21丨朴素贝叶斯分类(下):如何对文档进行分类?





讲述:陈旸(加微信:642945106 发送“赠送”领取赠送精品课程 发数字“2”获取众筹列表。)
时长14:22大小13.17M
我们上一节讲了朴素贝叶斯的工作原理,今天我们来讲下这些原理是如何指导实际业务的。
朴素贝叶斯分类最适合的场景就是文本分类、情感分析和垃圾邮件识别。其中情感分析和垃圾邮件识别都是通过文本来进行判断。从这里你能看出来,这三个场景本质上都是文本分类,这也是朴素贝叶斯最擅长的地方。所以朴素贝叶斯也常用于自然语言处理 NLP 的工具。
今天我带你一起使用朴素贝叶斯做下文档分类的项目,最重要的工具就是 sklearn 这个机器学习神器。
sklearn 机器学习包
sklearn 的全称叫 Scikit-learn,它给我们提供了 3 个朴素贝叶斯分类算法,分别是高斯朴素贝叶斯(GaussianNB)、多项式朴素贝叶斯(MultinomialNB)和伯努利朴素贝叶斯(BernoulliNB)。
这三种算法适合应用在不同的场景下,我们应该根据特征变量的不同选择不同的算法:
高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
伯努利朴素贝叶斯:特征变量是布尔变量,符合 0/1 分布,在文档分类中特征是单词是否出现。
伯努利朴素贝叶斯是以文件为粒度,如果该单词在某文件中出现了即为 1,否则为 0。而多项式朴素贝叶斯是以单词为粒度,会计算在某个文件中的具体次数。而高斯朴素贝叶斯适合处理特征变量是连续变量,且符合正态分布(高斯分布)的情况。比如身高、体重这种自然界的现象就比较适合用高斯朴素贝叶斯来处理。而文本分类是使用多项式朴素贝叶斯或者伯努利朴素贝叶斯。
什么是 TF-IDF 值呢?
我在多项式朴素贝叶斯中提到了“词的 TF-IDF 值”,如何理解这个概念呢?
TF-IDF 是一个统计方法,用来评估某个词语对于一个文件集或文档库中的其中一份文件的重要程度。
TF-IDF 实际上是两个词组 Term Frequency 和 Inverse Document Frequency 的总称,两者缩写为 TF 和 IDF,分别代表了词频和逆向文档频率。
词频 TF计算了一个单词在文档中出现的次数,它认为一个单词的重要性和它在文档中出现的次数呈正比。
逆向文档频率 IDF,是指一个单词在文档中的区分度。它认为一个单词出现在的文档数越少,就越能通过这个单词把该文档和其他文档区分开。IDF 越大就代表该单词的区分度越大。
所以 TF-IDF 实际上是词频 TF 和逆向文档频率 IDF 的乘积。这样我们倾向于找到 TF 和 IDF 取值都高的单词作为区分,即这个单词在一个文档中出现的次数多,同时又很少出现在其他文档中。这样的单词适合用于分类。
TF-IDF 如何计算
首先我们看下词频 TF 和逆向文档概率 IDF 的公式。


为什么 IDF 的分母中,单词出现的文档数要加 1 呢?因为有些单词可能不会存在文档中,为了避免分母为 0,统一给单词出现的文档数都加 1。
