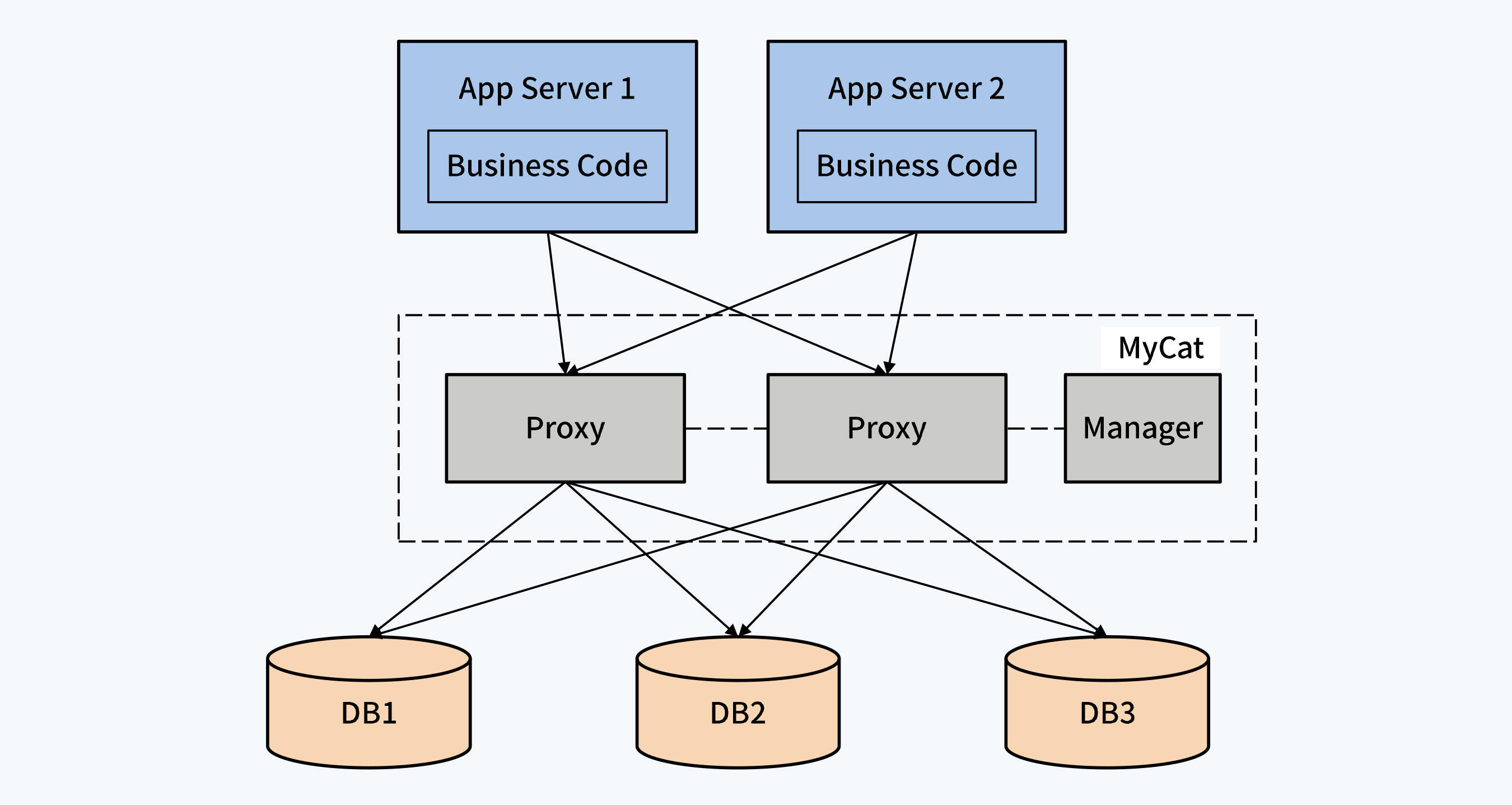
小结
思考题
1716143 665 拼课微信(18)
 2020-08-12我也不太能理解老师说的分布式数据库服务于写多读少的应用,我觉得不管是写多还是读多都可以应用分布式,关键是单体已经承担不了这么多请求了(不论读写),所以其实高并发就够了,不应该吧写多读少加入到分布式数据库的定义里面展开
2020-08-12我也不太能理解老师说的分布式数据库服务于写多读少的应用,我觉得不管是写多还是读多都可以应用分布式,关键是单体已经承担不了这么多请求了(不论读写),所以其实高并发就够了,不应该吧写多读少加入到分布式数据库的定义里面展开作者回复: 你好,之所以强调写多读少,因为写操作的负载只能是单体数据库的主节点上,是无法转移的;而读操作,如果对一致性要求不高可以转移到备节点,甚至在某些条件下还能保证一致性。就是说单体数据库可以通过一主多备解决读负载大的问题,而无需引入分布式数据库
5 2020-08-13aurora也用到一点投票机制,6个副本,半数以上就确认写入成功。也算沾点边。但没有分片,不能多写,肯定不算分布式。展开
2020-08-13aurora也用到一点投票机制,6个副本,半数以上就确认写入成功。也算沾点边。但没有分片,不能多写,肯定不算分布式。展开作者回复: 你好,说的很好。不能多写,这点很关键,适用场景会有很大区别,所以这是一个重要标准。但是,因为Aurora是基于共享存储的,所以说它是分布式也不是没道理。我们定标准的目的,只是为了让学习的思路更清晰。
2 2020-08-11可以更新快点吗?不够看的展开
2020-08-11可以更新快点吗?不够看的展开作者回复: 呵呵,别急哈,一周更三篇。
2 2020-08-10云dbms再分布式基础上更关注于计算存储分离后可独立扩展,甚至动态扩缩容,self-driven搞起来,更好卖了哈哈哈。当然这引发了不少问题,aurora提出了log is database的思想,降低写压力,snowflake通过建立中间分布式换存层,降低网络瓶颈等等。展开
2020-08-10云dbms再分布式基础上更关注于计算存储分离后可独立扩展,甚至动态扩缩容,self-driven搞起来,更好卖了哈哈哈。当然这引发了不少问题,aurora提出了log is database的思想,降低写压力,snowflake通过建立中间分布式换存层,降低网络瓶颈等等。展开作者回复: 总结的很好,log is database是aurora类数据库的设计思想。
2 2020-08-15建议老师画一张分布式数据库的全景图,后续的章节都可以在这张图上添砖加瓦,不然单节学完就是学完了而已,没有成体系,谢谢展开
2020-08-15建议老师画一张分布式数据库的全景图,后续的章节都可以在这张图上添砖加瓦,不然单节学完就是学完了而已,没有成体系,谢谢展开作者回复: 这个建议很好,我和编辑商量下,看看放在哪个部分
1 2020-08-14AWS aurora,阿里polarDB,腾讯CynosDB,架构上是比较类似的,计算存储分离。
2020-08-14AWS aurora,阿里polarDB,腾讯CynosDB,架构上是比较类似的,计算存储分离。
所有计算节点都访问存储节点上的同一份数据,也可以说是分布式架构的。建议老师加个餐讲讲作者回复: 你好,你说的很对,三款产品都是类似的架构,还有华为的Taurus。这个架构的局限是写入不能横向扩展,但对于中小型应用也够了。
