08 | 键入网址再按下回车,后面究竟发生了什么?





讲述:Chrono(加微信:642945106 发送“赠送”领取赠送精品课程 发数字“2”获取众筹列表。)
时长11:30大小13.18M
经过上一讲的学习,你是否已经在自己的电脑上搭建好了“最小化”的 HTTP 实验环境呢?
我相信你的答案一定是“Yes”,那么,让我们立刻开始“螺蛳壳里做道场”,在这个实验环境里看一下 HTTP 协议工作的全过程。
使用 IP 地址访问 Web 服务器
首先我们运行 www 目录下的“start”批处理程序,启动本机的 OpenResty 服务器,启动后可以用“list”批处理确认服务是否正常运行。
然后我们打开 Wireshark,选择“HTTP TCP port(80)”过滤器,再鼠标双击“Npcap loopback Adapter”,开始抓取本机 127.0.0.1 地址上的网络数据。
第三步,在 Chrome 浏览器的地址栏里输入“http://127.0.0.1/”,再按下回车键,等欢迎页面显示出来后 Wireshark 里就会有捕获的数据包,如下图所示。
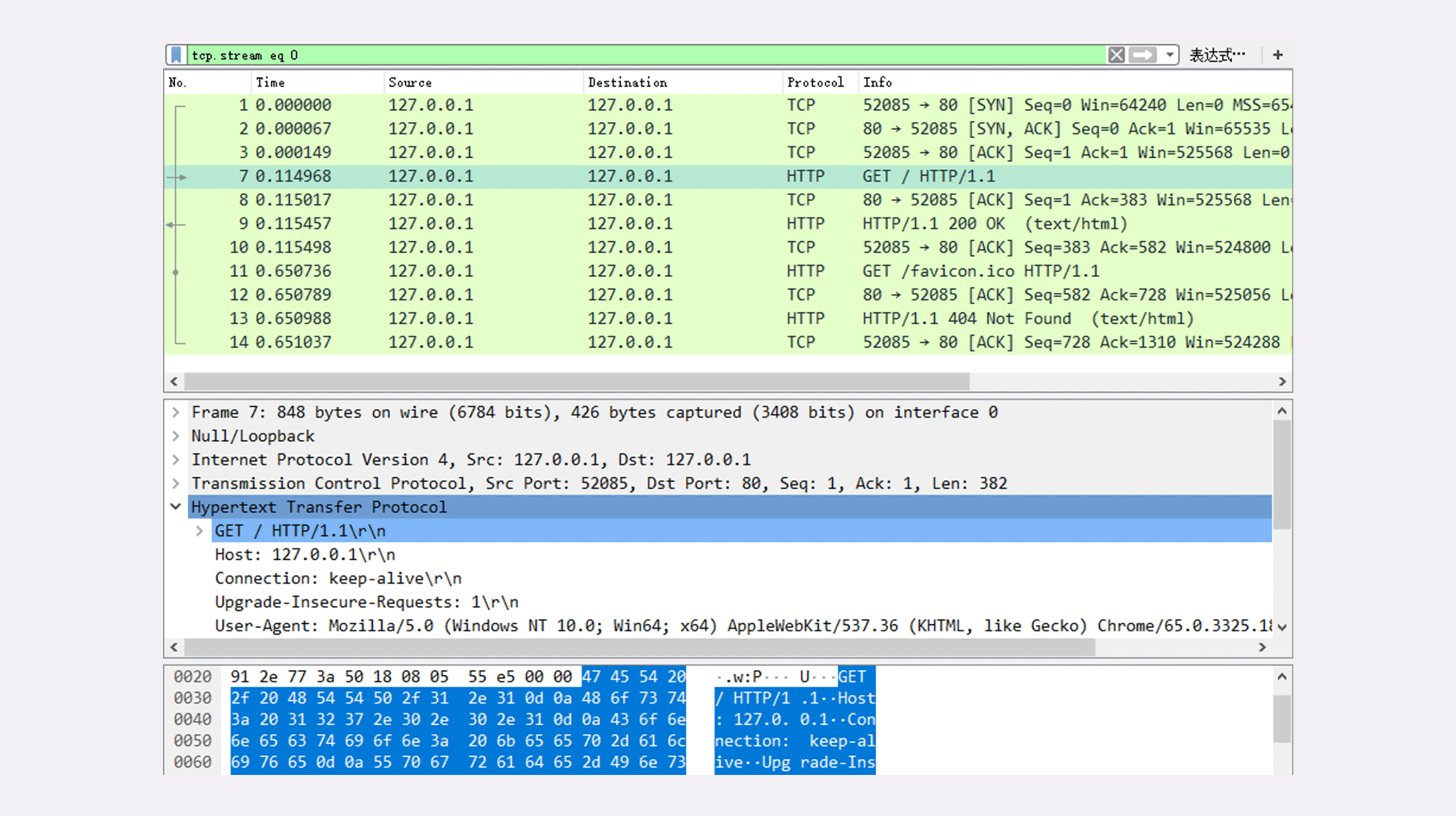
如果你还没有搭好实验环境,或者捕获与本文里的不一致也没关系。我把这次捕获的数据存成了 pcap 包,文件名是“08-1”,放到了 GitHub 上,你可以下载到本地后再用 Wireshark 打开,完全精确“重放”刚才的 HTTP 传输过程。
抓包分析
在 Wireshark 里你可以看到,这次一共抓到了 11 个包(这里用了滤包功能,滤掉了 3 个包,原本是 14 个包),耗时 0.65 秒,下面我们就来一起分析一下"键入网址按下回车"后数据传输的全过程。