TF-IDF=TF*IDF。
你可以看到,TF-IDF 值就是 TF 与 IDF 的乘积, 这样可以更准确地对文档进行分类。比如“我”这样的高频单词,虽然 TF 词频高,但是 IDF 值很低,整体的 TF-IDF 也不高。
我在这里举个例子。假设一个文件夹里一共有 10 篇文档,其中一篇文档有 1000 个单词,“this”这个单词出现 20 次,“bayes”出现了 5 次。“this”在所有文档中均出现过,而“bayes”只在 2 篇文档中出现过。我们来计算一下这两个词语的 TF-IDF 值。
针对“this”,计算 TF-IDF 值:
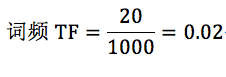
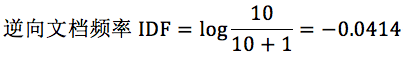
所以 TF-IDF=0.02*(-0.0414)=-8.28e-4。
针对“bayes”,计算 TF-IDF 值:
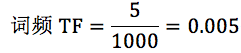
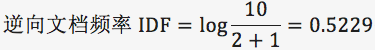
TF-IDF=0.005*0.5229=2.61e-3。
很明显“bayes”的 TF-IDF 值要大于“this”的 TF-IDF 值。这就说明用“bayes”这个单词做区分比单词“this”要好。
如何求 TF-IDF
在 sklearn 中我们直接使用 TfidfVectorizer 类,它可以帮我们计算单词 TF-IDF 向量的值。在这个类中,取 sklearn 计算的对数 log 时,底数是 e,不是 10。
下面我来讲下如何创建 TfidfVectorizer 类。
TfidfVectorizer 类的创建:
创建 TfidfVectorizer 的方法是:
我们在创建的时候,有两个构造参数,可以自定义停用词 stop_words 和规律规则 token_pattern。需要注意的是传递的数据结构,停用词 stop_words 是一个列表 List 类型,而过滤规则 token_pattern 是正则表达式。
什么是停用词?停用词就是在分类中没有用的词,这些词一般词频 TF 高,但是 IDF 很低,起不到分类的作用。为了节省空间和计算时间,我们把这些词作为停用词 stop words,告诉机器这些词不需要帮我计算。

当我们创建好 TF-IDF 向量类型时,可以用 fit_transform 帮我们计算,返回给我们文本矩阵,该矩阵表示了每个单词在每个文档中的 TF-IDF 值。

在我们进行 fit_transform 拟合模型后,我们可以得到更多的 TF-IDF 向量属性,比如,我们可以得到词汇的对应关系(字典类型)和向量的 IDF 值,当然也可以获取设置的停用词 stop_words。
举个例子,假设我们有 4 个文档:
文档 1:this is the bayes document;
文档 2:this is the second second document;
