02 | MapReduce后谁主沉浮:怎样设计下一代数据处理技术?





讲述:巴莫
时长12:23大小11.34M
你好,我是蔡元楠。
在上一讲中,我们介绍了 2014 年之前的大数据历史,也就是 MapReduce 作为数据处理的默认标准的时代。重点探讨了 MapReduce 面对日益复杂的业务逻辑时表现出的不足之处,那就是:1. 维护成本高;2. 时间性能不足。
同时,我们也提到了 2008 年诞生在 Google 西雅图研发中心的 FlumeJava,它成为了 Google 内部的数据处理新宠。
那么,为什么是它扛起了继任 MapReduce 的大旗呢?
要知道,在包括 Google 在内的硅谷一线大厂,对于内部技术选择是非常严格的,一个能成为默认方案的技术至少满足以下条件:
-
经受了众多产品线,超大规模数据量例如亿级用户的考验;
-
自发地被众多内部开发者采用,简单易用而受开发者欢迎;
-
能通过内部领域内专家的评审;
-
比上一代技术仅仅提高 10% 是不够的,必须要有显著的比如 70% 的提高,才能够说服整个公司付出技术迁移的高昂代价。就看看从 Python 2.7 到 Python 3 的升级花了多少年了,就知道在大厂迁移技术是异常艰难的。
今天这一讲,我不展开讲任何具体技术。
我想先和你一起设想一下,假如我和你站在 2008 年的春夏之交,在已经清楚了 MapReduce 的现有问题的情况下,我们会怎么设计下一代大规模数据处理技术,带领下一个十年的技术革新呢?
我们需要一种技术抽象让多步骤数据处理变得易于维护
上一讲中我提到过,维护协调多个步骤的数据处理在业务中非常常见。
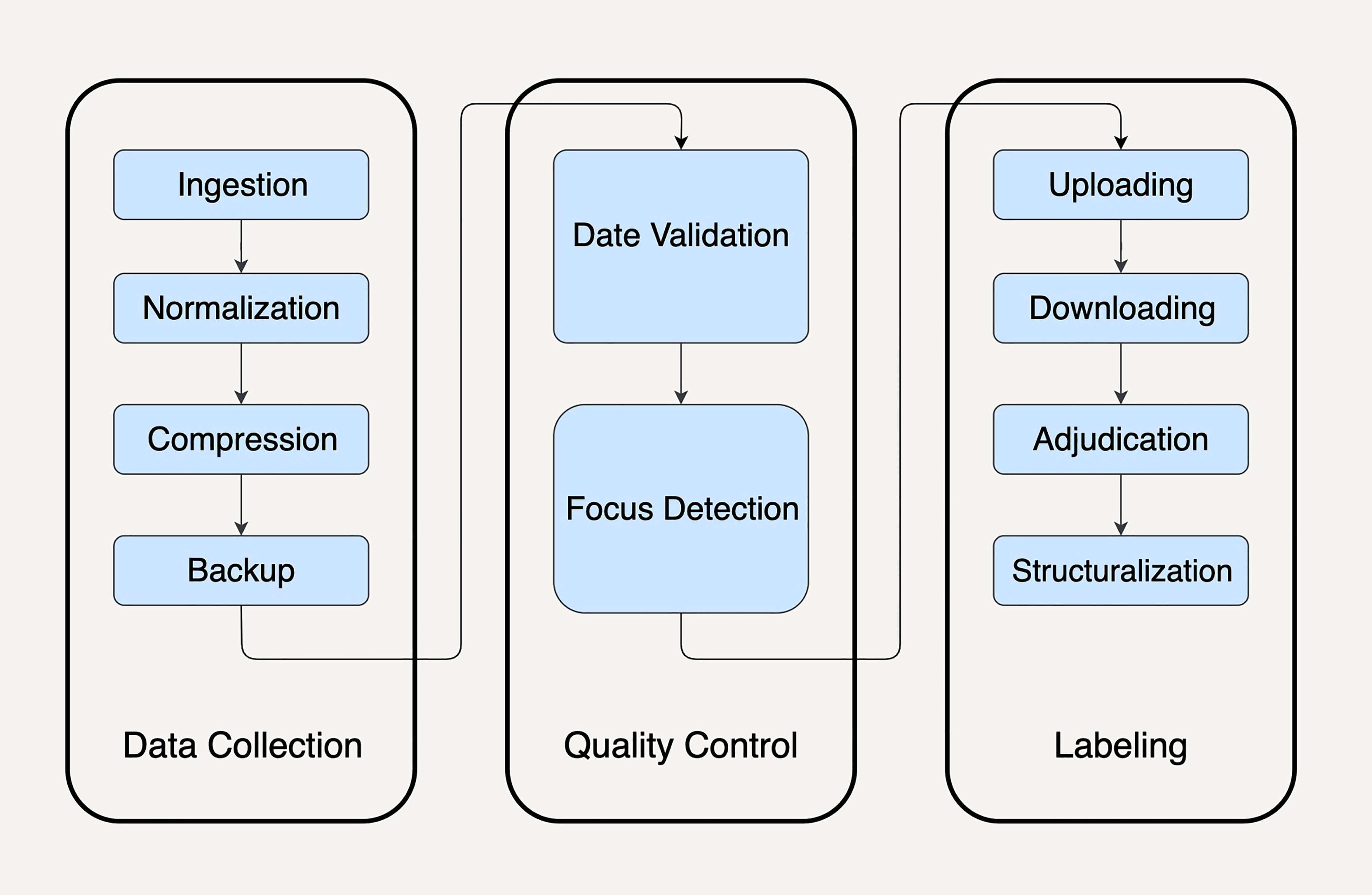