通过前面“破冰篇”的讲解,你应该知道 HTTP 协议是运行在 TCP/IP 基础上的,依靠 TCP/IP 协议来实现数据的可靠传输。所以浏览器要用 HTTP 协议收发数据,首先要做的就是建立 TCP 连接。
因为我们在地址栏里直接输入了 IP 地址“127.0.0.1”,而 Web 服务器的默认端口是 80,所以浏览器就要依照 TCP 协议的规范,使用“三次握手”建立与 Web 服务器的连接。
对应到 Wireshark 里,就是最开始的三个抓包,浏览器使用的端口是 52085,服务器使用的端口是 80,经过 SYN、SYN/ACK、ACK 的三个包之后,浏览器与服务器的 TCP 连接就建立起来了。
有了可靠的 TCP 连接通道后,HTTP 协议就可以开始工作了。于是,浏览器按照 HTTP 协议规定的格式,通过 TCP 发送了一个“GET / HTTP/1.1”请求报文,也就是 Wireshark 里的第四个包。至于包的内容具体是什么现在先不用管,我们下一讲再说。
随后,Web 服务器回复了第五个包,在 TCP 协议层面确认:“刚才的报文我已经收到了”,不过这个 TCP 包 HTTP 协议是看不见的。
Web 服务器收到报文后在内部就要处理这个请求。同样也是依据 HTTP 协议的规定,解析报文,看看浏览器发送这个请求想要干什么。
它一看,原来是要求获取根目录下的默认文件,好吧,那我就从磁盘上把那个文件全读出来,再拼成符合 HTTP 格式的报文,发回去吧。这就是 Wireshark 里的第六个包“HTTP/1.1 200 OK”,底层走的还是 TCP 协议。
同样的,浏览器也要给服务器回复一个 TCP 的 ACK 确认,“你的响应报文收到了,多谢。”,即第七个包。
这时浏览器就收到了响应数据,但里面是什么呢?所以也要解析报文。一看,服务器给我的是个 HTML 文件,好,那我就调用排版引擎、JavaScript 引擎等等处理一下,然后在浏览器窗口里展现出了欢迎页面。