文档 3:and the third one;
文档 4:is this the document。
现在想要计算文档里都有哪些单词,这些单词在不同文档中的 TF-IDF 值是多少呢?
首先我们创建 TfidfVectorizer 类:
然后我们创建 4 个文档的列表 documents,并让创建好的 tfidf_vec 对 documents 进行拟合,得到 TF-IDF 矩阵:
输出文档中所有不重复的词:
运行结果
输出每个单词对应的 id 值:
运行结果
输出每个单词在每个文档中的 TF-IDF 值,向量里的顺序是按照词语的 id 顺序来的:
运行结果:
如何对文档进行分类
如果我们要对文档进行分类,有两个重要的阶段:
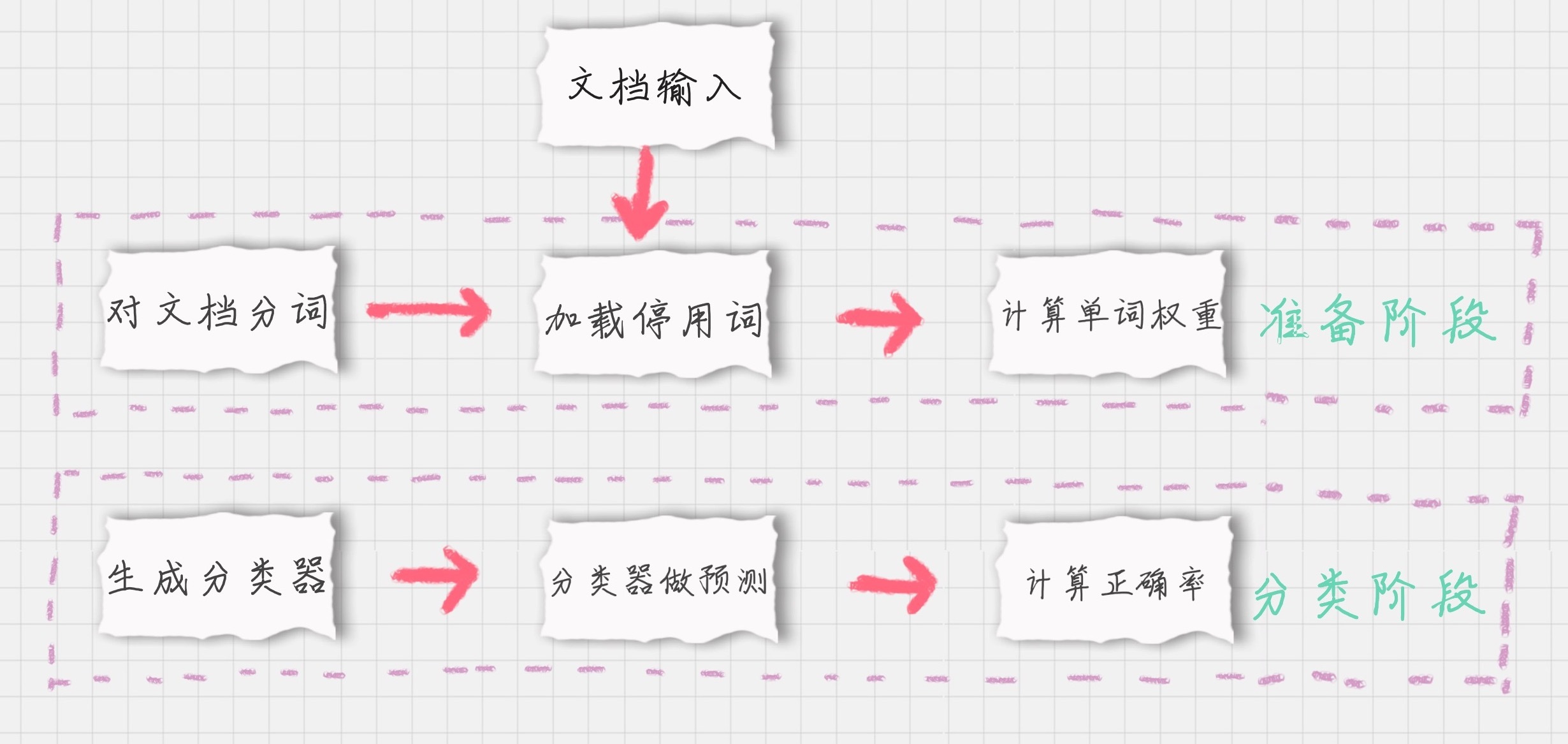
-
基于分词的数据准备,包括分词、单词权重计算、去掉停用词;
-
应用朴素贝叶斯分类进行分类,首先通过训练集得到朴素贝叶斯分类器,然后将分类器应用于测试集,并与实际结果做对比,最终得到测试集的分类准确率。
下面,我分别对这些模块进行介绍。
模块 1:对文档进行分词
在准备阶段里,最重要的就是分词。那么如果给文档进行分词呢?英文文档和中文文档所使用的分词工具不同。
在英文文档中,最常用的是 NTLK 包。NTLK 包中包含了英文的停用词 stop words、分词和标注方法。
在中文文档中,最常用的是 jieba 包。jieba 包中包含了中文的停用词 stop words 和分词方法。
模块 2:加载停用词表
我们需要自己读取停用词表文件,从网上可以找到中文常用的停用词保存在 stop_words.txt,然后利用 Python 的文件读取函数读取文件,保存在 stop_words 数组中。
模块 3:计算单词的权重
这里我们用到 sklearn 里的 TfidfVectorizer 类,上面我们介绍过它使用的方法。
直接创建 TfidfVectorizer 类,然后使用 fit_transform 方法进行拟合,得到 TF-IDF 特征空间 features,你可以理解为选出来的分词就是特征。我们计算这些特征在文档上的特征向量,得到特征空间 features。
这里 max_df 参数用来描述单词在文档中的最高出现率。假设 max_df=0.5,代表一个单词在 50% 的文档中都出现过了,那么它只携带了非常少的信息,因此就不作为分词统计。
一般很少设置 min_df,因为 min_df 通常都会很小。
模块 4:生成朴素贝叶斯分类器
我们将特征训练集的特征空间 train_features,以及训练集对应的分类 train_labels 传递给贝叶斯分类器 clf,它会自动生成一个符合特征空间和对应分类的分类器。
这里我们采用的是多项式贝叶斯分类器,其中 alpha 为平滑参数。为什么要使用平滑呢?因为如果一个单词在训练样本中没有出现,这个单词的概率就会被计算为 0。但训练集样本只是整体的抽样情况,我们不能因为一个事件没有观察到,就认为整个事件的概率为 0。为了解决这个问题,我们需要做平滑处理。