像图片中这样复杂的数据处理在 MapReduce 中维护起来令人苦不堪言。
为了解决这个问题,作为架构师的我们或许可以用有向无环图(DAG)来抽象表达。因为有向图能为多个步骤的数据处理依赖关系,建立很好的模型。如果你对图论比较陌生的话,可能现在不知道我在说什么,你可以看下面一个例子,或者复习一下极客时间的《数据结构与算法之美》。
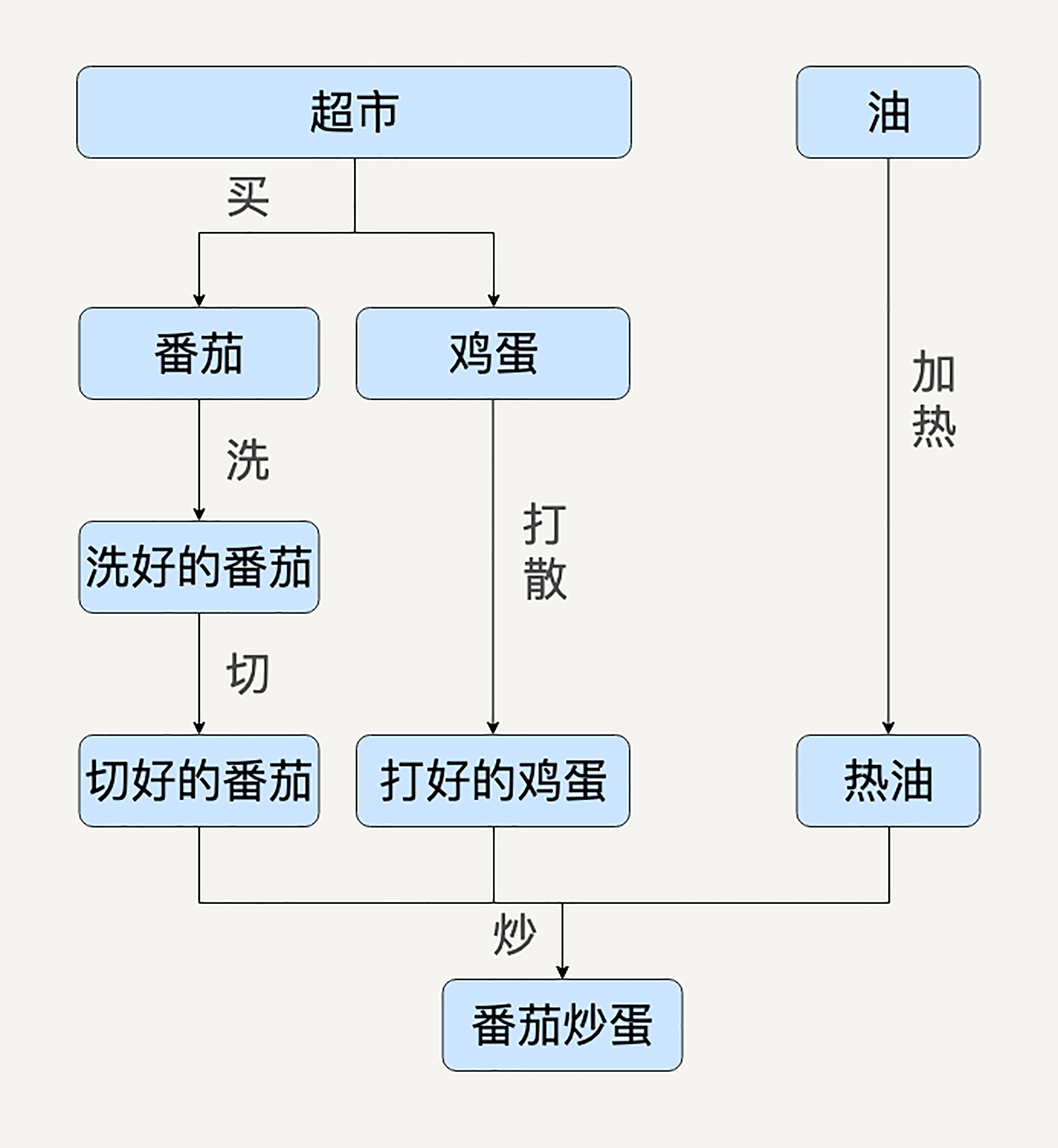
西红柿炒鸡蛋这样一个菜,就是一个有向无环图概念的典型案例。
比如看这里面番茄的处理,最后一步“炒”的步骤依赖于切好的番茄、打好的蛋、热好的油。而切好的番茄又依赖于洗好的番茄等等。如果用 MapReduce 来实现的话,在这个图里面,每一个箭头都会是一个独立的 Map 或 Reduce。
为了协调那么多 Map 和 Reduce,你又难以避免会去做很多检查,比如:番茄是不是洗好了,鸡蛋是不是打好了。
最后这个系统就不堪重负了。
但是,如果我们用有向图建模,图中的每一个节点都可以被抽象地表达成一种通用的数据集,每一条边都被表达成一种通用的数据变换。如此,你就可以用数据集和数据变换描述极为宏大复杂的数据处理流程,而不会迷失在依赖关系中无法自拔。
我们不想要复杂的配置,需要能自动进行性能优化
上一讲中提到,MapReduce 的另一个问题是,配置太复杂了。以至于错误的配置最终导致数据处理任务效率低下。
这种问题怎么解决呢?很自然的思路就是,如果人容易犯错,就让人少做一点,让机器多做一点呗。
我们已经知道了,得益于上一步中我们已经用有向图对数据处理进行了高度抽象。这可能就能成为我们进行自动性能优化的一个突破口。
回到刚才的番茄炒鸡蛋例子,哪些情况我们需要自动优化呢?