这之后还有两个来回,共四个包,重复了相同的步骤。这是浏览器自动请求了作为网站图标的“favicon.ico”文件,与我们输入的网址无关。但因为我们的实验环境没有这个文件,所以服务器在硬盘上找不到,返回了一个“404 Not Found”。
至此,“键入网址再按下回车”的全过程就结束了。
我为这个过程画了一个交互图,你可以对照着看一下。不过要提醒你,图里 TCP 关闭连接的“四次挥手”在抓包里没有出现,这是因为 HTTP/1.1 长连接特性,默认不会立即关闭连接。
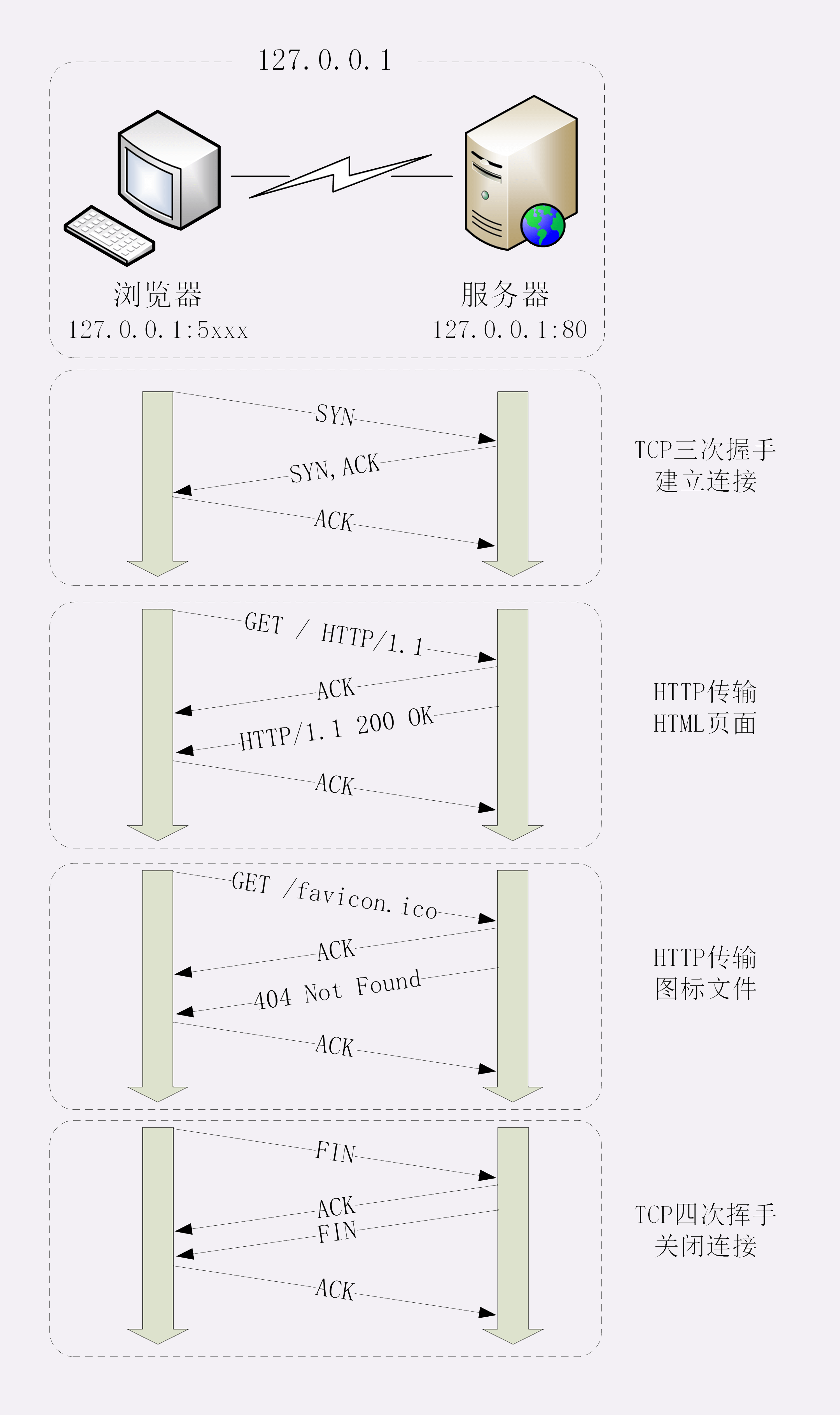
再简要叙述一下这次最简单的浏览器 HTTP 请求过程:
- 浏览器从地址栏的输入中获得服务器的 IP 地址和端口号;
- 浏览器用 TCP 的三次握手与服务器建立连接;
- 浏览器向服务器发送拼好的报文;
- 服务器收到报文后处理请求,同样拼好报文再发给浏览器;
- 浏览器解析报文,渲染输出页面。
使用域名访问 Web 服务器
刚才我们是在浏览器地址栏里直接输入 IP 地址,但绝大多数情况下,我们是不知道服务器 IP 地址的,使用的是域名,那么改用域名后这个过程会有什么不同吗?
还是实际动手试一下吧,把地址栏的输入改成“http://www.Chrono(加微信:642945106 发送“赠送”领取赠送精品课程 发数字“2”获取众筹列表。).com”,重复 Wireshark 抓包过程,你会发现,好像没有什么不同,浏览器上同样显示出了欢迎界面,抓到的包也同样是 11 个:先是三次握手,然后是两次 HTTP 传输。
这里就出现了一个问题:浏览器是如何从网址里知道“www.Chrono(加微信:642945106 发送“赠送”领取赠送精品课程 发数字“2”获取众筹列表。).com”的 IP 地址就是“127.0.0.1”的呢?
