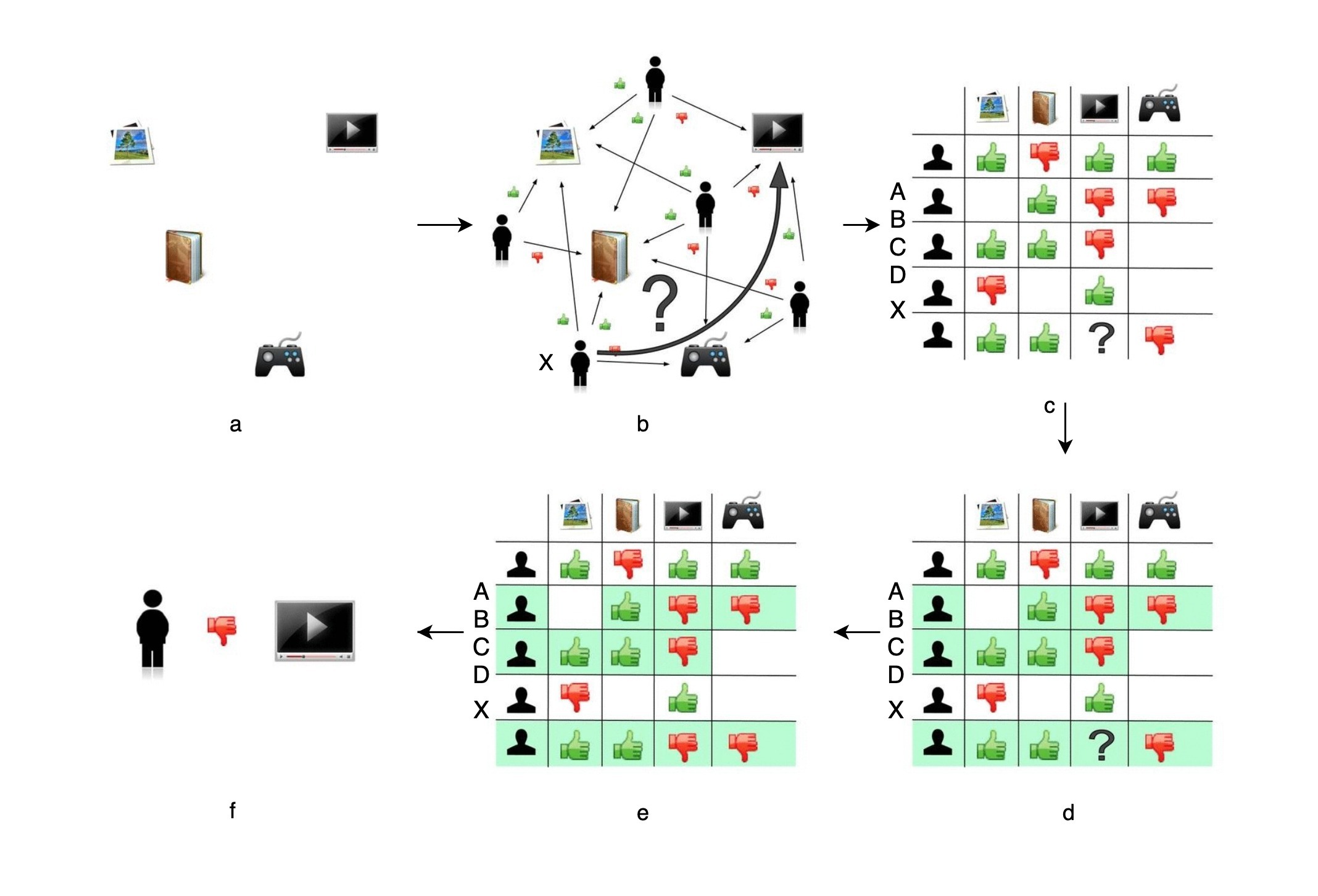
你发现了吗,生成共现矩阵之后,推荐问题就转换成了预测矩阵中问号元素(图 1(d) 所示)的值的问题。由于在“协同”过滤算法中,推荐的原理是让用户考虑与自己兴趣相似用户的意见。因此,我们预测的第一步就是找到与用户 X 兴趣最相似的 n(Top n 用户,这里的 n 是一个超参数)个用户,然后综合相似用户对“电视机”的评价,得出用户 X 对“电视机”评价的预测。
从共现矩阵中我们可以知道,用户 B 和用户 C 由于跟用户 X 的行向量近似,被选为 Top n(这里假设 n 取 2)相似用户,接着在图 1(e) 中我们可以看到,用户 B 和用户 C 对“电视机”的评价均是负面的。因为相似用户对“电视机”的评价是负面的,所以我们可以预测出用户 X 对“电视机”的评价也是负面的。在实际的推荐过程中,推荐系统不会向用户 X 推荐“电视机”这一物品。
到这里,协同过滤的算法流程我们就说完了。也许你也已经发现了,这个过程中有两点不严谨的地方,一是用户相似度到底该怎么定义,二是最后我们预测用户 X 对“电视机”的评价也是负面的,这个负面程度应该有一个分数来衡量,但这个推荐分数该怎么计算呢?