设想一下,如果我们的数据处理食谱上又增加了番茄牛腩的需求,用户的数据处理有向图就变成了这个样子了。
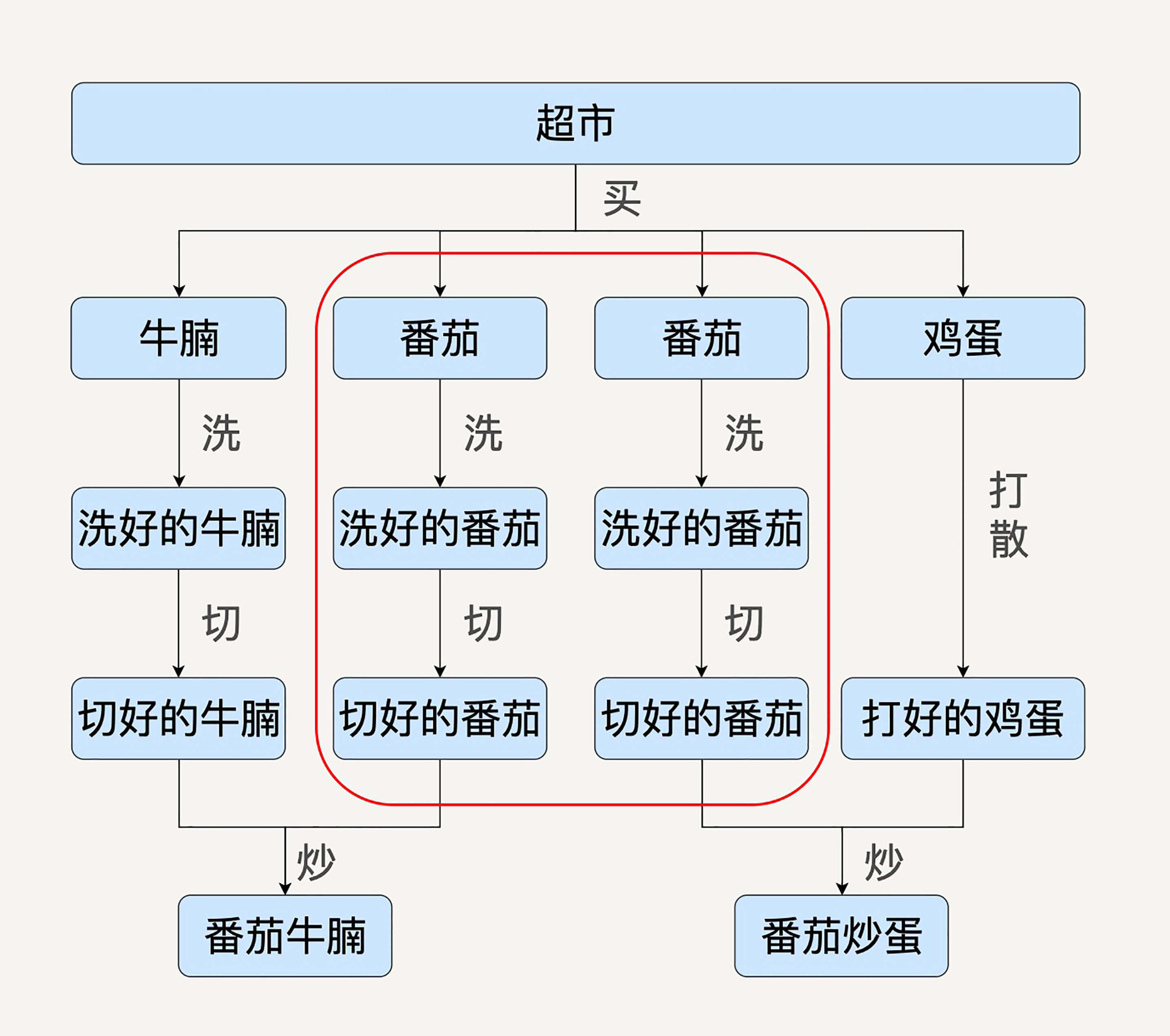
理想的情况下,我们的计算引擎要能够自动发现红框中的两条数据处理流程是重复的。它要能把两条数据处理过程进行合并。这样的话,番茄就不会被重复准备了。
同样的,如果需求突然不再需要番茄炒蛋了,只需要番茄牛腩,在数据流水线的预处理部分也应该把一些无关的数据操作优化掉,比如整个鸡蛋的处理过程就不应该在运行时出现。
另一种自动的优化是计算资源的自动弹性分配。
比如,还是在番茄炒蛋这样一个数据处理流水线中,如果你的规模上来了,今天需要生产 1 吨的番茄炒蛋,明天需要生产 10 吨的番茄炒蛋。你发现有时候是处理 1000 个番茄,有时候又是 10000 个番茄。如果手动地去做资源配置的话,你再也配置不过来了。
我们的优化系统也要有可以处理这种问题的弹性的劳动力分配机制。它要能自动分配,比如 100 台机器处理 1000 个番茄,如果是 10000 个番茄那就分配 1000 台机器,但是只给热油 1 台机器可能就够了。
这里的比喻其实是很粗糙也不精准的。我想用这样两个例子表达的观点是,在数据处理开始前,我们需要有一个自动优化的步骤和能力,而不是按部就班地就把每一个步骤就直接扔给机器去执行了。
我们要能把数据处理的描述语言,与背后的运行引擎解耦合开来
前面两个设计思路提到了很重要的一个设计就是有向图。
用有向图进行数据处理描述的话,实际上数据处理描述语言部分完全可以和后面的运算引擎分离了。有向图可以作为数据处理描述语言和运算引擎的前后端分离协议。
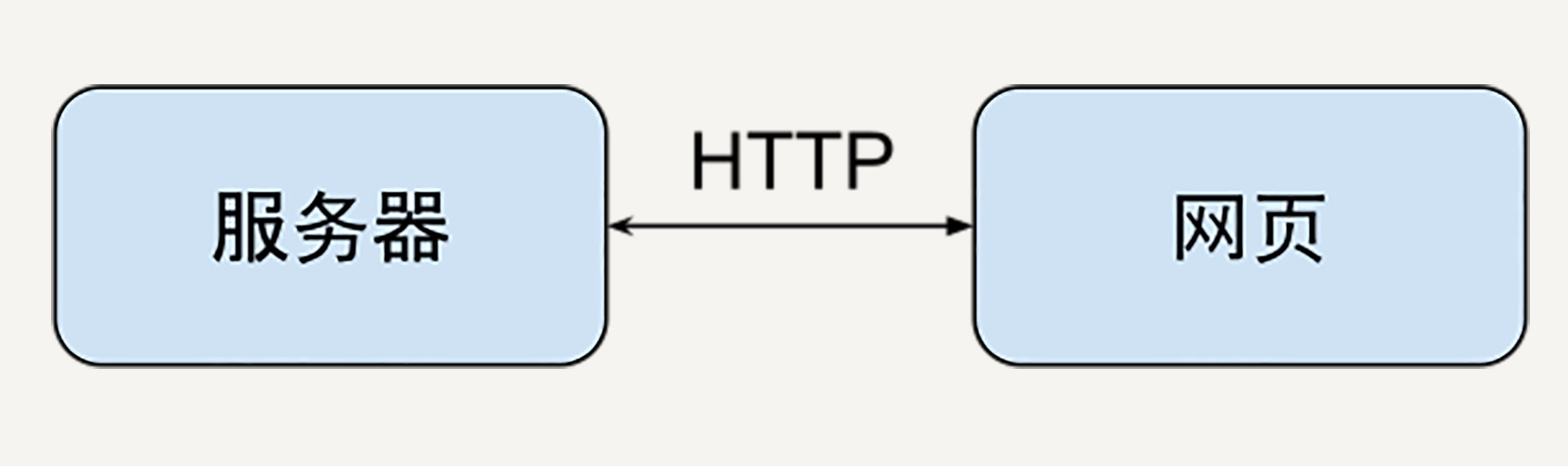
举两个你熟悉的例子可能能更好理解我这里所说的前后端分离(client-server design)是什么意思:
比如一个网站的架构中,服务器和网页通过 HTTP 协议通信。
比如在 TensorFlow 的设计中,客户端可以用任何语言(比如 Python 或者 C++)描述计算图,运行时引擎(runtime) 理论上却可以在任何地方具体运行,比如在本地,在 CPU,或者在 TPU。
