09丨子查询:子查询的种类都有哪些,如何提高子查询的性能?





讲述:陈旸
时长11:41大小10.71M
上节课我讲到了聚集函数,以及如何对数据进行分组统计,可以说我们之前讲的内容都是围绕单个表的 SELECT 查询展开的,实际上 SQL 还允许我们进行子查询,也就是嵌套在查询中的查询。这样做的好处是可以让我们进行更复杂的查询,同时更加容易理解查询的过程。因为很多时候,我们无法直接从数据表中得到查询结果,需要从查询结果集中再次进行查询,才能得到想要的结果。这个“查询结果集”就是今天我们要讲的子查询。
通过今天的文章,我希望你可以掌握以下的内容:
- 子查询可以分为关联子查询和非关联子查询。我会举一个 NBA 数据库查询的例子,告诉你什么是关联子查询,什么是非关联子查询;
- 子查询中有一些关键词,可以方便我们对子查询的结果进行比较。比如存在性检测子查询,也就是 EXISTS 子查询,以及集合比较子查询,其中集合比较子查询关键词有 IN、SOME、 ANY 和 ALL,这些关键词在子查询中的作用是什么;
- 子查询也可以作为主查询的列,我们如何使用子查询作为计算字段出现在 SELECT 查询中呢?
什么是关联子查询,什么是非关联子查询
子查询虽然是一种嵌套查询的形式,不过我们依然可以依据子查询是否执行多次,从而将子查询划分为关联子查询和非关联子查询。
子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件进行执行,那么这样的子查询叫做非关联子查询。
同样,如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,每次都传入子查询进行查询,然后再将结果反馈给外部,这种嵌套的执行方式就称为关联子查询。
单说概念有点抽象,我们用数据表举例说明一下。这里我创建了 NBA 球员数据库,SQL 文件你可以从GitHub上下载。
文件中一共包括了 5 张表,player 表为球员表,team 为球队表,team_score 为球队比赛表,player_score 为球员比赛成绩表,height_grades 为球员身高对应的等级表。
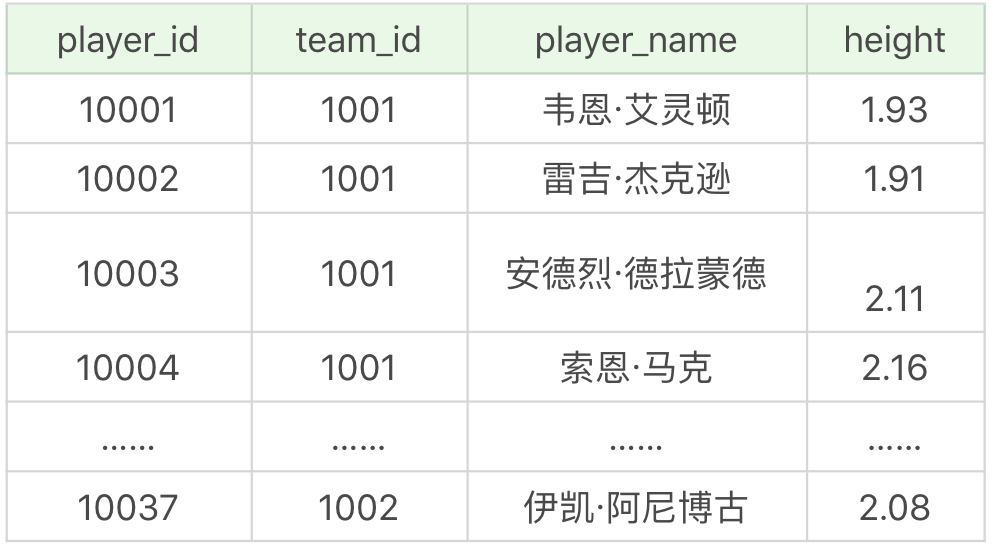
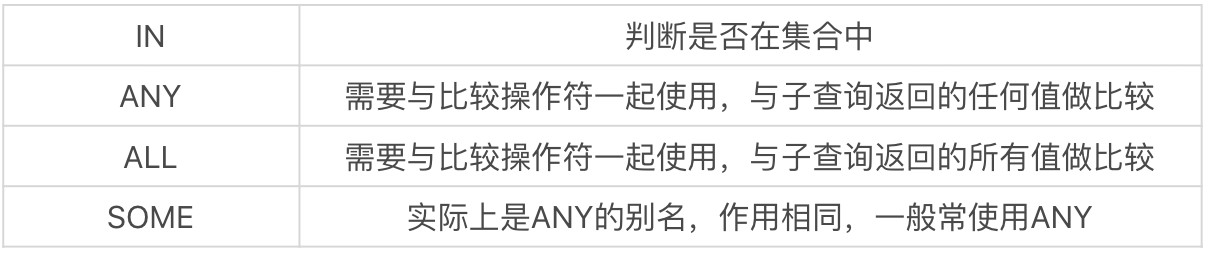
其中 player 表,也就是球员表,一共有 37 个球员,如下所示:
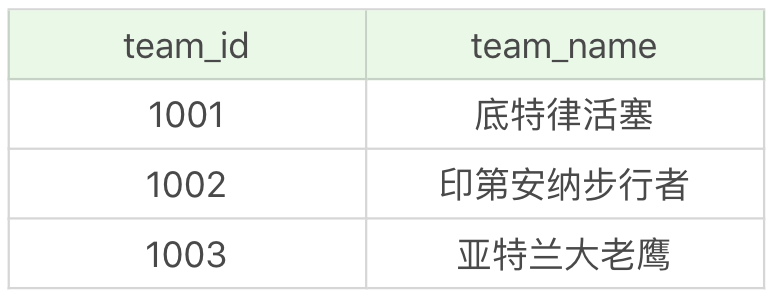
team 表为球队表,一共有 3 支球队,如下所示:
team_score 表为球队比赛成绩表,一共记录了两场比赛的成绩,如下所示:

player_score 表为球员比赛成绩表,记录了一场比赛中球员的表现。这张表一共包括 19 个字段,代表的含义如下:
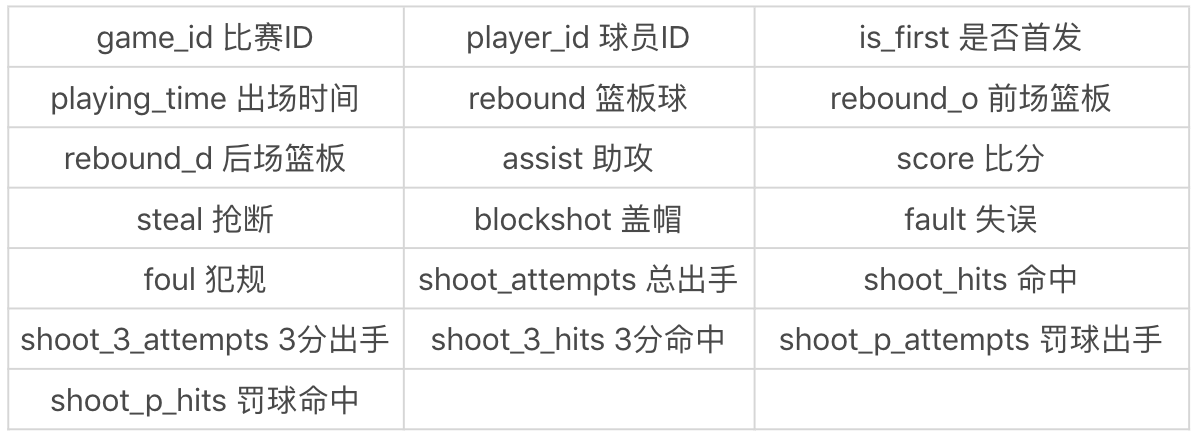
其中 shoot_attempts 代表总出手的次数,它等于二分球出手和三分球出手次数的总和。比如 2019 年 4 月 1 日,韦恩·艾灵顿在底特律活塞和印第安纳步行者的比赛中,总出手次数为 19,总命中 10,三分球 13 投 4 中,罚球 4 罚 2 中,因此总分 score=(10-4)×2+4×3+2=26,也就是二分球得分 12+ 三分球得分 12+ 罚球得分 2=26。
需要说明的是,通常在工作中,数据表的字段比较多,一开始创建的时候会知道每个字段的定义,过了一段时间再回过头来看,对当初的定义就不那么确定了,容易混淆字段,解决这一问题最好的方式就是做个说明文档,用实例举例。
比如 shoot_attempts 是总出手次数(这里的总出手次数 = 二分球出手次数 + 三分球出手次数,不包括罚球的次数),用上面提到的韦恩·艾灵顿的例子做补充说明,再回过头来看这张表的时候,就可以很容易理解每个字段的定义了。
我们以 NBA 球员数据表为例,假设我们想要知道哪个球员的身高最高,最高身高是多少,就可以采用子查询的方式:
运行结果:(1 条记录)

你能看到,通过SELECT max(height) FROM player可以得到最高身高这个数值,结果为 2.16,然后我们再通过 player 这个表,看谁具有这个身高,再进行输出,这样的子查询就是非关联子查询。
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为关联子查询。比如我们想要查找每个球队中大于平均身高的球员有哪些,并显示他们的球员姓名、身高以及所在球队 ID。
首先我们需要统计球队的平均身高,即SELECT avg(height) FROM player AS b WHERE a.team_id = b.team_id,然后筛选身高大于这个数值的球员姓名、身高和球队 ID,即:
运行结果:(18 条记录)
EXISTS 子查询
关联子查询通常也会和 EXISTS 一起来使用,EXISTS 子查询用来判断条件是否满足,满足的话为 True,不满足为 False。
比如我们想要看出场过的球员都有哪些,并且显示他们的姓名、球员 ID 和球队 ID。在这个统计中,是否出场是通过 player_score 这张表中的球员出场表现来统计的,如果某个球员在 player_score 中有出场记录则代表他出场过,这里就使用到了 EXISTS 子查询,即EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id),然后将它作为筛选的条件,实际上也是关联子查询,即:
运行结果:(19 条记录)
同样,NOT EXISTS 就是不存在的意思,我们也可以通过 NOT EXISTS 查询不存在于 player_score 表中的球员信息,比如主表中的 player_id 不在子表 player_score 中,判断语句为NOT EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)。整体的 SQL 语句为:
运行结果:(18 条记录)
集合比较子查询
集合比较子查询的作用是与另一个查询结果集进行比较,我们可以在子查询中使用 IN、ANY、ALL 和 SOME 操作符,它们的含义和英文意义一样:
还是通过上面那个例子,假设我们想要看出场过的球员都有哪些,可以采用 IN 子查询来进行操作:
你会发现运行结果和上面的是一样的,那么问题来了,既然 IN 和 EXISTS 都可以得到相同的结果,那么我们该使用 IN 还是 EXISTS 呢?
我们可以把这个模式抽象为:
实际上在查询过程中,在我们对 cc 列建立索引的情况下,我们还需要判断表 A 和表 B 的大小。在这里例子当中,表 A 指的是 player 表,表 B 指的是 player_score 表。如果表 A 比表 B 大,那么 IN 子查询的效率要比 EXIST 子查询效率高,因为这时 B 表中如果对 cc 列进行了索引,那么 IN 子查询的效率就会比较高。
同样,如果表 A 比表 B 小,那么使用 EXISTS 子查询效率会更高,因为我们可以使用到 A 表中对 cc 列的索引,而不用从 B 中进行 cc 列的查询。
了解了 IN 查询后,我们来看下 ANY 和 ALL 子查询。刚才讲到了 ANY 和 ALL 都需要使用比较符,比较符包括了(>)(=)(<)(>=)(<=)和(<>)等。
如果我们想要查询球员表中,比印第安纳步行者(对应的 team_id 为 1002)中任何一个球员身高高的球员的信息,并且输出他们的球员 ID、球员姓名和球员身高,该怎么写呢?首先我们需要找出所有印第安纳步行者队中的球员身高,即SELECT height FROM player WHERE team_id = 1002,然后使用 ANY 子查询即:
运行结果:(35 条记录)
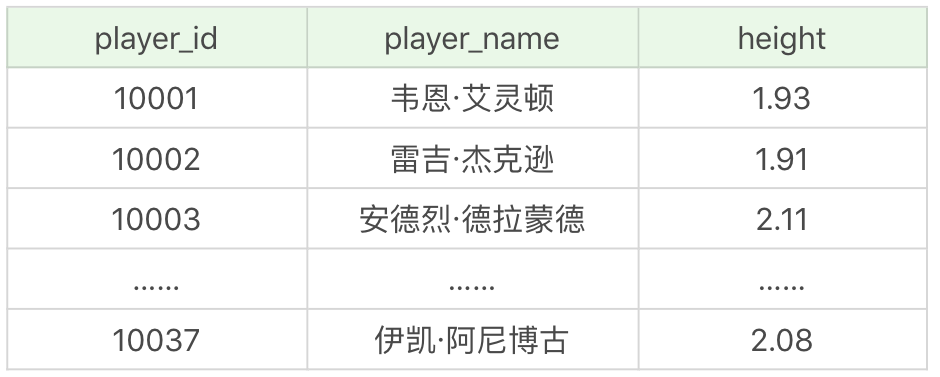
运行结果为 35 条,你发现有 2 个人的身高是不如印第安纳步行者的所有球员的。
同样,如果我们想要知道比印第安纳步行者(对应的 team_id 为 1002)中所有球员身高都高的球员的信息,并且输出球员 ID、球员姓名和球员身高,该怎么写呢?