当 alpha=1 时,使用的是 Laplace 平滑。Laplace 平滑就是采用加 1 的方式,来统计没有出现过的单词的概率。这样当训练样本很大的时候,加 1 得到的概率变化可以忽略不计,也同时避免了零概率的问题。
当 0<alpha<1 时,使用的是 Lidstone 平滑。对于 Lidstone 平滑来说,alpha 越小,迭代次数越多,精度越高。我们可以设置 alpha 为 0.001。
模块 5:使用生成的分类器做预测
首先我们需要得到测试集的特征矩阵。
方法是用训练集的分词创建一个 TfidfVectorizer 类,使用同样的 stop_words 和 max_df,然后用这个 TfidfVectorizer 类对测试集的内容进行 fit_transform 拟合,得到测试集的特征矩阵 test_features。
然后我们用训练好的分类器对新数据做预测。
方法是使用 predict 函数,传入测试集的特征矩阵 test_features,得到分类结果 predicted_labels。predict 函数做的工作就是求解所有后验概率并找出最大的那个。
模块 6:计算准确率
计算准确率实际上是对分类模型的评估。我们可以调用 sklearn 中的 metrics 包,在 metrics 中提供了 accuracy_score 函数,方便我们对实际结果和预测的结果做对比,给出模型的准确率。
使用方法如下:
数据挖掘神器 sklearn
从数据挖掘的流程来看,一般包括了获取数据、数据清洗、模型训练、模型评估和模型部署这几个过程。
sklearn 中包含了大量的数据挖掘算法,比如三种朴素贝叶斯算法,我们只需要了解不同算法的适用条件,以及创建时所需的参数,就可以用模型帮我们进行训练。在模型评估中,sklearn 提供了 metrics 包,帮我们对预测结果与实际结果进行评估。
在文档分类的项目中,我们针对文档的特点,给出了基于分词的准备流程。一般来说 NTLK 包适用于英文文档,而 jieba 适用于中文文档。我们可以根据文档选择不同的包,对文档提取分词。这些分词就是贝叶斯分类中最重要的特征属性。基于这些分词,我们得到分词的权重,即特征矩阵。
通过特征矩阵与分类结果,我们就可以创建出朴素贝叶斯分类器,然后用分类器进行预测,最后预测结果与实际结果做对比即可以得到分类器在测试集上的准确率。
练习题
我已经讲了中文文档分类中的 6 个关键的模块,最后,我给你留一道对中文文档分类的练习题吧。
我将中文文档数据集上传到了 GitHub 上,点击这里下载。
数据说明:
- 文档共有 4 种类型:女性、体育、文学、校园;
- 训练集放到 train 文件夹里,测试集放到 test 文件夹里,停用词放到 stop 文件夹里。

请使用朴素贝叶斯分类对训练集进行训练,并对测试集进行验证,并给出测试集的准确率。
最后你不妨思考一下,假设我们要判断一个人的性别,是通过身高、体重、鞋码、外貌等属性进行判断的,如果我们用朴素贝叶斯做分类,适合使用哪种朴素贝叶斯分类器?停用词的作用又是什么?