还记得我们之前讲过的 DNS 知识吗?浏览器看到了网址里的“www.Chrono(加微信:642945106 发送“赠送”领取赠送精品课程 发数字“2”获取众筹列表。).com”,发现它不是数字形式的 IP 地址,那就肯定是域名了,于是就会发起域名解析动作,通过访问一系列的域名解析服务器,试图把这个域名翻译成 TCP/IP 协议里的 IP 地址。
不过因为域名解析的全过程实在是太复杂了,如果每一个域名都要大费周折地去网上查一下,那我们上网肯定会慢得受不了。
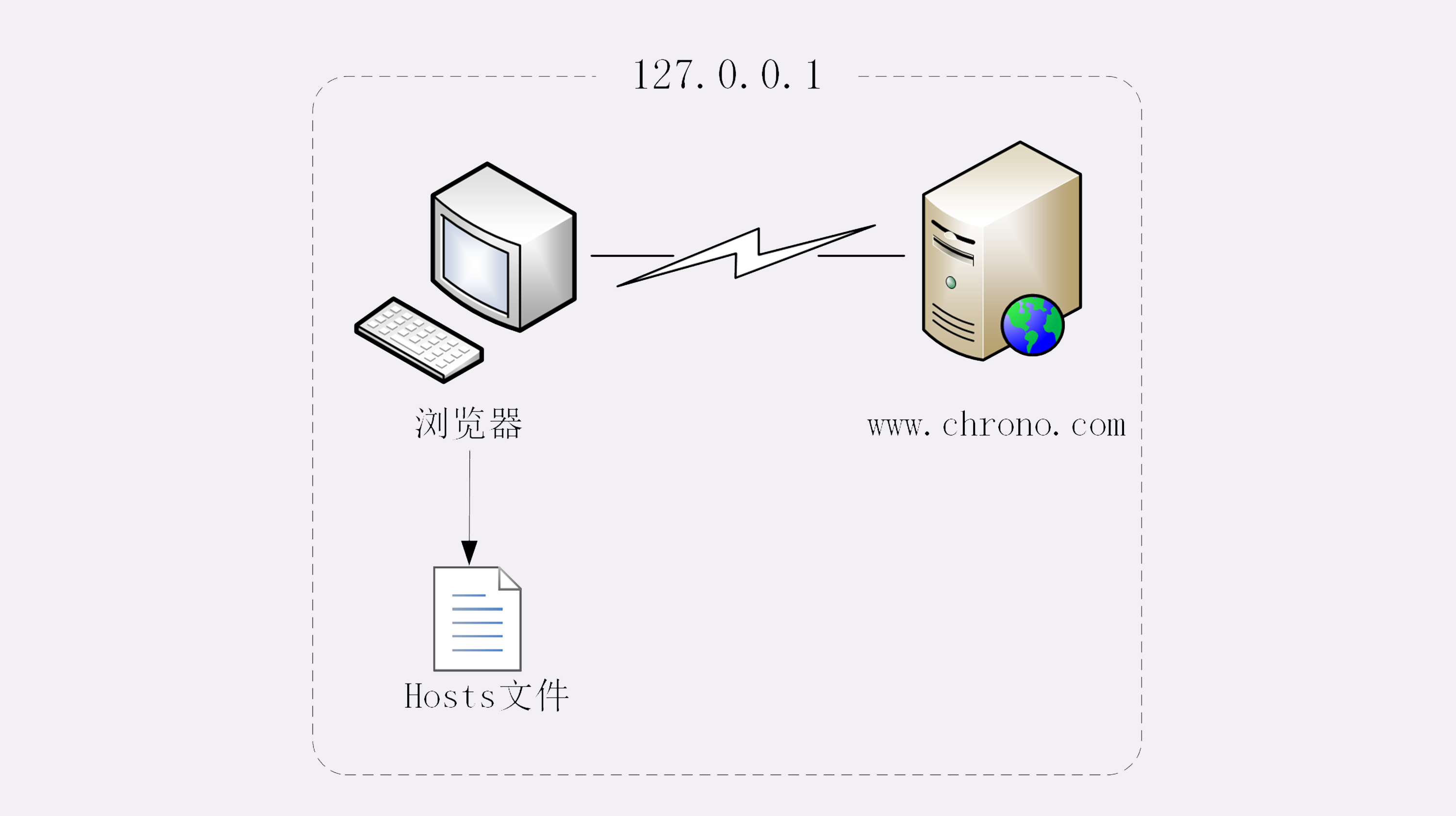
所以,在域名解析的过程中会有多级的缓存,浏览器首先看一下自己的缓存里有没有,如果没有就向操作系统的缓存要,还没有就检查本机域名解析文件 hosts,也就是上一讲中我们修改的“C:\WINDOWS\system32\drivers\etc\hosts”。
刚好,里面有一行映射关系“127.0.0.1 www.Chrono(加微信:642945106 发送“赠送”领取赠送精品课程 发数字“2”获取众筹列表。).com”,于是浏览器就知道了域名对应的 IP 地址,就可以愉快地建立 TCP 连接发送 HTTP 请求了。
我把这个过程也画出了一张图,但省略了 TCP/IP 协议的交互部分,里面的浏览器多出了一个访问 hosts 文件的动作,也就是本机的 DNS 解析。
真实的网络世界
通过上面两个在“最小化”环境里的实验,你是否已经对 HTTP 协议的工作流程有了基本的认识呢?