运行结果:(1 条记录)

我们能看到比印第安纳步行者所有球员都高的球员,在 player 这张表(一共 37 个球员)中只有索恩·马克。
需要强调的是 ANY、ALL 关键字必须与一个比较操作符一起使用。因为如果你不使用比较操作符,就起不到集合比较的作用,那么使用 ANY 和 ALL 就没有任何意义。
将子查询作为计算字段
我刚才讲了子查询的几种用法,实际上子查询也可以作为主查询的计算字段。比如我想查询每个球队的球员数,也就是对应 team 这张表,我需要查询相同的 team_id 在 player 这张表中所有的球员数量是多少。
运行结果:(3 条记录)
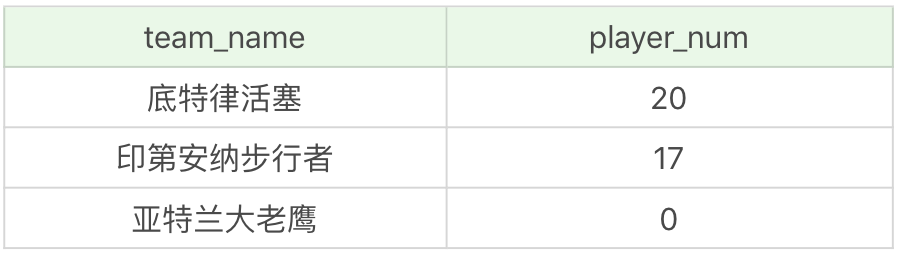
你能看到,在 player 表中只有底特律活塞和印第安纳步行者的球员数据,所以它们的 player_num 不为 0,而亚特兰大老鹰的 player_num 等于 0。在查询的时候,我将子查询SELECT count(*) FROM player WHERE player.team_id = team.team_id作为了计算字段,通常我们需要给这个计算字段起一个别名,这里我用的是 player_num,因为子查询的语句比较长,使用别名更容易理解。
总结
今天我讲解了子查询的使用,按照子查询执行的次数,我们可以将子查询分成关联子查询和非关联子查询,其中非关联子查询与主查询的执行无关,只需要执行一次即可,而关联子查询,则需要将主查询的字段值传入子查询中进行关联查询。
同时,在子查询中你可能会使用到 EXISTS、IN、ANY、ALL 和 SOME 等关键字。在某些情况下使用 EXISTS 和 IN 可以得到相同的效果,具体使用哪个执行效率更高,则需要看字段的索引情况以及表 A 和表 B 哪个表更大。同样,IN、ANY、ALL、SOME 这些关键字是用于集合比较的,SOME 是 ANY 的别名,当我们使用 ANY 或 ALL 的时候,一定要使用比较操作符。
最后,我讲解了如何使用子查询作为计算字段,把子查询的结果作为主查询的列。
SQL 中,子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较。

我今天讲解了子查询的使用,其中讲到了 EXISTS 和 IN 子查询效率的比较,当查询字段进行了索引时,主表 A 大于从表 B,使用 IN 子查询效率更高,相反主表 A 小于从表 B 时,使用 EXISTS 子查询效率更高,同样,如果使用 NOT IN 子查询和 NOT EXISTS 子查询,在什么情况下,哪个效率更高呢?