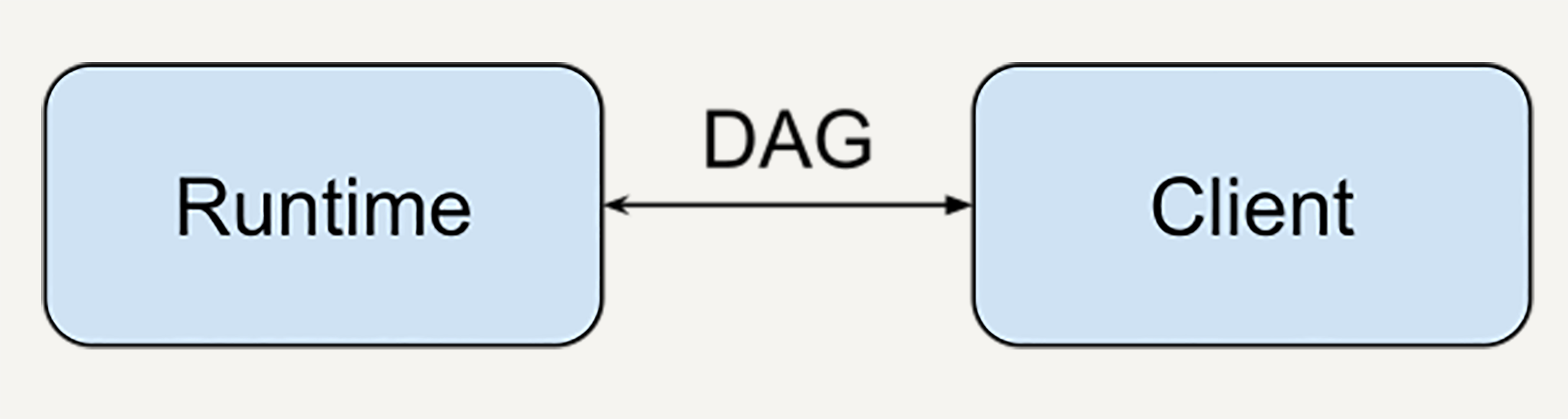
那么我们设计的数据处理技术也是一样的,除了有向图表达需要数据处理描述语言和运算引擎协商一致,其他的实现都是灵活可拓展的。
比如,我的数据描述可以用 Python 描述,由业务团队使用;计算引擎用 C++ 实现,可以由数据底层架构团队维护并且高度优化;或者我的数据描述在本地写,计算引擎在云端执行。
我们要统一批处理和流处理的编程模型
关于什么是批处理和流处理概念会在后面的章节展开。这里先简单解释下,批处理处理的是有界离散的数据,比如处理一个文本文件;流处理处理的是无界连续的数据,比如每时每刻的支付宝交易数据。
MapReduce 的一个局限是它为了批处理而设计的,应对流处理的时候不再那么得心应手。即使后面的 Apache Storm、Apache Flink 也都有类似的问题,比如 Flink 里的批处理数据结构用 DataSet,但是流处理用 DataStream。
但是真正的业务系统,批处理和流处理是常常混合共生,或者频繁变换的。
比如,你有 A、B 两个数据提供商。其中数据提供商 A 与你签订的是一次性的数据协议,一次性给你一大波数据,你可以用批处理。而数据提供商 B 是实时地给你数据,你又得用流处理。更可怕的事情发生了,本来是批处理的数据提供商 A,突然把协议修改了,现在他们实时更新数据。这时候你要是用 Flink 就得爆炸了。业务需求天天改,还让不让人活了?!
因此,我们设计的数据处理框架里,就得有更高层级的数据抽象。
不论是批处理还是流处理的,都用统一的数据结构表示。编程的 API 也需要统一。这样不论业务需求什么样,开发者只需要学习一套 API。即使业务需求改变,开发者也不需要频繁修改代码。
我们要在架构层面提供异常处理和数据监控的能力
真正写过大规模数据处理系统的人都深有感触:在一个复杂的数据处理系统中,难的不是开发系统,而是异常处理。
事实正是如此。一个 Google 内部调研表明,在大规模的数据处理系统中,90% 的时间都花在了异常处理中。常常发生的问题的是,比如在之前的番茄炒鸡蛋处理问题中,你看着系统 log,明明买了 1000 个鸡蛋,炒出来的菜却看起来只有 999 个鸡蛋,你仰天长叹,少了一个蛋到底去哪里了!