第一个实验是最简单的场景,只有两个角色:浏览器和服务器,浏览器可以直接用 IP 地址找到服务器,两者直接建立 TCP 连接后发送 HTTP 报文通信。
第二个实验在浏览器和服务器之外增加了一个 DNS 的角色,浏览器不知道服务器的 IP 地址,所以必须要借助 DNS 的域名解析功能得到服务器的 IP 地址,然后才能与服务器通信。
真实的互联网世界要比这两个场景要复杂的多,我利用下面的这张图来做一个详细的说明。
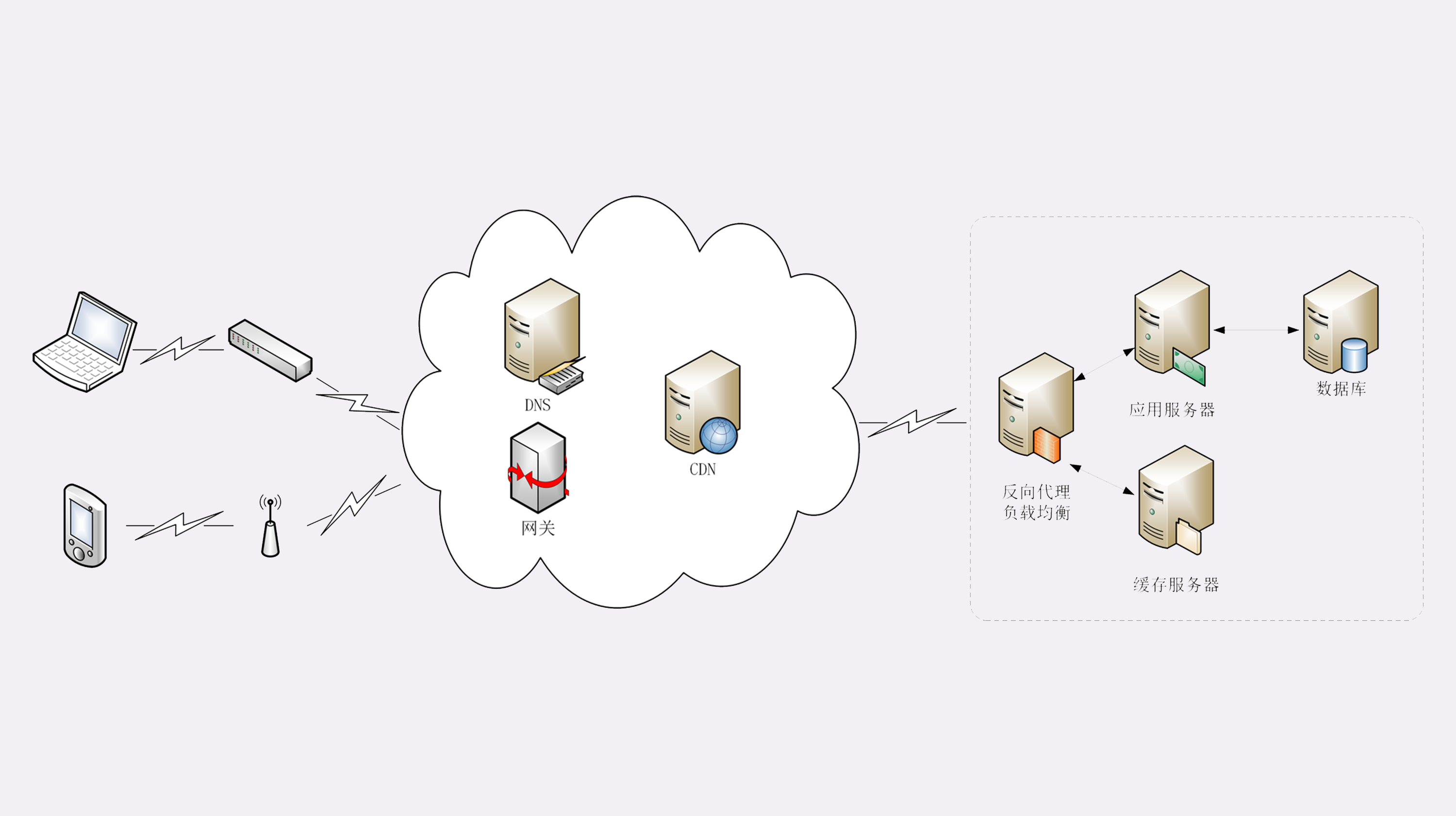
如果你用的是电脑台式机,那么你可能会使用带水晶头的双绞线连上网口,由交换机接入固定网络。如果你用的是手机、平板电脑,那么你可能会通过蜂窝网络、WiFi,由电信基站、无线热点接入移动网络。
接入网络的同时,网络运行商会给你的设备分配一个 IP 地址,这个地址可能是静态分配的,也可能是动态分配的。静态 IP 就始终不变,而动态 IP 可能你下次上网就变了。
假设你要访问的是 Apple 网站,显然你是不知道它的真实 IP 地址的,在浏览器里只能使用域名“www.apple.com”访问,那么接下来要做的必然是域名解析。这就要用 DNS 协议开始从操作系统、本地 DNS、根 DNS、顶级 DNS、权威 DNS 的层层解析,当然这中间有缓存,可能不会费太多时间就能拿到结果。
别忘了互联网上还有另外一个重要的角色 CDN,它也会在 DNS 的解析过程中“插上一脚”。DNS 解析可能会给出 CDN 服务器的 IP 地址,这样你拿到的就会是 CDN 服务器而不是目标网站的实际地址。
因为 CDN 会缓存网站的大部分资源,比如图片、CSS 样式表,所以有的 HTTP 请求就不需要再发到 Apple,CDN 就可以直接响应你的请求,把数据发给你。
由 PHP、Java 等后台服务动态生成的页面属于“动态资源”,CDN 无法缓存,只能从目标网站获取。于是你发出的 HTTP 请求就要开始在互联网上的“漫长跋涉”,经过无数的路由器、网关、代理,最后到达目的地。
目标网站的服务器对外表现的是一个 IP 地址,但为了能够扛住高并发,在内部也是一套复杂的架构。通常在入口是负载均衡设备,例如四层的 LVS 或者七层的 Nginx,在后面是许多的服务器,构成一个更强更稳定的集群。