欢迎你在评论区进行留言,与我分享你的答案。也欢迎点击“请朋友读”,把这篇文章分享给你的朋友或者同事。

1716143665 拼课微信(34)
 szm2019-01-30 24需要完整代码,不然看不明白!展开
szm2019-01-30 24需要完整代码,不然看不明白!展开 北方2019-02-14 16#!/usr/bin/env python
北方2019-02-14 16#!/usr/bin/env python
# -*- coding:utf8 -*-
# __author__ = '北方姆Q'
# __datetime__ = 2019/2/14 14:04
import os
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
LABEL_MAP = {'体育': 0, '女性': 1, '文学': 2, '校园': 3}
# 加载停用词
with open('./text classification/stop/stopword.txt', 'rb') as f:
STOP_WORDS = [line.strip() for line in f.readlines()]
def load_data(base_path):
"""
:param base_path: 基础路径
:return: 分词列表,标签列表
"""
documents = []
labels = []
for root, dirs, files in os.walk(base_path): # 循环所有文件并进行分词打标
for file in files:
label = root.split('\\')[-1] # 因为windows上路径符号自动转成\了,所以要转义下
labels.append(label)
filename = os.path.join(root, file)
with open(filename, 'rb') as f: # 因为字符集问题因此直接用二进制方式读取
content = f.read()
word_list = list(jieba.cut(content))
words = [wl for wl in word_list]
documents.append(' '.join(words))
return documents, labels
def train_fun(td, tl, testd, testl):
"""
构造模型并计算测试集准确率,字数限制变量名简写
:param td: 训练集数据
:param tl: 训练集标签
:param testd: 测试集数据
:param testl: 测试集标签
:return: 测试集准确率
"""
# 计算矩阵
tt = TfidfVectorizer(stop_words=STOP_WORDS, max_df=0.5)
tf = tt.fit_transform(td)
# 训练模型
clf = MultinomialNB(alpha=0.001).fit(tf, tl)
# 模型预测
test_tf = TfidfVectorizer(stop_words=STOP_WORDS, max_df=0.5, vocabulary=tt.vocabulary_)
test_features = test_tf.fit_transform(testd)
predicted_labels = clf.predict(test_features)
# 获取结果
x = metrics.accuracy_score(testl, predicted_labels)
return x
# text classification与代码同目录下
train_documents, train_labels = load_data('./text classification/train')
test_documents, test_labels = load_data('./text classification/test')
x = train_fun(train_documents, train_labels, test_documents, test_labels)
print(x)展开 Python2019-01-30 15老师,能不能在答疑的时候给这道题的完整代码看看展开
Python2019-01-30 15老师,能不能在答疑的时候给这道题的完整代码看看展开 姜戈2019-01-30 9看过很多朴素贝叶斯原理和分类的讲解文章,很少能像前辈这样既有理论,又有实战的讲解,让大家既了解了理论知识,又有相应实际的操作经验可学,真的好棒,这个专栏,必须多多点赞,为老师加油!!!展开
姜戈2019-01-30 9看过很多朴素贝叶斯原理和分类的讲解文章,很少能像前辈这样既有理论,又有实战的讲解,让大家既了解了理论知识,又有相应实际的操作经验可学,真的好棒,这个专栏,必须多多点赞,为老师加油!!!展开- 池边的树2019-02-12 4https://github.com/yourSprite/AnalysisExcercise/tree/master/%E6%9C%B4%E7%B4%A0%E8%B4%9D%E5%8F%B6%E6%96%AF%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB展开
- 听妈妈的话2019-03-21 3# 由于评论不支持markdown,代码放在https://pastebin.com/kqjXgy0c
train_contents=[]
train_labels=[]
test_contents=[]
test_labels=[]
# 导入文件
import os
import io
start=os.listdir(r'text classification/train')
for item in start:
test_path='text classification/test/'+item+'/'
train_path='text classification/train/'+item+'/'
for file in os.listdir(test_path):
with open(test_path+file,encoding="GBK") as f:
test_contents.append(f.readline())
#print(test_contents)
test_labels.append(item)
for file in os.listdir(train_path):
with open(train_path+file,encoding='gb18030', errors='ignore') as f:
train_contents.append(f.readline())
train_labels.append(item)
print(len(train_contents),len(test_contents))
# 导入stop word
import jieba
from sklearn import metrics
from sklearn.naive_bayes import MultinomialNB
stop_words = [line.strip() for line in io.open('text classification/stop/stopword.txt').readlines()]
# 分词方式使用jieba,计算单词的权重
tf = TfidfVectorizer(tokenizer=jieba.cut,stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(train_contents)
print(train_features.shape)
模块 4:生成朴素贝叶斯分类器
# 多项式贝叶斯分类器
clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)
模块 5:使用生成的分类器做预测
test_tf = TfidfVectorizer(tokenizer=jieba.cut,stop_words=stop_words, max_df=0.5, vocabulary=tf.vocabulary_)