这一点和普通的软件开发不同。比如,服务器开发中,偶尔一个 RPC 请求丢了就丢了,重试一下,重启一下能过就行了。可如果在数据处理系统中,数据就是钱啊,不能随便丢。比如我们的鸡蛋,都是真金白银买回来的。是超市买回来数错了?是打蛋时候打碎了?还是被谁偷吃了?你总得给老板一个合理的交代。
我们要设计一套基本的数据监控能力,对于数据处理的每一步提供自动的监控平台,比如一个监控网站。
在番茄炒蛋系统中,要能够自动的记录下来,超市买回来是多少个蛋,打蛋前是多少个蛋,打完蛋是多少个蛋,放进锅里前是多少个蛋等等。也需要把每一步的相关信息进行存储,比如是谁去买的蛋,哪些人打蛋。这样出错后可以帮助用户快速找到可能出错的环节。
小结
通过上面的分析,我们可以总结一下。如果是我们站在 2008 年春夏之交来设计下一代大规模数据处理框架,一个基本的模型会是图中这样子的:
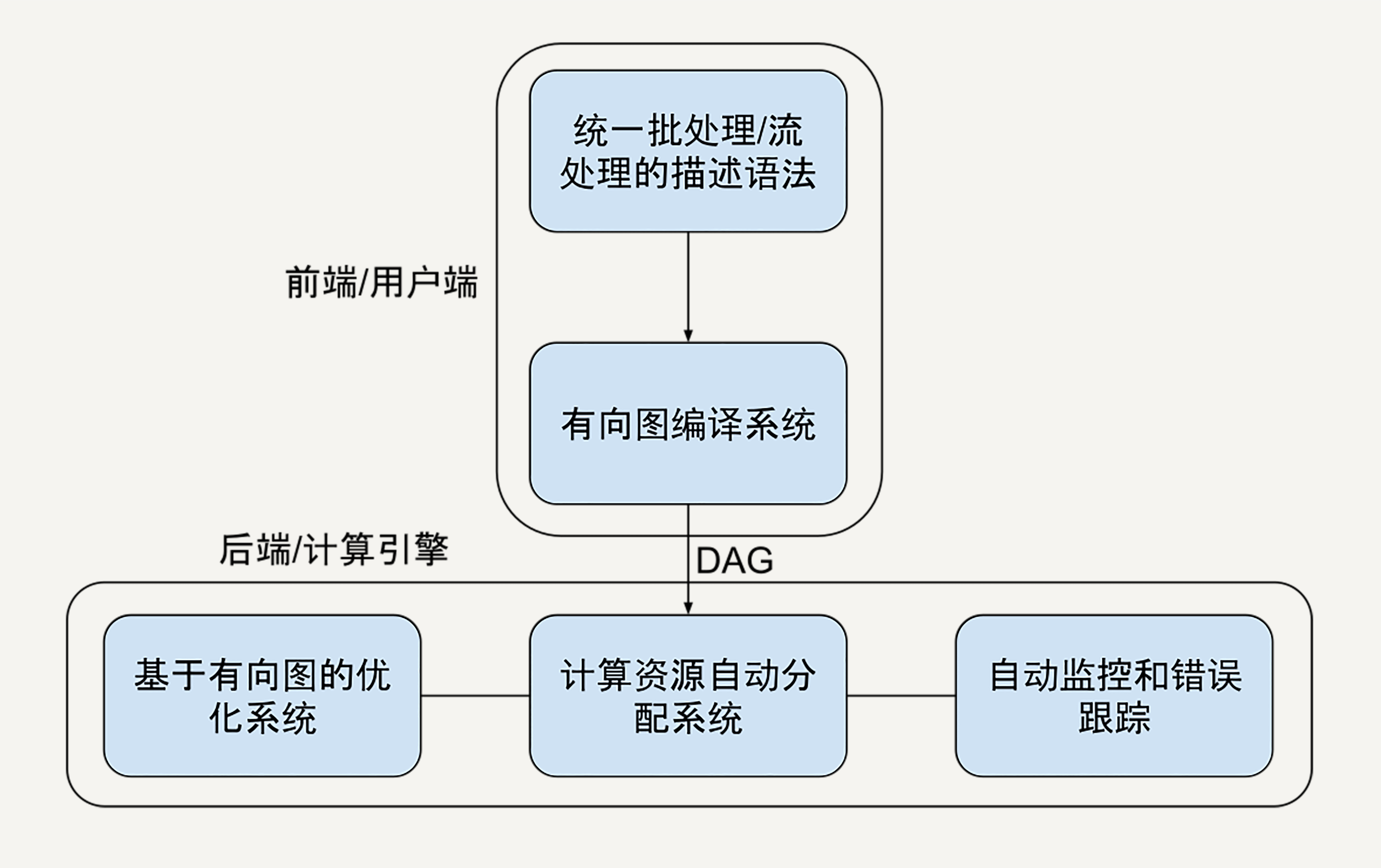
但是这样粗糙的设计和思想实验离实现还是太远。你可能还是会感到无从下手。
后面的章节会给你补充一些设计和使用大规模数据处理架构的基础知识。同时,也会深入剖析两个与我们这里的设计理念最接近的大数据处理框架,Apache Spark 和 Apache Beam。
思考题
你现在在使用的数据处理技术有什么问题,你有怎样的改进设计?