1 2020-08-13仅仅是简单看过Aurora的论文,算是有一点点了解。对于老师的问题,首先我觉得Aurora是提出一种新的单体架构以减少网络IO和同步阻塞,逻辑上可以看做一个庞大的单体数据库,用分布式来支持容错和高吞吐量。至于差异方面,我个人其实并没有看出差异。。理由如下:Aurora分片的方式是将数据库的总容量划分为固定大小的数据段,在每一段内存储数据,每一个段是一组机器(六个),个人认为算是支持分片;写多读少、低延时这就是Aurora所重点的做的事情,通过log is database和支持异步来实现;海量存储可以靠堆机器(当然这些机器肯定是有一个控制中心来管理的,论文中没有提);高可靠则是靠每一个数据段把数据冗余到三个可用区的六台机器;而且它同样也是关系型数据库呀。希望老师纠正!展开
2020-08-13仅仅是简单看过Aurora的论文,算是有一点点了解。对于老师的问题,首先我觉得Aurora是提出一种新的单体架构以减少网络IO和同步阻塞,逻辑上可以看做一个庞大的单体数据库,用分布式来支持容错和高吞吐量。至于差异方面,我个人其实并没有看出差异。。理由如下:Aurora分片的方式是将数据库的总容量划分为固定大小的数据段,在每一段内存储数据,每一个段是一组机器(六个),个人认为算是支持分片;写多读少、低延时这就是Aurora所重点的做的事情,通过log is database和支持异步来实现;海量存储可以靠堆机器(当然这些机器肯定是有一个控制中心来管理的,论文中没有提);高可靠则是靠每一个数据段把数据冗余到三个可用区的六台机器;而且它同样也是关系型数据库呀。希望老师纠正!展开作者回复: 你好,首先你把Aurora的特点说得很清楚了。我们这里说有分别,是因为Aurora的特点是Share storage,计算节点垂直扩展,存储节点水平扩展,写入性能收单机资源的影响。
1- 2020-08-11老师好,MyCat现在发展的怎么样,性能上不知道,是否改善了。谢谢。
再请教一个问题,阿里的PolarDB是分布式数据库吧?它采用的是哪种方案呢?靠谱不?谢谢。作者回复: 你好,首先我对MyCat的最新发展了解的不多。个人认为随着分布式数据库的发展,MyCat这类中间件的市场会越来越小。当然,它的使用场景也可能转向对异构数据库的支持,就像Presto那样。
PolarDB和Aurora的架构类似,计算与存储分离,计算节点垂直扩展,存储节点水平扩展。这意味着它的写入能力是有上限的,但是因为简化了日志的存储,和其他一些优化,单节点能力比普通的MySQL好强很多。 1 1  2020-08-11一直没接触过分布式关系型数据库,感觉就是把客户端或中间件的方案直接作为数据库服务端的特性组件,把分库分表做得更为自动化🙃展开
2020-08-11一直没接触过分布式关系型数据库,感觉就是把客户端或中间件的方案直接作为数据库服务端的特性组件,把分库分表做得更为自动化🙃展开作者回复: 分布式数据库和分库分表的最大区别在于,分布式数据库的使用体验是非常接近关系型数据库的,不需要应用进行额外的控制,这就降低了代码的开发难度。而分库分表方案在分布式事务和跨节点查询等方面,通常支持的都不好。
1 2020-08-11希望老师能够讲讲交易场景下,交易代码配合分布式数据库而做出的交易补偿或者数据回放等等
2020-08-11希望老师能够讲讲交易场景下,交易代码配合分布式数据库而做出的交易补偿或者数据回放等等作者回复: 你好,如果需要交易代码配合做出补偿和回放,这很可能意味着它不是分布式数据库。在分布式数据库成熟前,确实有不少应用代码配合单体数据库的方式。这类应用代码也会被抽离出来形成独立的框架,如果你感兴趣,可以研究下阿里的SOFA。
1 2020-08-17从老师的措辞上来看感觉老师水平很高,相对于其它老师学术范更浓一点。
2020-08-17从老师的措辞上来看感觉老师水平很高,相对于其它老师学术范更浓一点。作者回复: 谢谢:)