test_features=test_tf.fit_transform(test_contents)
print(test_features.shape)
predicted_labels=clf.predict(test_features)
print(metrics.accuracy_score(test_labels, predicted_labels))
# 最终结果0.925展开 - 上官2019-01-31 3print('不重复的词:', tfidf_vec.get_feature_names())
运行结果: 不重复的词: ['and', 'bayes', 'document', 'is', 'one', 'second', 'the', 'third', 'this']
这明明就是打印所有词啊,有重复的啊  Jack2019-02-14 2#!/usr/bin/env python
Jack2019-02-14 2#!/usr/bin/env python
# coding: utf-8
import os
import jieba
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
# 1. 加载数据
# 加载停用词表
l_stopWords = set()
with open('./text_classification/text_classification/stop/stopword.txt', 'r') as l_f:
for l_line in l_f:
l_stopWords.add(l_line.strip())
l_labelMap = {'体育': 0, '女性': 1, '文学': 2, '校园': 3}
# 加载训练数据和测试数据
def LoadData(filepath):
l_documents = []
l_labels = []
for root, dirs, files in os.walk(filepath):
for l_file in files:
l_label = root.split('/')[-1]
l_filename = os.path.join(root, l_file)
with open(l_filename, 'r') as l_f:
l_content = l_f.read()
l_wordlist = list(jieba.cut(l_content))
l_words = [item for item in l_wordlist if item not in l_stopWords]
l_documents.append(' '.join(l_words))
l_labels.append(l_labelMap[l_label])
return l_documents, l_labels
l_trainDocuments, l_trainLabels = LoadData('./text_classification/text_classification/train')
l_testDocuments, l_testLabels = LoadData('./text_classification/text_classification/test')
# # 2. 计算权重矩阵
l_tfidfVec = TfidfVectorizer(max_df=0.5)
l_tfidfMatrix = l_tfidfVec.fit_transform(l_trainDocuments)
# for item in l_tfidfVec.get_feature_names():
# print item
# print l_tfidfVec.get_feature_names()
# print l_tfidfVec.vocabulary_
print l_tfidfMatrix.toarray().shape
# # 3. 朴素贝叶斯模型
# ## 3.1 模型训练
l_clf = MultinomialNB(alpha=0.001)
l_clf.fit(l_tfidfMatrix, l_trainLabels)
# ## 3.2 模型预测
l_testTfidf = TfidfVectorizer(max_df=0.5, vocabulary=l_tfidfVec.vocabulary_)
l_testFeature = l_testTfidf.fit_transform(l_testDocuments)
l_hats = l_clf.predict(l_testFeature)
# ## 3.3 模型评估
from sklearn.metrics import accuracy_score
print accuracy_score(l_hats, l_testLabels)展开 叮当猫2019-03-16 1#-coding=utf-8
叮当猫2019-03-16 1#-coding=utf-8
import os
import pandas as pd
import jieba
from sklearn import metrics
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
def load_data(path):
l_labels = []
l_documents = []
#os.walk返回三元组(root, dirs, files)
#root指的是当前正在遍历的这个文件夹本身的地址
#dirs是一个list,内容是该文件夹中所有的目录的名字
#files是一个list,内容是该文件夹中所有的文件,不包含子目录
for root, dirs, files in os.walk(path):
print root, dirs, files
for l_file in files:
l_label = root.split('/')[-1]
l_filepath = os.path.join(root, l_file)
with open(l_filepath, 'r') as l_f:
l_content = l_f.read()
l_words = ' '.join(list(jieba.cut(l_content)) )
l_labels.append(l_label)
l_documents.append(l_words)
return l_documents, l_labels
#第一步:对文档进行分词
train_documents, train_labels = load_data('./text classification/train/')
test_documents, test_labels = load_data('./text classification/test/')
#第二步:加载停用词
STOP_WORDS = [line.strip() for line in open('./text classification/stop/stopword.txt' ,'r').readlines()]
#第三步:计算单词的权重
tf = TfidfVectorizer(stop_words=STOP_WORDS, max_df=0.5)
train_features = tf.fit_transform(train_documents)
#第四步:生成朴素贝叶斯分类器
clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)
#第五步:使用生成的分类器做预测
test_tf = TfidfVectorizer(stop_words=STOP_WORDS, max_df=0.5, vocabulary=tf.vocabulary_)
test_features = test_tf.fit_transform(test_documents)
predict_labels = clf.predict(test_features)
#第六步:计算准确率