接下来,我们再来看看推荐分数的计算。在获得 Top n 个相似用户之后,利用 Top n 用户生成最终的用户 u 对物品 p 的评分是一个比较直接的过程。这里,我们假设的是“目标用户与其相似用户的喜好是相似的”,根据这个假设,我们可以利用相似用户的已有评价对目标用户的偏好进行预测。最常用的方式是,利用用户相似度和相似用户评价的加权平均值,来获得目标用户的评价预测,公式如下所示。
Ru,p=∑s∈Swu,s∑sϵS(wu,s⋅Rs,p)
其中,权重 wu,s 是用户 u 和用户 s 的相似度,Rs,p 是用户 s 对物品 p 的评分。
在获得用户 u 对不同物品的评价预测后,最终的推荐列表根据评价预测得分进行排序即可得到,到这里,我们就完成了协同过滤的全部推荐过程。
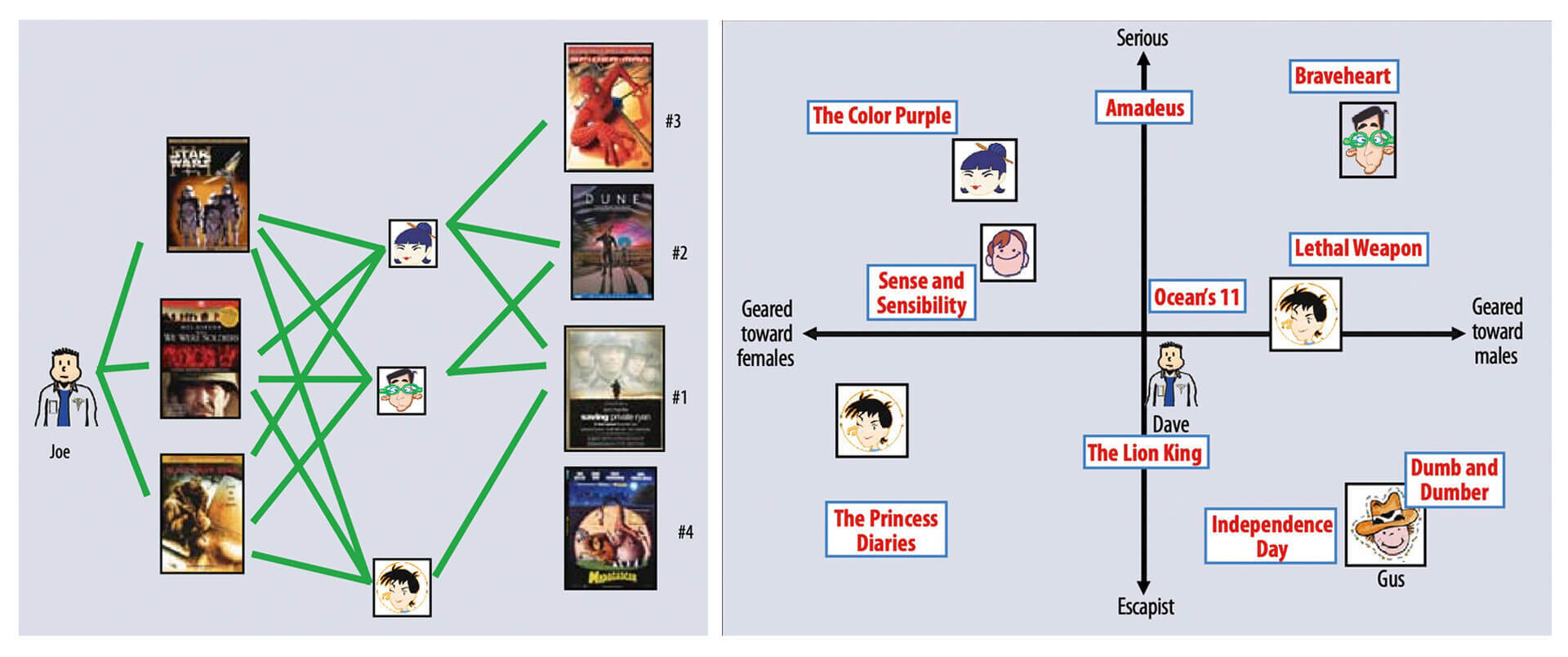
如图 2(a) 所示,协同过滤算法找到用户可能喜欢的视频的方式很直观,就是利用用户的观看历史,找到跟目标用户 Joe 看过同样视频的相似用户,然后找到这些相似用户喜欢看的其他视频,推荐给目标用户 Joe。
矩阵分解算法则是期望为每一个用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间上(如图 2(b) 所示),距离相近的用户和视频表明兴趣特点接近,在推荐过程中,我们就应该把距离相近的视频推荐给目标用户。