 2020-08-15可以从实际场景说下Aurora和分布式存储的应用的差别吗
2020-08-15可以从实际场景说下Aurora和分布式存储的应用的差别吗作者回复: 你好,Aurora还是关系型数据库,而分布式存储系统范围较广,比如HBase这样的分布式键值系统。两者在功能上有很大差异。
- 2020-08-13想问问老师,根据文中的定义,BigTable就算是属于特殊的(代理中间件 + 单体数据库(分布式文件系统))吗?它毕竟是靠Chubby来作为一个中间层的,不过数据的获取是直接与文件系统中交互完成的。我一直以为它也算是分布式数据库。展开
作者回复: 你好,BigTable是分布式键值系统,并不属于分布式数据库。因为这里所说的分布式数据库是分布式架构实现的关系型数据库。当然它的底层依赖一个分布式文件系统,所以看上去也是分为两层,但它的职能和数据库差别很大,推荐你看下04讲,关注其中的PGXC风格分布式数据库,有问题可以接着留言,我们继续聊。
 2020-08-12不是很懂为什么说Aurora不是分布式数据库。Aurora通过计算和存储服务分离,使得亚马逊的云存储服务更加高效和易于使用。算是Newsql中比较成功的一个流派了。
2020-08-12不是很懂为什么说Aurora不是分布式数据库。Aurora通过计算和存储服务分离,使得亚马逊的云存储服务更加高效和易于使用。算是Newsql中比较成功的一个流派了。作者回复: 你好,这里没有纳入Aurora,是因为它架构不支持对写入负载的横向扩展。当然,对很多小规模的应用来说也足够了,所以这不影响它取得商业成功。
- 2020-08-11老师您好,基于OLAP使用场景的分布式关系型数据库,都有哪些呀?谢谢,
作者回复: 这个还是挺多的,最典型的是MPP架构数据库,比如Greenplum和华为的GaussDB 200,它们的内核都使用了PostgreSQL。此外,还有Vertica。OLAP不再强调事务的支持,如果弱化了对数据更新的要求,很多大数据生态的产品就都可以纳入进来,比如Clickhouse,Hive on spark,甚至Kylin都可以算是广义的OLAP分布式数据库
1  2020-08-11请问OLTP中“写多读少”中的“多”和“少”是指请求的数量还是请求的大小,或是什么其他的指标呢?都说互联网应用的数据请求通常是“读多写少”,所以才会有一主多从读写分离、全量数据缓存等解决“读”的问题的扩容手段。如果说的是同一个指标的话,是不是意味着分布式数据库不适合互联网应用?展开
2020-08-11请问OLTP中“写多读少”中的“多”和“少”是指请求的数量还是请求的大小,或是什么其他的指标呢?都说互联网应用的数据请求通常是“读多写少”,所以才会有一主多从读写分离、全量数据缓存等解决“读”的问题的扩容手段。如果说的是同一个指标的话,是不是意味着分布式数据库不适合互联网应用?展开作者回复: 你好,首先,OLTP的写多读少,是指请求数量。互联网确实可以通过通过一主多满足“读多写少”的场景,但前提是对读对一致性要求较低。而在金融场景中,很多读操作依然是无法在备库运行的,就是一致性不满足要求。所以,我觉得对互联网也不能一概而论,还是要区分场景。有关一致性的话题,我在02/03会具体讲解,你可以先看看,我们再讨论。
 2020-08-10没主动了解过Aurora,一直把它当成常见的分布式数据库看待的,他很特殊么?
2020-08-10没主动了解过Aurora,一直把它当成常见的分布式数据库看待的,他很特殊么?作者回复:
嗯,AWS的拳头产品,云原生数据库,还是很有特点的。 2020-08-10期待已久展开
2020-08-10期待已久展开作者回复: 谢谢,希望不辜负你的期待