最后请你使用子查询,编写 SQL 语句,得到场均得分大于 20 的球员。场均得分从 player_score 表中获取,同时你需要输出球员的 ID、球员姓名以及所在球队的 ID 信息。
欢迎在评论区写下你的思考,也欢迎点击请朋友读把这篇文章分享给你的朋友或者同事。

精选留言(65)
 看,有只猪2019-07-01IN表是外边和内表进行hash连接,是先执行子查询。
看,有只猪2019-07-01IN表是外边和内表进行hash连接,是先执行子查询。
EXISTS是对外表进行循环,然后在内表进行查询。
因此如果外表数据量大,则用IN,如果外表数据量小,也用EXISTS。
IN有一个缺陷是不能判断NULL,因此如果字段存在NULL值,则会出现返回,因为最好使用NOT EXISTS。展开 1 15 Sam2019-07-01not in是先执行子查询,得到一个结果集,将结果集代入外层谓词条件执行主查询,子查询只需要执行一次;
Sam2019-07-01not in是先执行子查询,得到一个结果集,将结果集代入外层谓词条件执行主查询,子查询只需要执行一次;
not exists是先从主查询中取得一条数据,再代入到子查询中,执行一次子查询,判断子查询是否能返回结果,主查询有多少条数据,子查询就要执行多少次。
展开 5 Mr.H2019-07-01最后的总结in和exist写反了吧展开 5
Mr.H2019-07-01最后的总结in和exist写反了吧展开 5 Liam2019-07-01老师您好,关于exist和in的差别,总结和举例的不符吧?主表大于从表不应该是使用in更好吗 2 4
Liam2019-07-01老师您好,关于exist和in的差别,总结和举例的不符吧?主表大于从表不应该是使用in更好吗 2 4 悟空2019-07-01# 使用exists
悟空2019-07-01# 使用exists
SELECT player_name,player_id,team_id from player WHERE EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id and score >20)
# 使用 in
SELECT player_name,player_id,team_id from player WHERE player_id IN (SELECT player_id FROM player_score WHERE score >20)
使用:join 语句
SELECT p.player_name,p.player_id,p.team_id,t.score from player AS p JOIN player_score as t WHERE p.player_id = t.player_id and t.score >20展开 2 Fred2019-07-01SELECT player_id , player_name, team_id FROM player AS a WHERE a.player_id IN (SELECT player_id FROM play_score AS b WHERE a.player_id=b.player_id AND AVG(b.score)>20)展开 2
Fred2019-07-01SELECT player_id , player_name, team_id FROM player AS a WHERE a.player_id IN (SELECT player_id FROM play_score AS b WHERE a.player_id=b.player_id AND AVG(b.score)>20)展开 2- 华夏2019-07-01SELECT player_id, team_id, player_name FROM player WHERE player_id in (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id);
老师,文稿中这句的WHERE player.player_id = player_score.player_id可以不要了哈。展开 2 - 华夏2019-07-01SELECT player_id, player_name, team_id FROM player AS a WHERE (SELECT score FROM player_score AS b WHERE a.player_id = b.player_id) > 20;
+-----------+------------------+---------+
| player_id | player_name | team_id |
+-----------+------------------+---------+
| 10001 | 韦恩-艾灵顿 | 1001 |
| 10002 | 雷吉-杰克逊 | 1001 |
+-----------+------------------+---------+
2 rows in set (0.01 sec)展开 2 - Hero2019-07-011. SELECT
player_id,
team_id,
player_name
FROM
player a
WHERE
EXISTS ( SELECT b.player_id FROM player_score b GROUP BY b.player_id HAVING AVG( b.score ) > 20 and a.player_id = b.player_id);
2.SELECT
player_id,
team_id,
player_name
FROM
player a
WHERE
EXISTS ( SELECT b.player_id FROM player_score b WHERE a.player_id = b.player_id GROUP BY b.player_id HAVING AVG( b.score ) > 20);
3.SELECT
player_id,
team_id,
player_name
FROM
player
WHERE
player_id IN ( SELECT player_id FROM player_score GROUP BY player_id HAVING AVG( score ) > 20 );
推荐3,因为子查询只会执行一次。2比1好,因为where会先过滤数据行,然后分组,然后对分组过滤。展开 2  Cary2019-07-01in 和 exist 上面和最后总结的好像不一致展开 1 2
Cary2019-07-01in 和 exist 上面和最后总结的好像不一致展开 1 2 Nixus2019-07-02看第二遍后, 又看了下评论, 突然觉得, 第二题中, 场均, 这个意思, 是不是 每场比赛每位队员的平均分大于20分的球员呢? 如果是, 感觉只用一个group by player_score.game_id, player_score.player_id不能满足条件, 如果分别group by player_score.game_id, group by player_score.player_id, 用多个子查询, 反而又变成了 每场比赛的分数, 每位球员的分数, 不知道该怎么做了...