欢迎你把自己的想法写在留言区,与我和其他同学一起讨论。
如果你觉得有所收获,也欢迎把文章分享给你的朋友。

精选留言(49)
 mjl 置顶2019-04-19 25Unify platform和批流统一已经是主要趋势了,而我个人目前只对spark、flink有一定的了解。对于spark来说,无疑是很优秀的一个引擎,包括它的all in one的组件栈,structured streaming出来后的批流api的统一,目前在做的continues Mode。而flink,的确因为阿里的运营,在国内火了。但也展现了它的独有优势,更加贴近dataflow model的思想。同时,基于社区以及阿里、华为小伙伴的努力,flink的table/sql 的api也得到的很大的增强,提供了流批统一的api。虽然底层然后需要分化为dataset和datastream以及runtime层的batchTask和StreamTask,但是现在也在rethink the stack,这个point在2019 SF 的大会也几乎吸引了所有人。但就现状而言,flink的确有着理念上的优势(流是批的超集),同时也有迅猛上升的趋势。展开
mjl 置顶2019-04-19 25Unify platform和批流统一已经是主要趋势了,而我个人目前只对spark、flink有一定的了解。对于spark来说,无疑是很优秀的一个引擎,包括它的all in one的组件栈,structured streaming出来后的批流api的统一,目前在做的continues Mode。而flink,的确因为阿里的运营,在国内火了。但也展现了它的独有优势,更加贴近dataflow model的思想。同时,基于社区以及阿里、华为小伙伴的努力,flink的table/sql 的api也得到的很大的增强,提供了流批统一的api。虽然底层然后需要分化为dataset和datastream以及runtime层的batchTask和StreamTask,但是现在也在rethink the stack,这个point在2019 SF 的大会也几乎吸引了所有人。但就现状而言,flink的确有着理念上的优势(流是批的超集),同时也有迅猛上升的趋势。展开作者回复: 谢谢你的留言!感觉活捉了一只技术大牛呢。
是的,Spark的话虽然原生Spark Streaming Model和Dataflow Model不一样,但是Cloudera Labs也有根据Dataflow Model的原理实现了Spark Dataflow使得Beam可以跑Spark runner。
而对于Flink来说的话,在0.10版本以后它的DataStream API就已经是根据Dataflow Model的思想来重写了。现在Flink也支持两套API,分别是DataStream版本的和Beam版本的。其实data Artisans一直都有和Google保持交流,希望未来两套Beam和Flink的API能达到统一。
最后赞一点批处理是流处理的子集,这个观点我在第一讲留言也提到过。
如果觉得有收获,欢迎分享给朋友!同时也欢迎你继续留言交流,一起学习进步! leben kri...2019-04-19 91. DAG是将一系列的转换函数连接起来,最后调用真正的计算函数
leben kri...2019-04-19 91. DAG是将一系列的转换函数连接起来,最后调用真正的计算函数
2. 番茄炒鸡蛋,炒牛腩这个例子,说明不要进行重复计算,要复用之前的计算。而且在计算之前过滤掉不必要的数据,最大限度的减少计算量。
现在使用的数据处理技术遇到的问题就是在两个大表进行关联的时候,没有太多的优化手段,自己能想到的就是增加计算资源(但是条件不允许),然后过滤掉两个表中不必要的数据,但其实优化之后还是会很慢。
希望老师能分享一下大表和大表join的优化手段!展开 段斌2019-04-19 6Q:你现在在使用的数据处理技术有什么问题,你有怎样的改进设计?
段斌2019-04-19 6Q:你现在在使用的数据处理技术有什么问题,你有怎样的改进设计?
A:简单介绍下我自己的背景,以前有RDBMS时期的数据仓库经验,后来没有跟上Hadoop发展的节奏,逐渐转向了前台业务部门。现在在一家sdk行为数据采集与分析厂商做解决方案,但是公司有很多技术栈:storm+es,flink,spark,还有最新的kudu+carbandata,学习起来非常吃力。
基于本期的课程,我有几个问题:
1. storm+es实时大数据平台的出现是解决什么问题?优势是什么,未来是否会被其他技术栈取代?
2. 我们客户在用这个技术栈的产品,反馈查错成本很高,不知道在sdk采集时候数据没有收上来,还是在collector,或者是后面丢失。我想问数据监控是大数据普遍问题吗?业内是怎么解决的?
3. 咱们是否会介绍Apache Carbondata,这个技术栈的优势是什么?你怎么看待它的发展?展开 孙稚昊2019-04-19 5Flink在国内也是刚刚兴起火热起来,而Apache Beam也就是Google内部FlumeJava的开源版本早早就被设计出来。国内现在讲实时数据处理,批流统一还是比较推崇Flink和阿里的自主设计的Blink系统,接受Beam可能还需要几年的时间
孙稚昊2019-04-19 5Flink在国内也是刚刚兴起火热起来,而Apache Beam也就是Google内部FlumeJava的开源版本早早就被设计出来。国内现在讲实时数据处理,批流统一还是比较推崇Flink和阿里的自主设计的Blink系统,接受Beam可能还需要几年的时间 流殇忘情2019-04-19 5我说说我们在线上遇到过的实际问题,我们是做内容的,当内容产生view数的时候会发送用户行为日志,这个时候通过消费消息队列中的数据为用户进行收益的计算,但是这个数据是有有效期的,曾经出现过由于bug产生一些数据没有及时消费,就需要手动进行补救,看完今天的文章,我觉得可以对有时效性的数据进行标注,如果没有成功消费,系统也可以方便的找到进行自动修复。展开
流殇忘情2019-04-19 5我说说我们在线上遇到过的实际问题,我们是做内容的,当内容产生view数的时候会发送用户行为日志,这个时候通过消费消息队列中的数据为用户进行收益的计算,但是这个数据是有有效期的,曾经出现过由于bug产生一些数据没有及时消费,就需要手动进行补救,看完今天的文章,我觉得可以对有时效性的数据进行标注,如果没有成功消费,系统也可以方便的找到进行自动修复。展开作者回复: 你说的很好啊