例如,如果希望为图 2(b) 中的用户 Dave 推荐视频,我们可以找到离 Dave 的用户向量最近的两个视频向量,它们分别是《Ocean’s 11》和《The Lion King》,然后我们可以根据向量距离由近到远的顺序生成 Dave 的推荐列表。
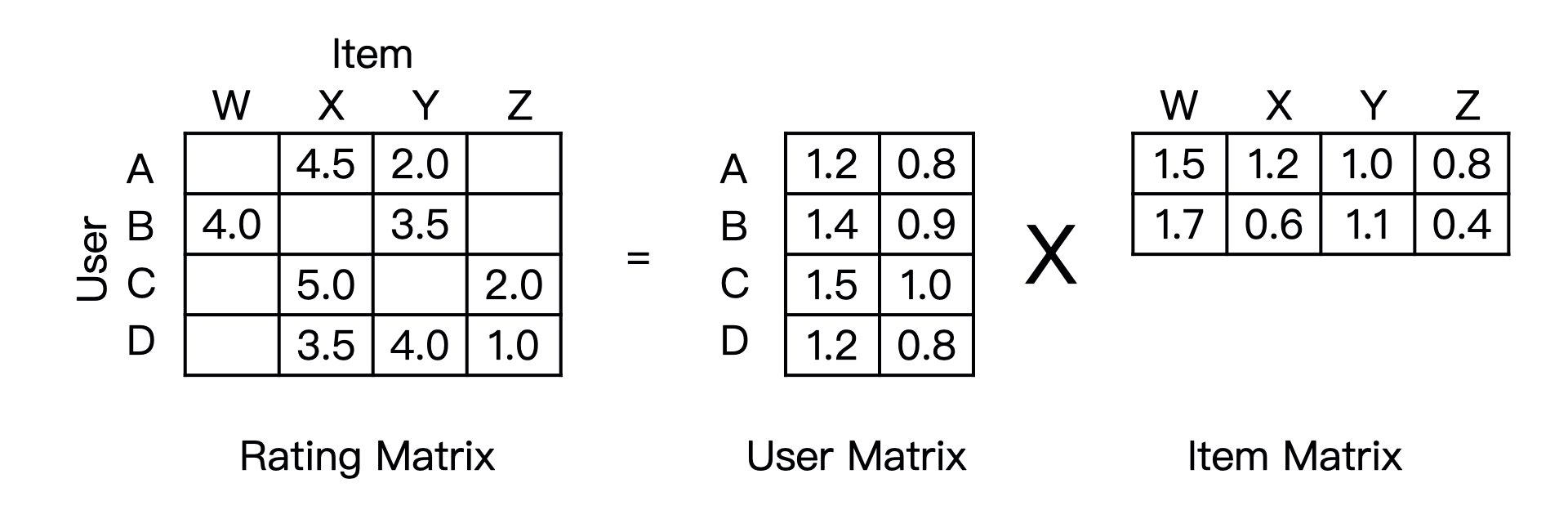
这个目标函数里面,rui 是共现矩阵里面用户 u 对物品 i 的评分,qi 是物品向量,pu 是用户向量。通过目标函数的定义我们可以看到,我们要求的物品向量和用户向量,是希望让物品向量和用户向量之积跟原始的评分之差的平方尽量小。简单来说就是,我们希望用户矩阵和物品矩阵的乘积尽量接近原来的共现矩阵。
基础知识学完,接下来又到了 show me the code 的时间了。这里,我们继续使用 Spark 实现矩阵分解算法。我把关键的代码放在了下面,你可以参考一下。
我们可以看到,因为 Spark MLlib 已经帮我们封装好了模型,所以矩阵分解算法实现起来非常简单,还是通过我们熟悉的三步来完成,分别是定义模型,使用 fit 函数训练模型,提取物品和用户向量。但是有一点我们需要注意,就是在模型中,我们需要在模型中指定训练样本中用户 ID 对应的列 userIdInt 和物品 ID 对应的列 movieIdInt,并且两个 ID 列对应的数据类型需要是 Int 类型的。