Nixus2019-07-02看第二遍后, 又看了下评论, 突然觉得, 第二题中, 场均, 这个意思, 是不是 每场比赛每位队员的平均分大于20分的球员呢? 如果是, 感觉只用一个group by player_score.game_id, player_score.player_id不能满足条件, 如果分别group by player_score.game_id, group by player_score.player_id, 用多个子查询, 反而又变成了 每场比赛的分数, 每位球员的分数, 不知道该怎么做了...
另外, 看到评论中很多同学的回复, 觉得掌握 [NOT] IN 和 [NOT] EXISTS 在SQL中的执行顺序, 太有必要了. 请问老师有没有值得推荐的好书, 作为课外补充呢?
谢谢!展开 1 1 苏柏2019-07-02WHERE a.team_id = b.team_id
苏柏2019-07-02WHERE a.team_id = b.team_id
想确定一下这个条件 是在两个相同的表做笛卡尔积后 做了啥操作,能帮梳理一下思路吗展开 1 风翱2019-07-02SELECT player_id,player_name,team_id FROM player AS p WHERE p.player_id IN (SELECT player_id FROM player_score s GROUP BY s.player_id HAVING AVG(score) > 20);展开 1
风翱2019-07-02SELECT player_id,player_name,team_id FROM player AS p WHERE p.player_id IN (SELECT player_id FROM player_score s GROUP BY s.player_id HAVING AVG(score) > 20);展开 1 太乙鲲2019-07-01SELECT player_id, player_name, team_id FROM player WHERE player_id IN (SELECT player_id FROM player_score WHERE score > 20);
太乙鲲2019-07-01SELECT player_id, player_name, team_id FROM player WHERE player_id IN (SELECT player_id FROM player_score WHERE score > 20);
+-----------+------------------+---------+
| player_id | player_name | team_id |
+-----------+------------------+---------+
| 10001 | 韦恩-艾灵顿 | 1001 |
| 10002 | 雷吉-杰克逊 | 1001 |
+-----------+------------------+---------+展开 1 圆子蛋2019-07-01SELECT player_id,player_name,team_id FROM player WHERE player_id IN(SELECT player_id FROM player_score WHERE score > AVG(score) )展开 1
圆子蛋2019-07-01SELECT player_id,player_name,team_id FROM player WHERE player_id IN(SELECT player_id FROM player_score WHERE score > AVG(score) )展开 1- Geek_6698492019-07-07SELECT
t1.player_id,
t1.player_name,
t1.team_id
FROM
player t1
WHERE
t1.player_id IN (
SELECT
t2.player_id
FROM
player_score t2
GROUP BY
t2.player_id
HAVING
( AVG( t2.score ) > 20 )
)展开作者回复: 正确,而且SQL代码结构清晰
- Geek_6698492019-07-07实际工作中没用到果any all。什么样的情况下会可能用到呢?老师举的例子的话,直接比较最大值或者最小值就好了吧
 supermouse2019-07-07SELECT
supermouse2019-07-07SELECT
p.player_id, p.player_name, p.team_id
FROM
player_score AS ps1,
player AS p
WHERE
(SELECT
AVG(score)
FROM
player_score AS ps2
WHERE
ps1.player_id = ps2.player_id) > 20
AND p.player_id = ps1.player_id;展开作者回复: 正确,这也是一种写法
 算盘Man2019-07-06请教陈老师,exists子查询中括号内的 select player.player_id from player_score where player.player_id = player_score.player_id,为什么单独查这句会报错呢,当球员表的ID与得分表的ID相等时,查询球员ID的正确sql语句该怎么写啊,谢谢
算盘Man2019-07-06请教陈老师,exists子查询中括号内的 select player.player_id from player_score where player.player_id = player_score.player_id,为什么单独查这句会报错呢,当球员表的ID与得分表的ID相等时,查询球员ID的正确sql语句该怎么写啊,谢谢 mj4ever2019-07-06SELECT player_id,team_id,player_name FROM player WHERE player.player_id IN (SELECT player_id FROM player_score WHERE score > 20)
mj4ever2019-07-06SELECT player_id,team_id,player_name FROM player WHERE player.player_id IN (SELECT player_id FROM player_score WHERE score > 20)