print metrics.accuracy_score(test_labels, predict_labels)展开- wzhan3662019-02-06 1建议 大家先做英文版本,因为中文的unicode encode和decode不是很好弄,不利于中间步骤的可视化。如果对代码有疑惑,可以试试这个pipeline, sklearn 的。 不过,这个没有用NTLK。展开
 王小王2019-02-02 1能不能讲解下本堂课的练习题?展开
王小王2019-02-02 1能不能讲解下本堂课的练习题?展开 Rickie2019-01-30 1老师,token_pattern里的正则中(?u)是什么意思呀?展开
Rickie2019-01-30 1老师,token_pattern里的正则中(?u)是什么意思呀?展开 滢2019-04-17最后面的代码太乱,很多都不知道从哪里来的,无法顺着看下去~~~展开
滢2019-04-17最后面的代码太乱,很多都不知道从哪里来的,无法顺着看下去~~~展开 王彬成2019-04-05# -*- coding:utf8 -*-
王彬成2019-04-05# -*- coding:utf8 -*-
# 系统:mac
# 1. 加载数据
# 加载停用词表
l_stopWords = [line.strip() for line in open('./text_classification-master/text classification/stop/stopword.txt', 'r', encoding='utf-8').readlines()]
l_labelMap = {'体育': 0, '女性': 1, '文学': 2, '校园': 3}
# 加载训练数据和测试数据
def LoadData(filepath):
l_documents = []
l_labels = []
for root, dirs, files in os.walk(filepath):
for l_file in files:
if l_file=='.DS_Store':
continue
l_label = root.split('/')[-1]
l_filename = os.path.join(root, l_file)
with open(l_filename, 'r',encoding='gbk') as l_f:
try:
l_content = l_f.read()
except Exception as err:
print(err)
print(l_filename)
continue
generator = jieba.cut(l_content)
words = ' '.join(generator)
l_wordlist=words.split(' ')
l_words = [item for item in l_wordlist if item not in l_stopWords]
l_documents.append(' '.join(l_words))
l_labels.append(l_labelMap[l_label])
return l_documents, l_labels
l_trainDocuments, l_trainLabels = LoadData('./text_classification-master/text classification/train')
l_testDocuments, l_testLabels = LoadData('./text_classification-master/text classification/test')
# # 2. 计算权重矩阵
l_tfidfVec = TfidfVectorizer(max_df=0.5)
l_tfidfMatrix = l_tfidfVec.fit_transform(l_trainDocuments)
print (l_tfidfMatrix.toarray().shape)
# # 3. 朴素贝叶斯模型
# ## 3.1 模型训练
l_clf = MultinomialNB(alpha=0.001)
l_clf.fit(l_tfidfMatrix, l_trainLabels)
# ## 3.2 模型预测
l_testTfidf = TfidfVectorizer(max_df=0.5, vocabulary=l_tfidfVec.vocabulary_)
l_testFeature = l_testTfidf.fit_transform(l_testDocuments)
l_hats = l_clf.predict(l_testFeature)
# ## 3.3 模型评估
from sklearn.metrics import accuracy_score
print (accuracy_score(l_hats, l_testLabels))展开- 听妈妈的话2019-03-21我的代码位于:https://pastebin.com/kqjXgy0c ,最终结果0.925
注意: 中文分词,TfidfVectorizer增加一个参数:tokenizer=jieba.cut,(来自github jieba issue: https://github.com/fxsjy/jieba/issues/332)
train_contents=[]
train_labels=[]
test_contents=[]
test_labels=[]
# 导入文件
import os
import io
start=os.listdir(r'text classification/train')
for item in start:
test_path='text classification/test/'+item+'/'
train_path='text classification/train/'+item+'/'
for file in os.listdir(test_path):
with open(test_path+file,encoding="GBK") as f:
test_contents.append(f.readline())
#print(test_contents)
test_labels.append(item)
for file in os.listdir(train_path):
with open(train_path+file,encoding='gb18030', errors='ignore') as f:
train_contents.append(f.readline())
train_labels.append(item)
print(len(train_contents),len(test_contents))
# 导入stop word
import jieba
from sklearn import metrics
from sklearn.naive_bayes import MultinomialNB
stop_words = [line.strip() for line in io.open('text classification/stop/stopword.txt').readlines()]
# 分词方式使用jieba,计算单词的权重
tf = TfidfVectorizer(tokenizer=jieba.cut,stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(train_contents)
print(train_features.shape)
模块 4:生成朴素贝叶斯分类器
# 多项式贝叶斯分类器
clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)
模块 5:使用生成的分类器做预测
test_tf = TfidfVectorizer(tokenizer=jieba.cut,stop_words=stop_words, max_df=0.5, vocabulary=tf.vocabulary_)
test_features=test_tf.fit_transform(test_contents)
print(test_features.shape)
predicted_labels=clf.predict(test_features)
