22 | 非阻塞I/O:提升性能的加速器





讲述:冯永吉
时长10:26大小9.56M
你好,我是盛延敏,这里是网络编程实战第 22 讲,欢迎回来。
在性能篇的前两讲中,我分别介绍了 select 和 poll 两种不同的 I/O 多路复用技术。在接下来的这一讲中,我将带大家进入非阻塞 I/O 模式的世界。事实上,非阻塞 I/O 配合 I/O 多路复用,是高性能网络编程中的常见技术。
阻塞 VS 非阻塞
当应用程序调用阻塞 I/O 完成某个操作时,应用程序会被挂起,等待内核完成操作,感觉上应用程序像是被“阻塞”了一样。实际上,内核所做的事情是将 CPU 时间切换给其他有需要的进程,网络应用程序在这种情况下就会得不到 CPU 时间做该做的事情。
非阻塞 I/O 则不然,当应用程序调用非阻塞 I/O 完成某个操作时,内核立即返回,不会把 CPU 时间切换给其他进程,应用程序在返回后,可以得到足够的 CPU 时间继续完成其他事情。
如果拿去书店买书举例子,阻塞 I/O 对应什么场景呢? 你去了书店,告诉老板(内核)你想要某本书,然后你就一直在那里等着,直到书店老板翻箱倒柜找到你想要的书,有可能还要帮你联系全城其它分店。注意,这个过程中你一直滞留在书店等待老板的回复,好像在书店老板这里"阻塞"住了。
那么非阻塞 I/O 呢?你去了书店,问老板有没你心仪的那本书,老板查了下电脑,告诉你没有,你就悻悻离开了。一周以后,你又来这个书店,再问这个老板,老板一查,有了,于是你买了这本书。注意,这个过程中,你没有被阻塞,而是在不断轮询。
但轮询的效率太低了,于是你向老板提议:“老板,到货给我打电话吧,我再来付钱取书。”这就是前面讲到的 I/O 多路复用。
再进一步,你连去书店取书也想省了,得了,让老板代劳吧,你留下地址,付了书费,让老板到货时寄给你,你直接在家里拿到就可以看了。这就是我们将会在第 30 讲中讲到的异步 I/O。
这几个 I/O 模型,再加上进程、线程模型,构成了整个网络编程的知识核心。
按照使用场景,非阻塞 I/O 可以被用到读操作、写操作、接收连接操作和发起连接操作上。接下来,我们对它们一一解读。
非阻塞 I/O
读操作
如果套接字对应的接收缓冲区没有数据可读,在非阻塞情况下 read 调用会立即返回,一般返回 EWOULDBLOCK 或 EAGAIN 出错信息。在这种情况下,出错信息是需要小心处理,比如后面再次调用 read 操作,而不是直接作为错误直接返回。这就好像去书店买书没买到离开一样,需要不断进行又一次轮询处理。
写操作
不知道你有没有注意到,在阻塞 I/O 情况下,write 函数返回的字节数,和输入的参数总是一样的。如果返回值总是和输入的数据大小一样,write 等写入函数还需要定义返回值吗?我不知道你是不是和我一样,刚接触到这一部分知识的时候有这种困惑。
这里就要引出我们所说的非阻塞 I/O。在非阻塞 I/O 的情况下,如果套接字的发送缓冲区已达到了极限,不能容纳更多的字节,那么操作系统内核会尽最大可能从应用程序拷贝数据到发送缓冲区中,并立即从 write 等函数调用中返回。可想而知,在拷贝动作发生的瞬间,有可能一个字符也没拷贝,有可能所有请求字符都被拷贝完成,那么这个时候就需要返回一个数值,告诉应用程序到底有多少数据被成功拷贝到了发送缓冲区中,应用程序需要再次调用 write 函数,以输出未完成拷贝的字节。
write 等函数是可以同时作用到阻塞 I/O 和非阻塞 I/O 上的,为了复用一个函数,处理非阻塞和阻塞 I/O 多种情况,设计出了写入返回值,并用这个返回值表示实际写入的数据大小。
也就是说,非阻塞 I/O 和阻塞 I/O 处理的方式是不一样的。
非阻塞 I/O 需要这样:拷贝→返回→再拷贝→再返回。
而阻塞 I/O 需要这样:拷贝→直到所有数据拷贝至发送缓冲区完成→返回。
不过在实战中,你可以不用区别阻塞和非阻塞 I/O,使用循环的方式来写入数据就好了。只不过在阻塞 I/O 的情况下,循环只执行一次就结束了。
我在前面的章节中已经介绍了类似的方案,你可以在文稿里看到 writen 函数的实现。
下面我通过一张表来总结一下 read 和 write 在阻塞模式和非阻塞模式下的不同行为特性:
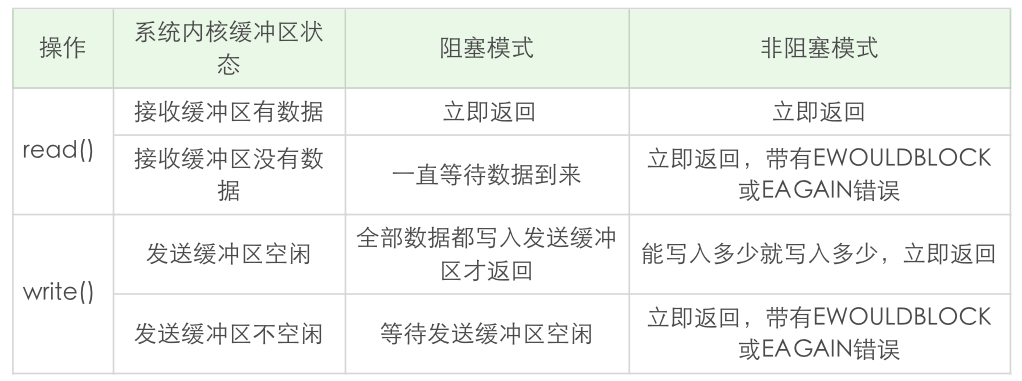
关于 read 和 write 还有几个结论,你需要把握住:
- read 总是在接收缓冲区有数据时就立即返回,不是等到应用程序给定的数据充满才返回。当接收缓冲区为空时,阻塞模式会等待,非阻塞模式立即返回 -1,并有 EWOULDBLOCK 或 EAGAIN 错误。
- 和 read 不同,阻塞模式下,write 只有在发送缓冲区足以容纳应用程序的输出字节时才返回;而非阻塞模式下,则是能写入多少就写入多少,并返回实际写入的字节数。
- 阻塞模式下的 write 有个特例, 就是对方主动关闭了套接字,这个时候 write 调用会立即返回,并通过返回值告诉应用程序实际写入的字节数,如果再次对这样的套接字进行 write 操作,就会返回失败。失败是通过返回值 -1 来通知到应用程序的。
accept
当 accept 和 I/O 多路复用 select、poll 等一起配合使用时,如果在监听套接字上触发事件,说明有连接建立完成,此时调用 accept 肯定可以返回已连接套接字。这样看来,似乎把监听套接字设置为非阻塞,没有任何好处。
为了说明这个问题,我们构建一个客户端程序,其中最关键的是,一旦连接建立,设置 SO_LINGER 套接字选项,把 l_onoff 标志设置为 1,把 l_linger 时间设置为 0。这样,连接被关闭时,TCP 套接字上将会发送一个 RST。
服务器端使用 select I/O 多路复用,不过,监听套接字仍然是 blocking 的。如果监听套接字上有事件发生,休眠 5 秒,以便模拟高并发场景下的情形。
这里的休眠时间非常关键,这样,在监听套接字上有可读事件发生时,并没有马上调用 accept。由于客户端发生了 RST 分节,该连接被接收端内核从自己的已完成队列中删除了,此时再调用 accept,由于没有已完成连接(假设没有其他已完成连接),accept 一直阻塞,更为严重的是,该线程再也没有机会对其他 I/O 事件进行分发,相当于该服务器无法对新连接和其他 I/O 进行服务。
如果我们将监听套接字设为非阻塞,上述的情形就不会再发生。只不过对于 accept 的返回值,需要正确地处理各种看似异常的错误,例如忽略 EWOULDBLOCK、EAGAIN 等。
这个例子给我们的启发是,一定要将监听套接字设置为非阻塞的,尽管这里休眠时间 5 秒有点夸张,但是在极端情况下处理不当的服务器程序是有可能碰到文稿中例子所阐述的情况,为了让服务器程序在极端情况下工作正常,这点工作还是非常值得的。
connect
在非阻塞 TCP 套接字上调用 connect 函数,会立即返回一个 EINPROGRESS 错误。TCP 三次握手会正常进行,应用程序可以继续做其他初始化的事情。当该连接建立成功或者失败时,通过 I/O 多路复用 select、poll 等可以进行连接的状态检测。
非阻塞 I/O + select 多路复用
文稿中给出了一个非阻塞 I/O 搭配 select 多路复用的例子。
第 93 行,调用 fcntl 将监听套接字设置为非阻塞。
第 121 行调用 select 进行 I/O 事件分发处理。
131-142 行在处理新的连接套接字,注意这里也把连接套接字设置为非阻塞的。
151-156 行在处理连接套接字上的 I/O 读写事件,这里我们抽象了一个 Buffer 对象,Buffer 对象使用了 readIndex 和 writeIndex 分别表示当前缓冲的读写位置。
实验
启动该服务器:
使用多个 telnet 客户端连接该服务器,可以验证交互正常。
总结
非阻塞 I/O 可以使用在 read、write、accept、connect 等多种不同的场景,在非阻塞 I/O 下,使用轮询的方式引起 CPU 占用率高,所以一般将非阻塞 I/O 和 I/O 多路复用技术 select、poll 等搭配使用,在非阻塞 I/O 事件发生时,再调用对应事件的处理函数。这种方式,极大地提高了程序的健壮性和稳定性,是 Linux 下高性能网络编程的首选。
思考题
给大家布置两道思考题:
第一道,程序中第 133 行这个判断说明了什么?如果要改进的话,你有什么想法?