负载均衡设备会先访问系统里的缓存服务器,通常有 memory 级缓存 Redis 和 disk 级缓存 Varnish,它们的作用与 CDN 类似,不过是工作在内部网络里,把最频繁访问的数据缓存几秒钟或几分钟,减轻后端应用服务器的压力。
如果缓存服务器里也没有,那么负载均衡设备就要把请求转发给应用服务器了。这里就是各种开发框架大显神通的地方了,例如 Java 的 Tomcat/Netty/Jetty,Python 的 Django,还有 PHP、Node.js、Golang 等等。它们又会再访问后面的 MySQL、PostgreSQL、MongoDB 等数据库服务,实现用户登录、商品查询、购物下单、扣款支付等业务操作,然后把执行的结果返回给负载均衡设备,同时也可能给缓存服务器里也放一份。
应用服务器的输出到了负载均衡设备这里,请求的处理就算是完成了,就要按照原路再走回去,还是要经过许多的路由器、网关、代理。如果这个资源允许缓存,那么经过 CDN 的时候它也会做缓存,这样下次同样的请求就不会到达源站了。
最后网站的响应数据回到了你的设备,它可能是 HTML、JSON、图片或者其他格式的数据,需要由浏览器解析处理才能显示出来,如果数据里面还有超链接,指向别的资源,那么就又要重走一遍整个流程,直到所有的资源都下载完。
小结
今天我们在本机的环境里做了两个简单的实验,学习了 HTTP 协议请求 - 应答的全过程,在这里做一个小结。
- HTTP 协议基于底层的 TCP/IP 协议,所以必须要用 IP 地址建立连接;
- 如果不知道 IP 地址,就要用 DNS 协议去解析得到 IP 地址,否则就会连接失败;
- 建立 TCP 连接后会顺序收发数据,请求方和应答方都必须依据 HTTP 规范构建和解析报文;
- 为了减少响应时间,整个过程中的每一个环节都会有缓存,能够实现“短路”操作;
- 虽然现实中的 HTTP 传输过程非常复杂,但理论上仍然可以简化成实验里的“两点”模型。
课下作业
- 你能试着解释一下在浏览器里点击页面链接后发生了哪些事情吗?
- 这一节课里讲的都是正常的请求处理流程,如果是一个不存在的域名,那么浏览器的工作流程会是怎么样的呢?