- fy2019-04-20 3虽然看的不是很懂,毕竟没搞过这方面的,但是每篇文章的知识点逻辑很清楚,学习中,这里尊称一句蔡老师,被老师的回复学者的留言给感动了。期待老师后面精彩的专栏展开
作者回复: 谢谢肯定。期待你后面的留言。
也欢迎推荐给朋友!  Milittle2019-04-20 3讲真,这个思路太清晰了。讲到有向图那里,还没看到tf那段,我脑子里第一蹦出来的就是深度学习里面的符号式计算图,可以在图编译的时候进行优化。然后在计算时可以加速运算,还有就是,这里的计算图用拓扑排序结合优先级队列来执行计算。
Milittle2019-04-20 3讲真,这个思路太清晰了。讲到有向图那里,还没看到tf那段,我脑子里第一蹦出来的就是深度学习里面的符号式计算图,可以在图编译的时候进行优化。然后在计算时可以加速运算,还有就是,这里的计算图用拓扑排序结合优先级队列来执行计算。
我还是个学生,有不对的地方请指教,没在真实场景中体验过,但是感觉这些都是通用的,学会了,处处可以用到。期待后续课程给更多的启发,谢谢(*°∀°)=3展开作者回复: 你理解的很多!期待你后面的分享
- Codelife2019-04-19 3我们是做车联网业务的,目前实时处理采用的storm,批处理采用的是MR,和您的文章中描述的一样,业务场景和算法中经常出现实时和批处理共存的情况,为了保证实时性,通常是定时执行MR任务计算出中间结果,再由storm任务调用,这样的坏处是MR任务并不及时,而且维护起来很麻烦,效果并不理想。希望能够从apache beam中学到东西展开
作者回复: 谢谢你的留言!我在第十讲中所讲解到的Lambda Architecture应该会对你们的架构设计有所帮助。希望能在那时继续看到你的留言。
 wmg2019-04-19 3现在使用较多的是hive和sparkSql,这两种技术多使用的都是类似关系数据库的数据模型,对于一些复杂的对象必须要通过建立多张表来存储,查询时可能需要多张表进行join,由于担心join的性能损耗,一般又会设计成大宽表,但这样又会浪费存储空间,数据一致性也得不到约束。想问一下老师,有没有支持类似mongodb这样的文档型数据模型的大数据处理技术?展开
wmg2019-04-19 3现在使用较多的是hive和sparkSql,这两种技术多使用的都是类似关系数据库的数据模型,对于一些复杂的对象必须要通过建立多张表来存储,查询时可能需要多张表进行join,由于担心join的性能损耗,一般又会设计成大宽表,但这样又会浪费存储空间,数据一致性也得不到约束。想问一下老师,有没有支持类似mongodb这样的文档型数据模型的大数据处理技术?展开作者回复: 数据的索引查询和这里的数据处理是两个话题。关于怎么提高数据系统的查询效率,我在考虑要不要开一个存储系统高性能索引专栏。
我不知道你的查询有多复杂,简单处理的话,可以先试试建一些常见查询路径的索引表。写的时候往两张表写或者再做一些专门的建索引的数据处理系统。 大王叫我来...2019-04-19 3经历了mapreduce到spark, 从最具欺骗性的wordcount开始到发现很多业务本身并不适合mapreduce编程模型,一直做日志处理,现在在政府某部门同时处理批处理任务和流处理任务,老师的课太及时了,感觉对我们的业务模型革新会产生很大的影响,前两篇没有涉及技术,已经感觉醍醐灌顶了。
大王叫我来...2019-04-19 3经历了mapreduce到spark, 从最具欺骗性的wordcount开始到发现很多业务本身并不适合mapreduce编程模型,一直做日志处理,现在在政府某部门同时处理批处理任务和流处理任务,老师的课太及时了,感觉对我们的业务模型革新会产生很大的影响,前两篇没有涉及技术,已经感觉醍醐灌顶了。作者回复: 你说的对,WordCount就像helloworld,真实业务场景肯定会复杂很多。
 文洲2019-04-19 3老师讲的很明白,有个疑问,现在都说flink是下一代实时流处理系统,这里按老师的对比来看,它还比不上spark,可否理解为flink主要还是专注实时流处理而spark有兼具批处理和流处理的优势展开
文洲2019-04-19 3老师讲的很明白,有个疑问,现在都说flink是下一代实时流处理系统,这里按老师的对比来看,它还比不上spark,可否理解为flink主要还是专注实时流处理而spark有兼具批处理和流处理的优势展开作者回复: 并没有说flink比不上spark。。。这篇没有展开比较。只是带了一句话flink的流处理批处理api不一样。
 小辉辉2019-04-21 2看完前三讲,让我对大数据又有一个更新的认识展开
小辉辉2019-04-21 2看完前三讲,让我对大数据又有一个更新的认识展开作者回复: 谢谢你的肯定!同时也欢迎你把专栏分享给朋友。
 monkeykin...2019-04-20 2老师,啥叫dataflow?从字面上来看好像和dag差不多,不知道我理解的是否正确,还请老师指正
monkeykin...2019-04-20 2老师,啥叫dataflow?从字面上来看好像和dag差不多,不知道我理解的是否正确,还请老师指正作者回复: 谢谢你的提问!在留言区里的Dataflow指的是Google在2015发表的Dataflow Model数据处理模型。
 电光火石2019-04-20 2我们做风控的,现在每天收的数据比较多,现在都是先通过spark streaming落地hive,然后每天批量跑任务做模型训练和分析,因为现在模型训练还是集中在离线训练,在线训练约束比较大,所以使用场景还比较小,训练处理的模型在通过导出到pmml在线预测,整个作为一个闭环。不知道google在这方面试怎么处理的?谢谢!
电光火石2019-04-20 2我们做风控的,现在每天收的数据比较多,现在都是先通过spark streaming落地hive,然后每天批量跑任务做模型训练和分析,因为现在模型训练还是集中在离线训练,在线训练约束比较大,所以使用场景还比较小,训练处理的模型在通过导出到pmml在线预测,整个作为一个闭环。不知道google在这方面试怎么处理的?谢谢!