print(metrics.accuracy_score(test_labels, predicted_labels))
# 最终结果0.925展开  以圭2019-03-18老师,请问一下代码中的train_labels需要去重吗?word_list 和 train_contents的关系是什么?word_list需要去重吗?features 和 train_features 的关系是什么?展开
以圭2019-03-18老师,请问一下代码中的train_labels需要去重吗?word_list 和 train_contents的关系是什么?word_list需要去重吗?features 和 train_features 的关系是什么?展开 小莫2019-03-10老师,完整代码能贴出来吗?展开
小莫2019-03-10老师,完整代码能贴出来吗?展开 周飞2019-03-10#!/usr/bin/env python
周飞2019-03-10#!/usr/bin/env python
# -*- coding:utf8 -*-
import os
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
def load_data(base_path):
documents = []
labels = []
for root, dirs, files in os.walk(base_path): # 循环所有文件并进行分词打标
for file in files:
label = root.split('\\')[-1] # 因为windows上路径符号自动转成\了,所以要转义下
labels.append(label)
filename = os.path.join(root, file)
with open(filename, 'rb') as f: # 因为字符集问题因此直接用二进制方式读取
content = f.read()
word_list = list(jieba.cut(content))
words = [wl for wl in word_list]
documents.append(' '.join(words))
return documents, labels
train_contents, train_labels = load_data('./text_classification/train')
test_contents, test_labels = load_data('./text_classification/test')
stop_words = []
import io
stop_words = [line.strip().encode('utf-8') for line in io.open('./text_classification/stop/stopword.txt').readlines()]
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(train_contents)
# 多项式贝叶斯分类器
clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)
test_tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5, vocabulary=tf.vocabulary_)
test_features=test_tf.fit_transform(test_contents)
predicted_labels=clf.predict(test_features)
print (metrics.accuracy_score(test_labels, predicted_labels))
不知道为什么 结果是0。展开- 三硝基甲苯2019-03-10import jieba
import glob
import io
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
classification = ["campus", "female", "sports", "literature"]
train_files_list = []
test_files_list = []
trainpathprefix = "./text_classification/train/"
testpathprefix = "./text_classification/test/"
pathsuffix = "/*.txt"
train_label = []
test_label = []
train_docments = []
test_docments = []
stopword_path = './text_classification/stop/stopword.txt'
for i in classification:
trainpathstr = trainpathprefix + i + pathsuffix
testpathstr = testpathprefix + i + pathsuffix
trainpathlist = glob.glob(trainpathstr)
lentrainlist = len(trainpathlist)
train_label += [i for j in range(lentrainlist)]
testpathlist = glob.glob(testpathstr)
lentestlist = len(testpathlist)
test_label += [i for j in range(lentestlist)]
train_files_list += trainpathlist
test_files_list += testpathlist
for i in train_files_list:
f = open(i, 'r')
content = f.readlines()[0]
contentlist = list(jieba.cut(content))
contentwithspace = " ".join(contentlist)
train_docments.append(contentwithspace)
for i in test_files_list:
f = open(i, 'r')
content = f.readlines()[0]
contentlist = list(jieba.cut(content))
contentwithspace = ' '.join(contentlist)
test_docments.append(contentwithspace)
stopwords = [l.strip('\n') for l in io.open(stopword_path, encoding='utf-8').readlines()]
train_tf = TfidfVectorizer(stop_words=stopwords, max_df=0.5)
train_features = train_tf.fit_transform(train_docments)
clf = MultinomialNB(alpha=0.001).fit(train_features, train_label)
test_tf = TfidfVectorizer(stop_words=stopwords, max_df=0.5, vocabulary=train_tf.vocabulary_)
test_features = test_tf.fit_transform(test_docments)
predicted_labels = clf.predict(test_features)
print(metrics.accuracy_score(test_label, predicted_labels))
运动的300.txt文件因为字符问题手动修改了一下。展开 - YoungDou2019-03-08ValueError: dimension mismatch 提示,还有编码问题,无法解决展开