第二道,你可以仔细阅读一下数据读写部分 Buffer 的代码,你觉得用一个 Buffer 对象,而不是两个的目的是什么?
欢迎在评论区写下你的思考,我会和你一起交流,也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。

精选留言(10)
 MoonGod2019-09-27感觉这篇的解释和前面的比起来太不细致了…很多地方都没说明。老师能不能多一些说明啊
MoonGod2019-09-27感觉这篇的解释和前面的比起来太不细致了…很多地方都没说明。老师能不能多一些说明啊作者回复: 我在代码里多加一些注释,可以看最新的代码
https://github.com/froghui/yolanda 2 石将从2019-09-28老师代码能不能写多点注释呀?基础差的同学看得费劲展开
石将从2019-09-28老师代码能不能写多点注释呀?基础差的同学看得费劲展开作者回复: 好的,我在github上的提交多加一些注释。
https://github.com/froghui/yolanda 1 1 沉淀的梦想2019-09-30老师代码中进行rot13_char编码的目的是啥?展开
沉淀的梦想2019-09-30老师代码中进行rot13_char编码的目的是啥?展开- 沉淀的梦想2019-09-30老师那个accept阻塞的实验,在我电脑(linux-4.18.0,ubuntu18.10)上的行为有点不太一样,无论是把listen_fd设置为阻塞还是非阻塞,sleep 5s还是10s或者更长,行为总是:accept成功获取到客户端连接,然后读取到客户端的RST展开
- 沉淀的梦想2019-09-29文中说“对方主动关闭套接字,阻塞write调用会立即返回实际字节数,如果再次write,则返回失败”,这是的“关闭”只指两个方向关闭吗?如果对方只是半关闭的话,理论上本机还是可以继续write的吧
 刘立伟2019-09-29ubuntu18.04环境下编译整个工程失败.提示如下
刘立伟2019-09-29ubuntu18.04环境下编译整个工程失败.提示如下
CMakeFiles/aio01.dir/aio01.c.o: In function `main':
aio01.c:(.text+0x19b): undefined reference to `aio_write'
aio01.c:(.text+0x1f4): undefined reference to `aio_error'
aio01.c:(.text+0x208): undefined reference to `aio_error'
aio01.c:(.text+0x21d): undefined reference to `aio_return'
aio01.c:(.text+0x329): undefined reference to `aio_read'
aio01.c:(.text+0x379): undefined reference to `aio_error'
aio01.c:(.text+0x38d): undefined reference to `aio_return'
collect2: error: ld returned 1 exit status
chap-30/CMakeFiles/aio01.dir/build.make:95: recipe for target 'bin/aio01' failed
需要在在chapter-30 下的CMakeList.txt 中的target_link_libraries 增加 rt展开 yusuf2019-09-291、133行判断是否超过了文件描述符的最大值,如果超过了,就会报错。可以考虑使用动态分配的方式,但如果超过了1024的话,使用上一节中的poll来处理会更好些
yusuf2019-09-291、133行判断是否超过了文件描述符的最大值,如果超过了,就会报错。可以考虑使用动态分配的方式,但如果超过了1024的话,使用上一节中的poll来处理会更好些
2、认为是考虑到对同一个fd的同一缓冲区进行读写操作,只用一个Buffer对象足够了展开- 石将从2019-09-28没有注释,看onSocketWrite和onSocketRead函数很费劲
作者回复: 其实还是蛮简单的,稍微解释一下:
onSocketRead是通过套接字读取数据,数据存放在Buffer对象里,Buffer对象通过了writeIndex记录当前数
据区可写的位置;
onSocketWrite通过套接字写数据,数据来源于Buffer缓冲对象,Buffer缓冲对象的readIndex记录了当前缓冲区读的位置。  刘丹2019-09-27感觉 readable 这个标记的处理有点小问题,没太考虑多个 \n 的情况
刘丹2019-09-27感觉 readable 这个标记的处理有点小问题,没太考虑多个 \n 的情况作者回复: 如果有多个\n,这里也认为客户端结束了,只不过\n会发送给客户端。
可以加一个处理,如果读到\n,就不要再继续读下去了。- 程序水果宝2019-09-27应该把函数tcp_nonblocking_server_listen(SERV_PORT)的实现代码也给出来的,不然新手可能不知道怎么select 就变成了非阻塞了展开
作者回复: 代码都在:https://github.com/froghui/yolanda
这里贴一段:
int listenfd;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
fcntl(listenfd, F_SETFL, O_NONBLOCK); 1