另外,老师有个理念很新颖(从处理的数据范围来看批处理和实时计算,批处理的数据是有界的,实时计算的数据是无界的),我一直从处理的间隔来看批处理和实时计算,觉得实时计算是批处理的一种,就是不断的把离线任务处理频率做个极限,就变成了实时计算。展开作者回复: 专栏里提到了这种应用在google有1000个,所以很难概括说这类应用google怎么处理的。你的方法既然能解决问题就好了。
关于流处理批处理后面的章节还会深入讨论。 来碗绿豆汤2019-04-20 2蔡老师好,看到您那么认真的回复读者问题,果断决定买了,跟着您一起学习。我们最近在打算重构一个项目,想听听您的建议。系统的输入是将近1TB的数据文件(好多个文件,不是一个大文件),内容就是一条条记录,描述了某个实体的某个属性。我们要做的就是把属于同一个实体的属性整合到一起,然后将数据按实体id排序输出,没100万个实体写一个文件。我现在的思路就是:第一步,把文件重新按照实体id切块,然后排序写成小文件,这一步可以是一个程序;第二步,对id属于某个范围内的(如1-100w)文件,归并排序,这一步一个程序;第三步,对排好序的文件按指定格式输出。因为以前没接触过大数据相关技术,所以现在是用java实现的demo版本,就像你课程里面所示,担心将来各个进程,线程之间,交互通信,异常处理,log处理,等一系列问题都需要自己维护会比较麻烦,想听听您的建议。展开
来碗绿豆汤2019-04-20 2蔡老师好,看到您那么认真的回复读者问题,果断决定买了,跟着您一起学习。我们最近在打算重构一个项目,想听听您的建议。系统的输入是将近1TB的数据文件(好多个文件,不是一个大文件),内容就是一条条记录,描述了某个实体的某个属性。我们要做的就是把属于同一个实体的属性整合到一起,然后将数据按实体id排序输出,没100万个实体写一个文件。我现在的思路就是:第一步,把文件重新按照实体id切块,然后排序写成小文件,这一步可以是一个程序;第二步,对id属于某个范围内的(如1-100w)文件,归并排序,这一步一个程序;第三步,对排好序的文件按指定格式输出。因为以前没接触过大数据相关技术,所以现在是用java实现的demo版本,就像你课程里面所示,担心将来各个进程,线程之间,交互通信,异常处理,log处理,等一系列问题都需要自己维护会比较麻烦,想听听您的建议。展开作者回复: 这个是很典型的问题。后面学到了一些框架之后可以很方便用groupBy进行处理。
 王二2019-04-19 2老师您好:
王二2019-04-19 2老师您好:
1.如您所说flink在批流处理上的不统一,目前社区各个厂商也在努力的实现这种基于SQL或其他引擎的一些统一,这块在您看来有什么好的建议。
2.后面文章使用spark举例,这里是用他的struct streaming还是spark streaming呢.
3.感同身受,流系统难的不在开发,在于监控,如何处理背压,如何根据负载动态调整资源,除过开源框架自带的一些监控外,后续在任务流监控这块是否有什么好的建议推荐。展开作者回复: 都是很好的问题
1 SQL 就是一个统一的用户界面,后面的引擎可以是hive也可以是自己实现的别的
2 看到spark部分就知道了 :)
3 的确,监控部分我可以看看是否在后面的部分增加章节 dylan2019-04-19 2有没有这么一个问题,mapreduce在大规模数据处理时,由于每个计算阶段都会落盘,所以计算比较慢,但是数据完整,不会丢失;spark基于内存计算,会有数据丢失的风险?展开
dylan2019-04-19 2有没有这么一个问题,mapreduce在大规模数据处理时,由于每个计算阶段都会落盘,所以计算比较慢,但是数据完整,不会丢失;spark基于内存计算,会有数据丢失的风险?展开作者回复: 容错性是很重要的问题,两个的容错性设计方案是不同的。
 退而结网2019-04-20 1在极客时间订阅了几个专栏了,有些专栏留言的问题很少得到专栏老师的回复,看了下蔡老师的留言回复,基本上都是有问必答。这两节专栏的内容真的很多干货,同学们的留言也给了我很多启发。作为大数据处理的半入门汉,希望能在这门课程中得到更多的收获,祝愿和大家共同进步!
退而结网2019-04-20 1在极客时间订阅了几个专栏了,有些专栏留言的问题很少得到专栏老师的回复,看了下蔡老师的留言回复,基本上都是有问必答。这两节专栏的内容真的很多干货,同学们的留言也给了我很多启发。作为大数据处理的半入门汉,希望能在这门课程中得到更多的收获,祝愿和大家共同进步!作者回复: 谢谢,欢迎把专栏分享给朋友
 明翼2019-04-20 1老师我补充下我的三个问题:
明翼2019-04-20 1老师我补充下我的三个问题:
1.这种两个流都是大数据量的一般业界用什么样计算模型去做匹配,目前我们是用spark写的匹配?
2.由于一个流(假设名字为A流)的数据时间跨度比较大,比如几天前的数据,这就要求另外一个流(假设为B流)必须有缓存,而从缓存中抽取B流数据时候,会根据时间和Ip的hash原一批数据和A流匹配,那这个缓存用什么比较好那?我们原来用Hbase后发现数据量大scan比较慢,改hdfs直接存储了,勉强可以用。
3.我们最终结果数据一天也有几百亿条,目前存Es里面的,业务要求查询性能分钟级别就可以接受,我们查询性能够了,但是索引数据存储空间占用大,入索引性能一般,我们想换个高压缩性能分钟级的存储系统,目前考虑用列式存储➕ SQL引擎来做,这种没经验是否合适?
谢谢老师耐心看完,有空指点下谢谢展开作者回复: 似乎和本篇内容并不相关。general的技术咨询我看看能不能让平台拉群讨论
 :)2019-04-20 1期待更新!展开
:)2019-04-20 1期待更新!展开
