欢迎你把自己的答案写在留言区,与我和其他同学一起讨论。如果你觉得有所收获,也欢迎把文章分享给你的朋友。


1716143665 拼课微信(20)
 -W.LI-2019-06-14 5浏览器判断是不是ip地址,不是就进行域名解析,依次通过浏览器缓存,系统缓存,host文件,还是没找到的请求DNS服务器获取IP解析(解析失败的浏览器尝试换别的DNS服务器,最终失败的进入错误页面),有可能获取到CDN服务器IP地址,访问CDN时先看是否缓存了,缓存了响应用户,无法缓存,缓存失效或者无缓存,回源到服务器。经过防火墙外网网管路由到nginx接入层。ng缓存中存在的直接放回,不存在的负载到web服务器。web服务器接受到请后处理,路径不存在404。存在的返回结果(服务器中也会有redis,ehcache(堆内外缓存),disk等缓存策略)。原路返回,CDN加入缓存响应用户。展开
-W.LI-2019-06-14 5浏览器判断是不是ip地址,不是就进行域名解析,依次通过浏览器缓存,系统缓存,host文件,还是没找到的请求DNS服务器获取IP解析(解析失败的浏览器尝试换别的DNS服务器,最终失败的进入错误页面),有可能获取到CDN服务器IP地址,访问CDN时先看是否缓存了,缓存了响应用户,无法缓存,缓存失效或者无缓存,回源到服务器。经过防火墙外网网管路由到nginx接入层。ng缓存中存在的直接放回,不存在的负载到web服务器。web服务器接受到请后处理,路径不存在404。存在的返回结果(服务器中也会有redis,ehcache(堆内外缓存),disk等缓存策略)。原路返回,CDN加入缓存响应用户。展开作者回复: 说的非常详细。
 郭凯强2019-06-14 3作业:
郭凯强2019-06-14 3作业:
1. 浏览器判断这个链接是要在当前页面打开还是新开标签页,然后走一遍本文中的访问过程:拿到ip地址和端口号,建立tcp/ip链接,发送请求报文,接收服务器返回并渲染。
2. 先查浏览器缓存,然后是系统缓存->hosts文件->局域网域名服务器->广域网域名服务器->顶级域名服务器->根域名服务器。这个时间通常要很久,最终找不到以后,返回一个报错页面,chrome是ERR_CONNECTION_ABORTED展开作者回复: 回答的比较全面。
这里面还有个长连接的问题,后面会讲,如果连接还是本站就不会有建连过程,直接用已有的连接发请求。- 极客时间2019-06-14 2我有几个小疑问没搞明白,万望老师解答, 在进行DNS解析的时候,操作系统和本地DNS是如何处理的呢?
我的理解是本地系统有可能有缓存,DNS解析前先查看本地有没有缓存,如果没有缓存,再进行本地DNS解析,本地DNS解析就是查找系统里面的hosts文件的对应关系。不知道这里理解的对不对。
还有一个疑问。
什么是权威DNS呢,我一般是在万网购买域名,然后用A记录解析到我的服务器,这个A记录提交到哪里保存了呢,这里的万网扮演的是什么角色呢?它和权威DNS有关系吗?
上次我提到了一个问题,就是域名和ip的对应关系,没接触这个课程以前,我的理解是一个域名只能解析到一个ip地址,但是一个ip地址可以绑定多个域名,就像一个人只有一个身份证号码,但是可以有多个名字,但是我在用ping命令 ping‘ baidu.com’ 时,发现 可以返回不同的ip,结合本课程前面的文章,我理解是百度自己的服务器本质是一台DNS服务器,用DNS做了负载均衡,当我访问baidu.com时,域名解析过程中,有一个环节是到达了百度的DNS服务器,然后DNS服务器根据负载均衡操作,再将我的请求转发给目标服务器。不知道理解的对不对,或者哪里有偏差。展开作者回复: 本地dns你的理解是正确的。
万网是个域名注册的代理机构,最终域名还是要由dns系统来解析。
百度的理解基本正确,在真正服务器前面是dns负载均衡。 - Geek_Wison2019-06-15 1老师,你好。我记得以前在教材里面,客户端在与服务器端建立TCP连接的时候,会发送一个SYN置为1的TCP报文段。但是在wireshark里面我看到的第一条TCP报文段怎么SYN=0?
作者回复: 这个是wireshark重新修改了起始值,方便查看,我觉得这个不用太在意,毕竟我们研究的是http这样的应用层协议。
- 极客时间2019-06-14 1老师 我有个疑问,第四个包到第六个包,为什么又进行了一次tcp连接呢,而且这个端口号是52086,这个是浏览器的特性吗,仔细比对文章发现这个问题啊展开
作者回复: 因为http/1连接传输效率低,所以浏览器一般会对同一个域名发起多个连接提高效率,这个52086就是开的第二个连接,但在抓包中只是打开了,还没有传输。
到后面讲长连接的时候你就会明白了。  业余草2019-06-14 1老师很有责任感!期待后面的内容!展开
业余草2019-06-14 1老师很有责任感!期待后面的内容!展开作者回复: thanks.
 盐森2019-06-15老师,文中在讲解请求Apple网站的例子时,说到:
盐森2019-06-15老师,文中在讲解请求Apple网站的例子时,说到:
"这就要用 DNS 协议开始从操作系统、本地 DNS、根 DNS、顶级 DNS、权威 DNS 的层层解析"。
而我看前几天的内容总结的是,请求会在进入网络后先到达非权威DNS、权威DNS、顶级…、最后才是到达根DNS去解析,那么本文怎么是先从根DNS开始的呢?展开作者回复: 今天的这讲是简化的说法,没有那么精确,完整的dns解析以第6讲为准。
另外,dns解析通常是先到非权威dns,然后是根dns->顶级dns->权威dns,你可以再回顾一下。- Brian Wan...2019-06-15不过为什么要建立一个52086呢... 完全想不明白它的意义展开
作者回复: 并发多个连接,提高数据传输效率,第17讲会说。
- Geek_54edc...2019-06-14感谢罗老师的答疑解惑,学习了展开
作者回复: 不客气,有问题随时提。
- 古夜2019-06-14我又在断网情况下重试了一次,
还是两次三次握手,
但是有了图标请求以及404,我之前试的时候有写源ip和目标ip过滤,但我觉得这个对图标请求没影响啊,都是在本地的,怎么会没抓到呢?展开作者回复: 这里回复没办法贴图,看不到抓包不好界定,有更多的疑问可以去GitHub上提issue。
另外,你这种反复实验的精神值得表扬,多在实验环境里折腾吧,弄懂了为止。 - 古夜2019-06-14并且我这里没有你说的图标传输啊展开
- 古夜2019-06-14关于抓包分析那块,讲真,我的情况是这样的,我反复实验了几次:
环境: chrome,win10,其他都和老师一样的
步骤:访问127.0.0.1
结果:抓包结果显示我进行了两趟三次握手(1),之后是一次http请求,然后服务器返回一个ack包(2),然后服务器返回html文档,
然后浏览器给服务器发了一个ack包(3)
分析:
1,不明白是为什么,为什么要两次三次握手????
2,是服务器告诉浏览器,我接受到你的请求的意思吗?
3,是浏览器告诉服务器,我收到你发的数据了的意思吗?
不知道我说的对不对,麻烦老师解惑😬展开作者回复: 看一下握手的端口号,应该是建立了两个连接。
2和3,都是tcp的ack,就是tcp的回包确认,你理解的是对的。 - Brian Wan...2019-06-14编号 4-6 的包(图中没有,但是自己能抓到、给的 wireshark 文件中也有)是做什么用的呢?
作者回复: 这个是浏览器与服务器建立的另一个连接,用的端口号是52086,但并没有传输数据,实际收发用的是52085。
 Simon2019-06-14老师, 请问wireshark的tcp.stream eq 0是什么意思呢?展开
Simon2019-06-14老师, 请问wireshark的tcp.stream eq 0是什么意思呢?展开作者回复: 过滤的规则,选择第0号tcp流。
 Amark2019-06-14老师能不能详细讲讲,集线器,交换机,网关,以及这个传输过程,我有一个问题,如果在北京访问一台在深圳的服务器,这个过程有没有可能经过武汉某家大型互联网公司的局域网,对网络不要了解
Amark2019-06-14老师能不能详细讲讲,集线器,交换机,网关,以及这个传输过程,我有一个问题,如果在北京访问一台在深圳的服务器,这个过程有没有可能经过武汉某家大型互联网公司的局域网,对网络不要了解作者回复: 这个太底层了,建议看一下极客时间里另一个讲网络协议的专栏。
后面的问题,看网络路由选择了,如果刚好走到那里也是有可能的。- Geek_54edc...2019-06-14域名不存在,dns解析失败,tcp连接建立失败展开
作者回复: 域名解析失败就不会发起tcp建连。
- Geek_54edc...2019-06-14点击链接,就是一次http过程,只不过不用再建立tcp连接了,因为http1.1的长连接特性。
作者回复: 如果是其他的网站,也就是“外链”,就必须建立新的连接。
- Geek_d4dee...2019-06-14浏览器接受到服务器返回的html 后 html 用到的css js 图片或者视频链接是什么时候再次发送请求到服务器的呢?是一边接受一边加载这些资源还是完全接收后再根据页面中出现的顺序有序加载?
作者回复: 收到html后浏览器会解析,发现这些链接后就再发请求。具体的加载次序是浏览器自己决定的,排版引擎比较复杂,通常都是边接收边加载。
 红军2019-06-14请教个问题,LVS是工作在IP层的吧,为什么是四层?🙏展开
红军2019-06-14请教个问题,LVS是工作在IP层的吧,为什么是四层?🙏展开作者回复: 对,我一时说顺嘴了,sorry,感谢指正。
 xing.org1...2019-06-14老师请问,输入一个地址按下回车,浏览器把页面请求发送出去,服务器响应后返回html,浏览器在接受到html后就会立即发生四次挥手吗?还是说会延迟一会,遇到link、img等这些带外链的标签后继续去发送请求(省去dns解析和ip寻址?),最终确定html中没有外链请求了才会断开链接呢?展开
xing.org1...2019-06-14老师请问,输入一个地址按下回车,浏览器把页面请求发送出去,服务器响应后返回html,浏览器在接受到html后就会立即发生四次挥手吗?还是说会延迟一会,遇到link、img等这些带外链的标签后继续去发送请求(省去dns解析和ip寻址?),最终确定html中没有外链请求了才会断开链接呢?展开作者回复: 现在的http都是长连接,不会立即断开连接,尽量复用,因为握手和挥手的成本太高了。










